KNIME Integrated Deployment
Closing the gap between data science creation and putting results into production
The end to end data science process traditionally starts with raw data and ends with the creation of a model. Moving that model into daily production requires considerable extra work, causing many businesses to stumble at the gap between having created a model and putting it into production. Integrated Deployment allows not just the model but all of its associated preparation and post-process steps to be identified and automatically reused in production with no changes or manual work required. Using KNIME Integrated Deployment, organizations can replicate the process repeatedly with ease to maintain model performance.
The benefits
Time savings
Save time and free up both data science and model operations resources.Fewer errors
Reduce the error risk associated with moving from model creation to deploying production processes.Increased compliance
Capture and store both creation and production processes = full support of governance and compliance reporting.Optimized processes
Optimize the updating of productions processes automatically.How it works
A workflow is created to generate an optimal model. The Integrated Deployment nodes allow the data scientist to capture the parts of the workflow needed for running in a production environment, the model or library itself as well as the data preparation. These captured subsets are saved automatically as workflows with all the relevant settings and transformations. There is no limitation in this identification process - it can be as simple or as complex as required.
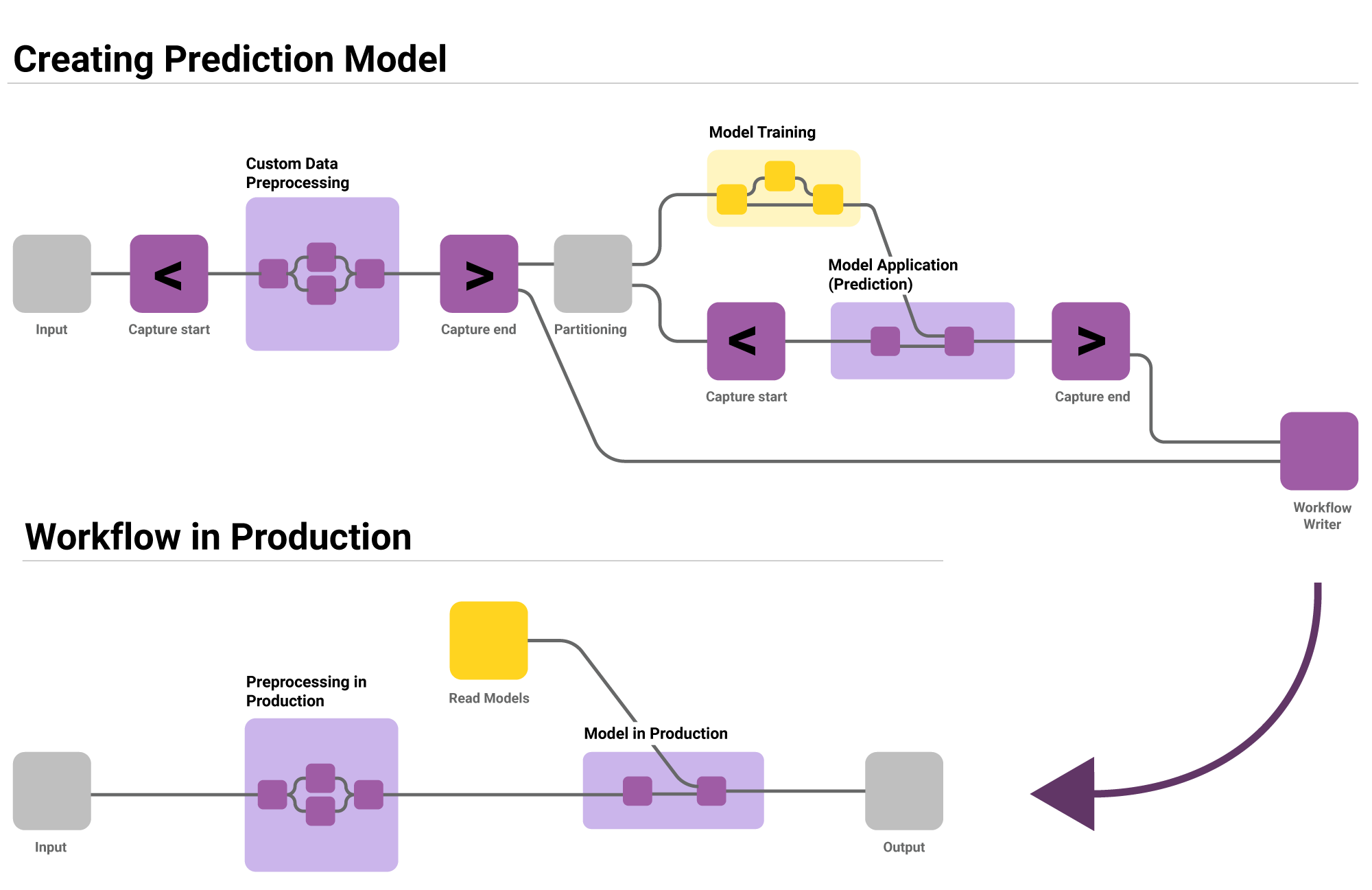
KNIME Business Hub
With KNIME Business Hub in production, the captured workflows can be automatically referenced and reused. Organizations with many production models benefit from being able to take the optimized creation workflows and use them in a scheduled or triggered environment. When new models are required in production, the same KNIME Business Hub setup can rerun the captured workflows automatically, delivering newly updated and automated production workflows to the business.