KNIME Analytics Platform
Open and free. Coding optional. Always extensible.

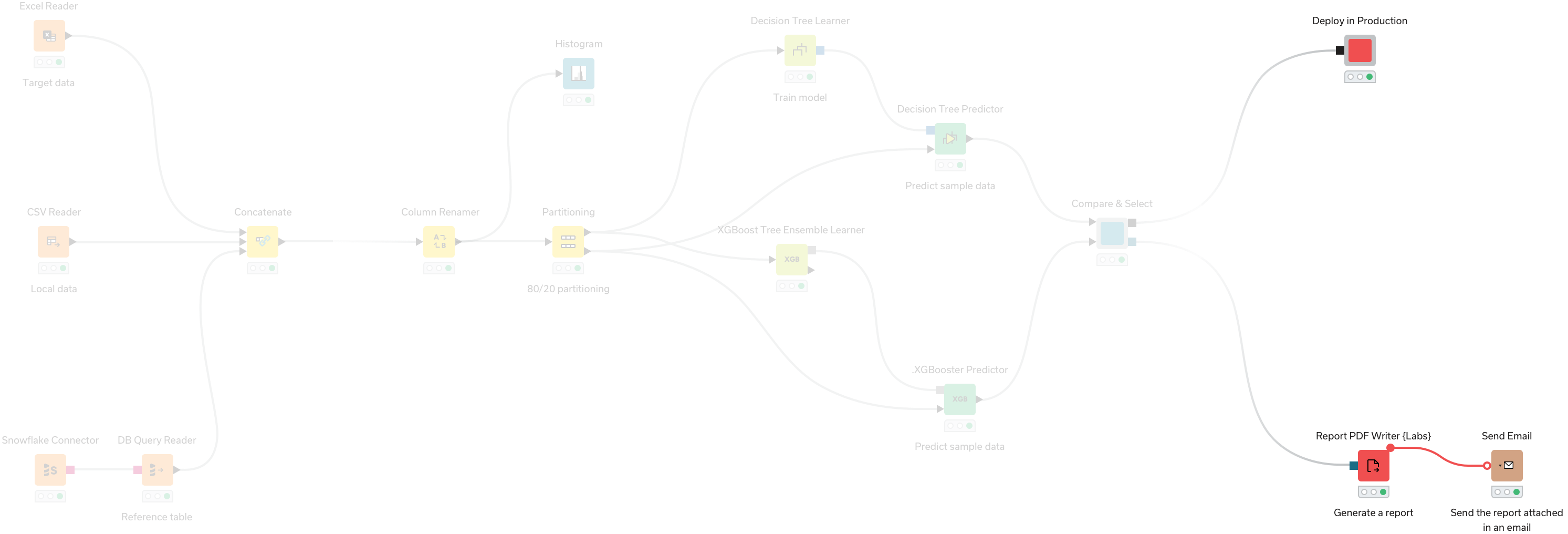
The KNIME Analytics Platform
KNIME Analytics Platform is free and open source, which ensures users remain on the bleeding edge of data science, 300+ connectors to data sources, and integrations to all popular machine learning libraries.
300+Connectors to data sources
Access, blend, and transform data from any source
- Access data from any data source - your laptop, an application or a data warehouse
- Easily blend data of any size and any type - all file formats supported
- Aggregate, sort, filter, and join data on your device, in-database, or in distributed big data environments
Visualize and analyze
- Explore data with interactive charts and visualizations
- Automate spreadsheets or other manual, repetitive data tasks
- Create visualizations automatically with a genAI assistant
- Choose from a complete range of analytic techniques, with access to all popular ML libraries including LLMs
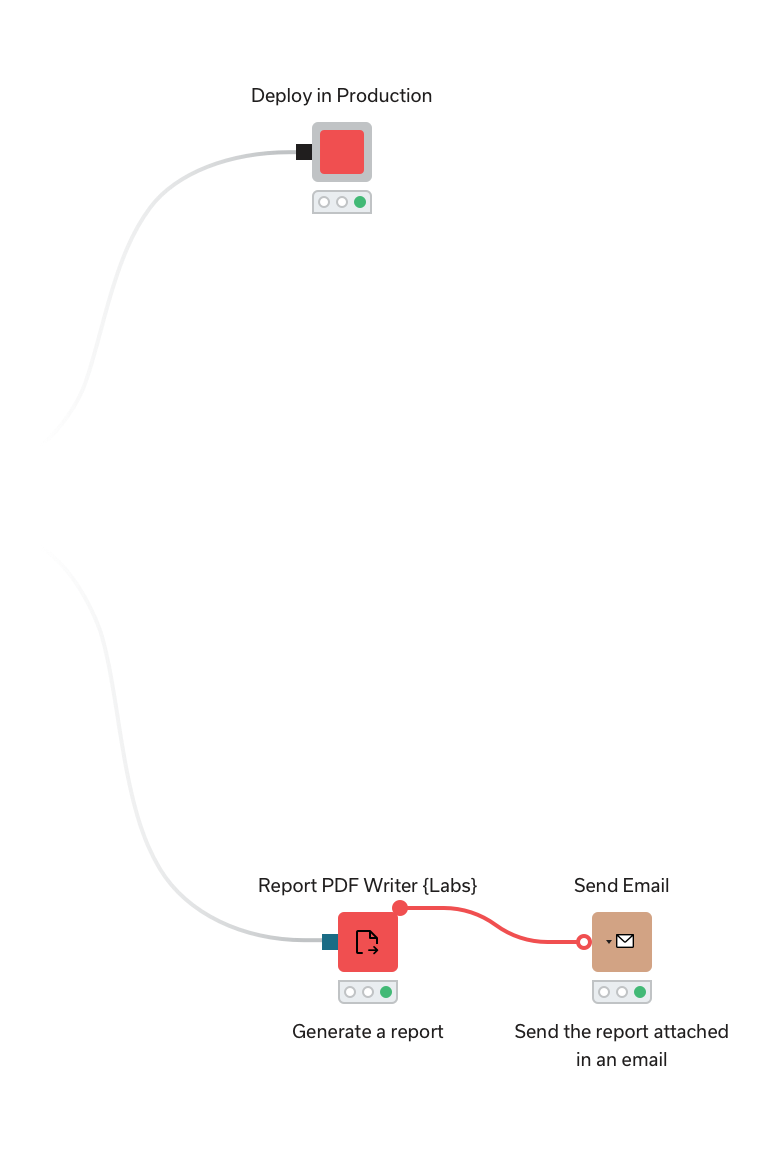
Save, share, and reuse
- Bundle segments of workflows as components for reuse
- Integrate scripting in Python, R, and Javascript - and share for later reuse
- Auto-create scripts with prompts to a genAI assistant
- Extend KNIME capabilities by adding custom functionality through coding
Upskill
- Join the open community of over 100,000+ KNIME Analytics Platform users
- Learn and share solutions on KNIME Community Hub, a community-built repository of 14,000+ data science solutions spanning use cases
- Lean on a genAI assistant to auto-generate analysis and guide you as you upskill
- Take self-paced or guided courses led by data scientists to continuously enhance your skills
Here's what customers love about KNIME


Why KNIME?
Hear about why Wendy Guan, Executive Director of CGA at Harvard, chooses to use KNIME for advanced analysis and upskilling.
Start using
KNIME Analytics Platform today
