Welcome to our collection of articles on the topic of Integrated Deployment, where we focus on solving the challenges around productionizing data science. So far, in this collection we have introduced the topic of Integrated Deployment, discussed the topics of Continuous Deployment and Automated Machine Learning, and presented the AutoML Verified Component.
In today’s article we would like to look more closely at how Verified Components are used in Integrated Deployment based on the example of our AutoML component. This article is designed for the data scientist, showing how to build an application a business user will be able to use without needing to know how to use KNIME Software.
In particular we will examine how the AutoML component was built into a workflow based on the principles of Guided Analytics and how - in combination with the KNIME WebPortal - business users can be guided through the autoML process, enabling them to control it via their web browser and a user friendly interface. This is where the real potential of autoML lies: allowing the business user to concentrate fully on providing their expert input and not worry about the complexity of the underlying processes.
Guided Analytics: building an interactive interface for the business user
This is what Guided Analytics and KNIME WebPortal are all about: smoothly guiding the user through a sequence of interactive views, exposing only those settings that are really needed and hiding unnecessary complexity. Guided Analytics can be easily applied to any KNIME workflow, and of course to our AutoML component, too.
Building such an interactive interface can be done in a myriad of variants, but let’s assume instead a very simple guided analytics autoML example. In our example, we have the following sequence of user interactions:
- Data Upload: the user provides the data in a simple CSV file.
- AutoML Settings: a few controls for the user to decide what should be automatically trained.
- Results and Best Model Download: a summary of the output of the AutoML process with an option to quickly export the model.
- Deployment of the Model: the workflow produced by the AutoML component can be deployed on KNIME Server if the user decided to do so.
How do you build this sequence of four interactive views controlling the AutoML component in a KNIME workflow? Well, with more components! One component for each interactive view. Those additional components contain Widget and JavaScript nodes which are rendered as different visual elements in each component’s Composite View.
The data scientist can set up just the right amount of interaction for anyone else in the company directly from KNIME Analytics Platform. The resulting example KNIME workflow (Fig. 1), AutoML Component via Interactive Views, which we created, is publicly available on KNIME Hub and can be downloaded and tested with KNIME Analytics Platform.
Note:Before Integrated Deployment we used the term Guided Automation to refer to Guided Analytics in an AutoML application. This term is still relevant but also linked to a much more complex workflow, which we don't cover here, yet.
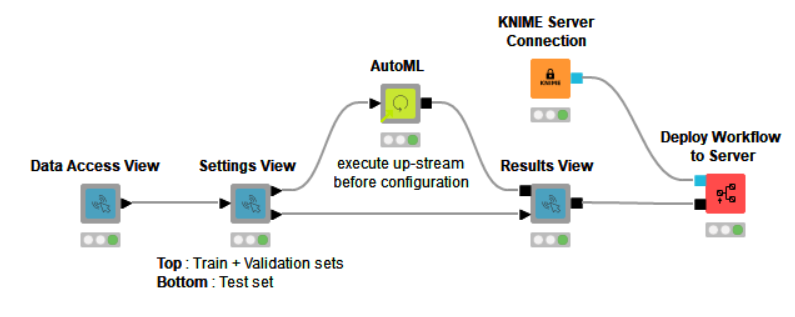
Figure 1: The Guided Analytics Workflow for the AutoML Component.
Our Guided Analytics workflow for the AutoML component is a simple example that shows how the AutoML process can be controlled via interactive views. The workflow produces four interactive views which result in a Guided Analytics application.
If the workflow is downloaded from the KNIME Hub and deployed to a KNIME Server, you can use it to automatically to train machine learning models and you do not need to know KNIME to do so. It can be executed directly via a web browser via KNIME WebPortal (Fig. 2).
Note: The workflow can also be run on the open source KNIME Analytics Platform with example datasets and without the deployment aspect. (Right click any component and click "Open Interactive View".)

Figure 2: The Guided Analytics Application using the AutoML Component. The animation shows the interactions of the user accessing the KNIME WebPortal from a web browser and running the application from data access to deployment of the final model. The KNIME workflow behind the application is totally hidden from the eye of the user, operating the guided analytics application step bystep.
How does the guided analytics application work?
Let’s dive now a bit more into how the guided analytics application works (Fig. 3). The first Custom View “Data Access View” (in orange - Fig. 3) generates an interface to load the data into the KNIME workflow (in yellow - Fig. 3). In KNIME this can be done in countless ways depending on your organization setup.
In our example the default behaviour is to load data from a simple SQL database, if credentials are provided. The data is cached in a CSV file updated each time the workflow is executed. If the user manually uploads a new CSV file this would replace the SQL query.
Once a dataset is provided, the user moves to the second Custom View “AutoML Setting ” (in light green - Fig. 3). At this point the KNIME WebPortal business user can interact, totally unaware of the connected Widget nodes, and define the target column, filter the input feature column, add which machine learning algorithm should be applied as well as select the performance metric to be used. Once the input from the WebPortal user is provided, the AutoML Component executes on KNIME Server using all the necessary computational power.
The last Custom View “Results and Model Download” (in red - Fig. 3) shows the best model, which is automatically selected based on the performance metric provided by the business user. It also provides information about performance of the other generated models listed in a bar chart.
The best model deployment workflow can now be downloaded and opened in KNIME Analytics Platform and/or deployed to KNIME Server. In figure 3, you can see the full KNIME WebPortal User Journey (in blue) which the guided analytics application guides the business user through. At any point the business user can go back and try something different to see how the results change, no need to code R or Python or drag and drop a single KNIME node: the business user simply interacts with the views moving through the process using the “Next” and “Back” buttons.
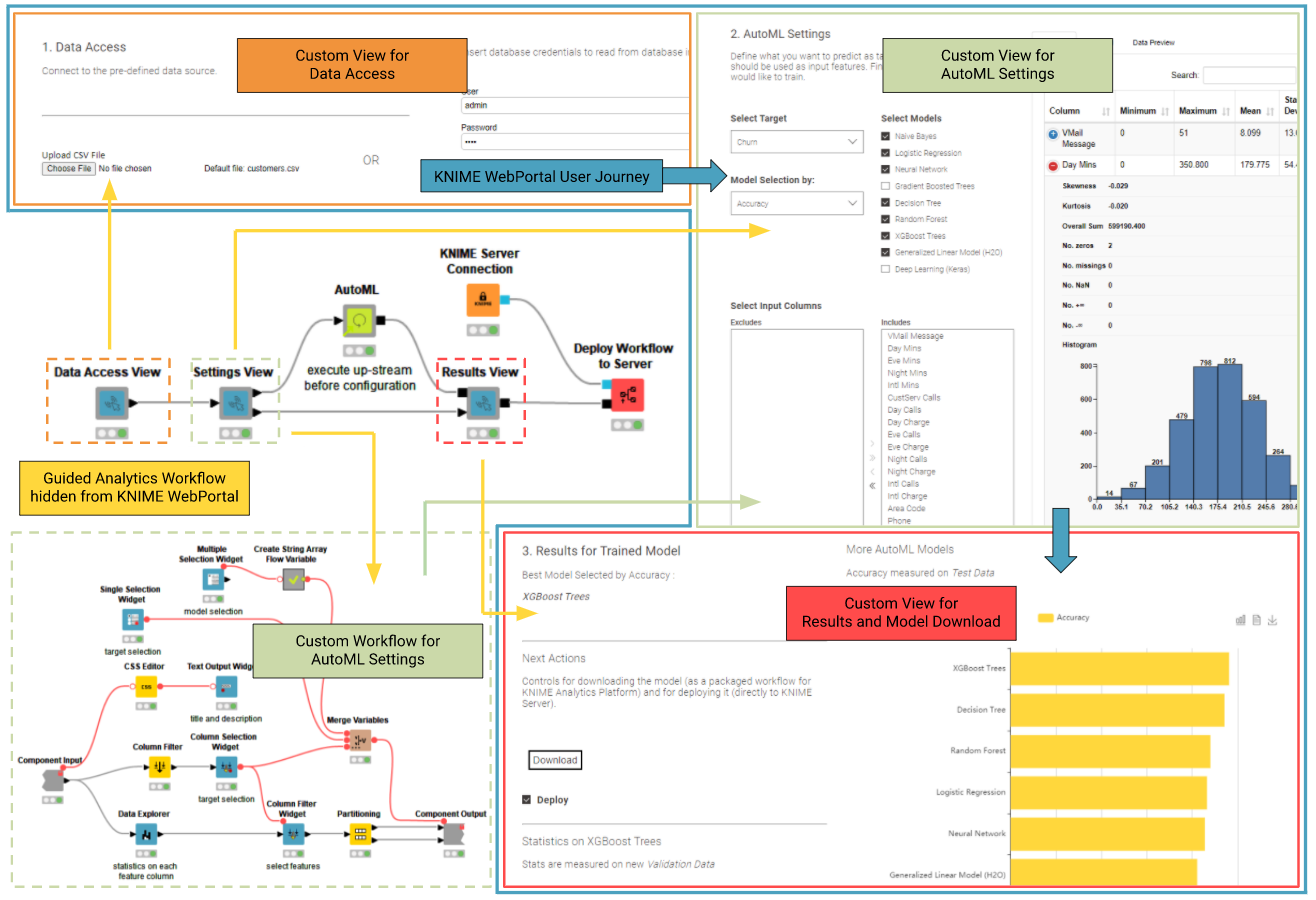
Figure 3: The diagram linking the Workflow behind the UI of the Guided Analytics application. The workflow offers three components which in sequence produce the three views of the Guided Analytics application: “Data Access” (in orange), then “AutoML Settings” (in light green), and finally “Results” (in red). In between the “Settings View” and “Results View” components the AutoML (Verified Component) takes care of training the desired models. Additionally the inside of the “Settings View” is shown in the bottom right corner, showing how easily such an interface can be customized by a data scientist.
Data partitioning to train and validate
Another important aspect of the workflow is how the data is partitioned. The AutoML component itself partitions the data into the train and validation set. On the outside however the “Settings View” Component creates an additional test set partition. The final “Results View” Component scores the output model via a Workflow Executor node and measures its performance again and displays it to the business user on the KNIME WebPortal. This practice (Fig. 4) is quite powerful as the user can witness right away if there is a huge drop between the performance reported by the AutoML Component on the validation set and the performance reported by this final evaluation on the test set. If there is a big difference it might mean the model is somehow overfitting the validation partition.
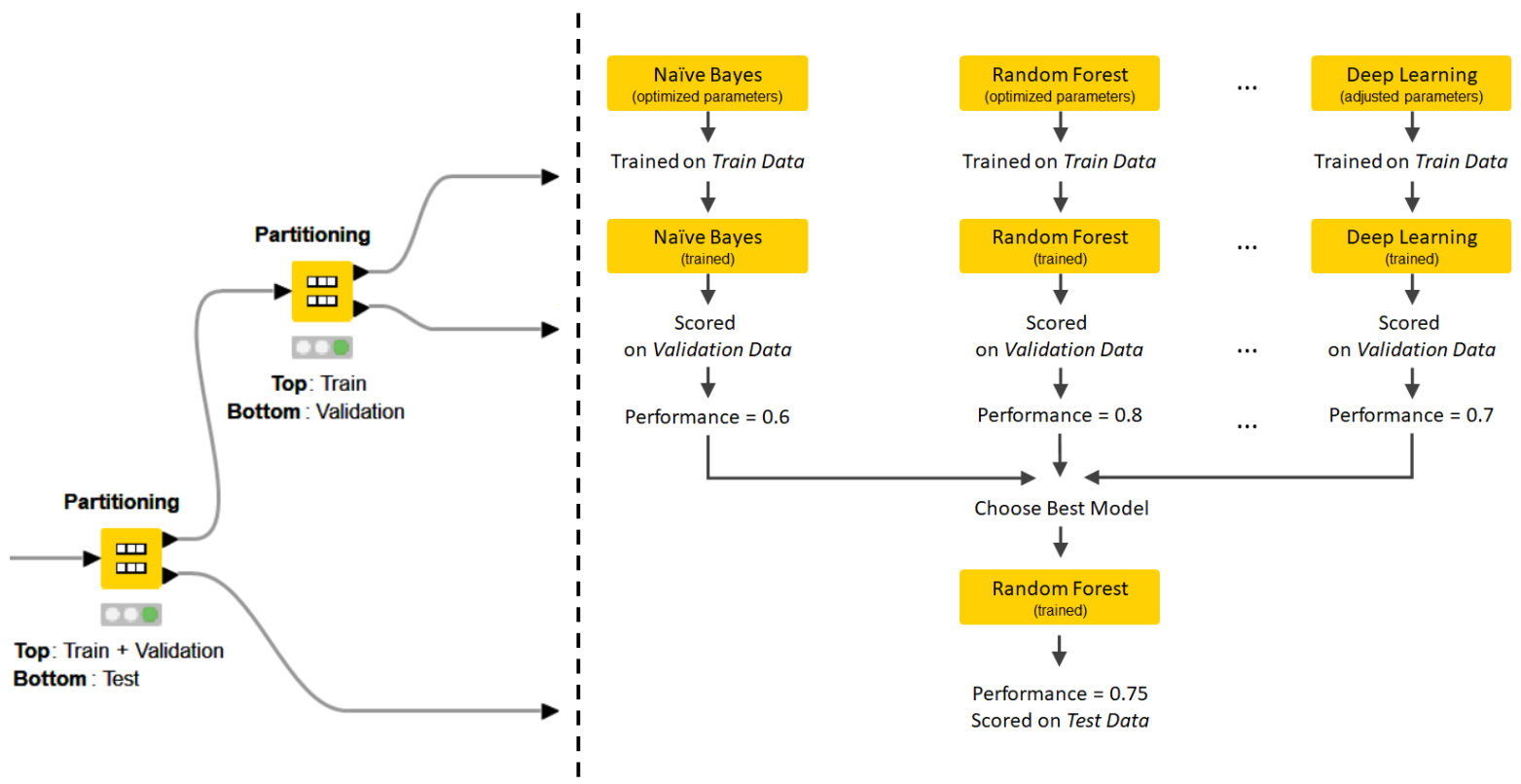
Figure 4: The diagram explaining how the data partitioning takes place in the AutoML process. That data is partitioned first by the workflow and only afterwards by the AutoML Component. This leads to three data partitions: the Train Data to train the models and with optimized parameters via cross validation; the Validation Data to evaluate all models and compare them; the Test Data to measure the performance of the best model before its optional deployment.
Wrapping up
In this article, we have explained how to build a guided analytics application around the AutoML Component to give the business user an easy process to automatically train machine learning models. Our example was a simple example. For a more detailed blueprint, check the workflow Guided Automation also available on the KNIME Hub. The Guided Automation workflow group additionally covers: Feature Engineering, Feature Selection, Customizable Parameter Optimization, Distributed Execution and a bit of Machine Learning Interpretability / XAI.
Stay tuned for more articles on Integrated Deployment and all the new data science practices this extension enables!
The Integrated Deployment KNIME Blog Articles
Explore the collection of articles on the topic of Integrated Deployment.