
In this blog series we’ll be experimenting with the most interesting blends of data and tools. Whether it’s mixing traditional sources with modern data lakes, open-source devops on the cloud with protected internal legacy tools, SQL with noSQL, web-wisdom-of-the-crowd with in-house handwritten notes, or IoT sensor data with idle chatting, we’re curious to find out: will they blend? Want to find out what happens when IBM Watson meets Google News, Hadoop Hive meets Excel, R meets Python, or MS Word meets MongoDB?
Today: YouTube Metadata meet WebLog Files. What will it be tonight – a movie or a book?

The Challenge
Thank God it’s Friday! And with Friday, some free time! What shall we do? Watch a movie or read a book? What do the other KNIME users do? Let’s check!
When it comes to KNIME users, the major video source is YouTube; the major reading source is the KNIME blog. So, do KNIME users prefer to watch videos or read blog posts? In this experiment we extract the number of views for both sources and compare them.
YouTube offers an access REST API service as part of the Google API. As for all Google APIs, you do not need a full account if all you want to do is search; a key API is enough. You can request your own key API directly on the Google API Console. Remember to enable the key for the YouTube API services. The available services and the procedure to get a key API are described in these 2 introductory links:
https://developers.google.com/apis-explorer/?hl=en_US#p/youtube/v3/
https://developers.google.com/youtube/v3/getting-started#before-you-start
On YouTube the KNIME TV channel hosts more than 100 tutorial videos. However, on YouTube you can also find a number of other videos about KNIME Analytics Platform posted by community members. For the KNIME users who prefer to watch videos, it could be interesting to know which videos are the most popular, in terms of number of views of course.
The KNIME blog has been around for a few years now and hosts weekly or biweekly content on tips and tricks for KNIME users. Here too, it would be interesting to know which blog posts are the most popular ones among the KNIME users who prefer to read – also in terms of number of views! The numbers for the blog posts can be extracted from the weblog file of the KNIME web site.
YouTube with REST API access on one side and blog page with weblog file on the other side. Will they blend?
Topic. Popularity (i.e. number of views) of blog posts and YouTube videos.
Challenge. Extract metadata from YouTube videos and metadata from KNIME blog posts.
Access Mode. WebLog Reader and REST service.
The Experiment
Accessing the YouTube REST API
We are using three YouTube REST API services:
- The video search service, named “search”:
https://www.googleapis.com/youtube/v3/search?q=KNIME&part=id&maxResults=50&videoDuration=any&key=<your-key-API>
Here we search for videos that are tagged “KNIME” (q=KNIME), allowing a maximum of 50 videos in the response list (maxResults=50). - The service for the video details, named “videos”:
https://www.googleapis.com/youtube/v3/videos?id=<videoID>&part=snippet,statistics,contentDetails&key=<your-key-API>
We pass the video IDs we get from the “search” service (id=<videoID>). In return we obtain details of the video, such as duration, permission flags, and statistics, in terms of total number of views, likes, and other video related actions. - The service retrieving the comments to the video, named “commentThreads”:
https://www.googleapis.com/youtube/v3/commentThreads?videoId=<videoID>&part=snippet,id&key=<your-key-API>
Here we pass the video IDs we get from the “search” service (id=<videoID>). In return we obtain all comments posted for that video, including the comment text, author ID, and posting date.
A variation of the same metanode, with name starting with “YouTube API”, is used to invoke all three YouTube REST API services. All metanodes have the same structure:
- First the REST query is built as a String, as described above, through a String Manipulation node;
- then the query is sent to the REST server through a GET Request node;
- the list of videos or comments or details is extracted from the REST response with a JSON Path node;
- the same list is ungrouped to place each JSON-structured item in a table row;
- finally the interesting values are extracted from each JSON-structured item.
See figure 1 for the content of a “YouTube API…” metanode.
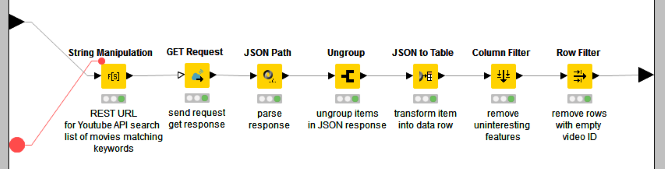
The upper branch of the final workflow has been built around such metanodes to access the YouTube REST API and to extract the videos related to the given keywords, their details, and the attached comments.
- The YouTube branch of the workflow starts by creating the keyword for the search and passing the key API for the REST service to be run. Remember, you can get the key API at https://developers.google.com/youtube/v3/getting-started#before-you-start. For both tasks we use a String Input Quickform node. The 2 String Input nodes are contained in the first wrapped node, named “keywords and key API”.
- We now send the request to the first YouTube API REST service, the one named “search”, with the keyword “KNIME” defined at the previous step. At the output of the dedicated metanode we get the list of 50 videos tagged “KNIME”.
- Then for each result video we send the request for statistics and comments to the YouTube services named “videos” and “commentThreads” respectively and are returned a list of properties and comments for each video.
- The Comments
- We now subject the comments to some text processing! Text processing includes language recognition, classical text clean up, bag of word creation, and frequency calculation - all contained in the metanode named “Text-Preprocessing”.Note. Language recognition is performed by means of the Tika Language Detector node. Given a text, this node produces a language hypothesis and a confidence measure. We take only comments in English with confidence above 0.8.The plurality of languages shows how widely KNIME is used around the world. However, we limited ourselves to English just for comprehension reasons.
- Finally, the terms and frequencies of the video comments end up in a word cloud, built by means of the Tag Cloud node.
- The word cloud image is then exported into the report connected to this workflow.
- We now subject the comments to some text processing! Text processing includes language recognition, classical text clean up, bag of word creation, and frequency calculation - all contained in the metanode named “Text-Preprocessing”.
- The Video Statistics
- The video statistics in terms of view count, like count, and similar, are sorted by view count in descending order and the top 10 rows are selected; we extract the top most viewed videos on YouTube, tagged with the word “KNIME”.
- Next, a bar chart is built showing the view count for the top most viewed KNIME related YouTube videos.
Parsing the WebLog File
The KNIME blog is part of the general KNIME web site. All access details about the KNIME blog are available in the weblog file from the KNIME web site. Among those details, the access data for each blog post are available in the weblog file.
The lower branch of this experiment’s workflow focuses on reading, parsing, and extracting information about the KNIME blog posts from the site weblog file.
- KNIME Analytics Platform offers a dedicated node to read and parse weblog files: the Web Log Reader node. The lower workflow branch starts with a Weblog Reader node. In the configuration window of the Web Log Reader node, a few useful parsing parameters can be defined. Besides the file path, which is necessary of course, it is also possible to set the date format, time interval, line format, and locale you want to use. The button “Analyze Log” produces a rough analysis of the log file structure and the required settings. The Web Log Reader node can be found in the wrapped metanode named “Read Log Files”.
- The next process after importing the content of the weblog file involves parsing and filtering to make sure we separate all the blog post details from all of the other information.
- The list of titles of the blog posts published so far is made available, among other things, by the metanode “Get Blog Patterns”.
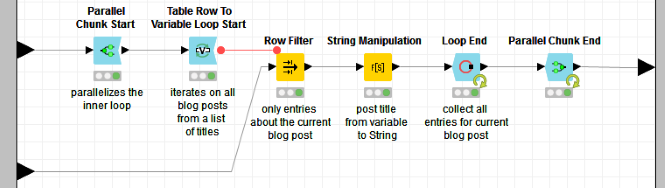
- This title list feeds a TableRow to Variable Loop Starts node, in metanode “Extract Post Entries”. This node iterates through all post titles, one by one, and the following Row Filter node extracts the weblog content related to the post title in the current iteration. The loop collects all weblog entries for each one of the blog post titles.Note. Actually, as you can see from figure 2, the metanode “Extract Post Entries” exhibits 2 loops. The second loop loops around the blog post titles, one by one, as described above. The first loop, the parallel chunk loop, is just a utility loop, used to parallelize and speed up its loop body.
- The last metanode, called “Aggregate & Sort”, counts the number of views for each blog post based on the number of related entries, and extracts the top 10 most viewed blog posts since the first publication.
Data Blending and Final Report
The upper branch has the data from YouTube, aggregated to show the number of views for the top 10 most viewed KNIME tagged videos.
The lower branch has the data from the weblog file, aggregated to show the number of views for the top 10 most read KNIME blog posts.
The two datasets are joined through a Joiner node and sent to the workflow report project.
The final workflow is shown in figure 3.
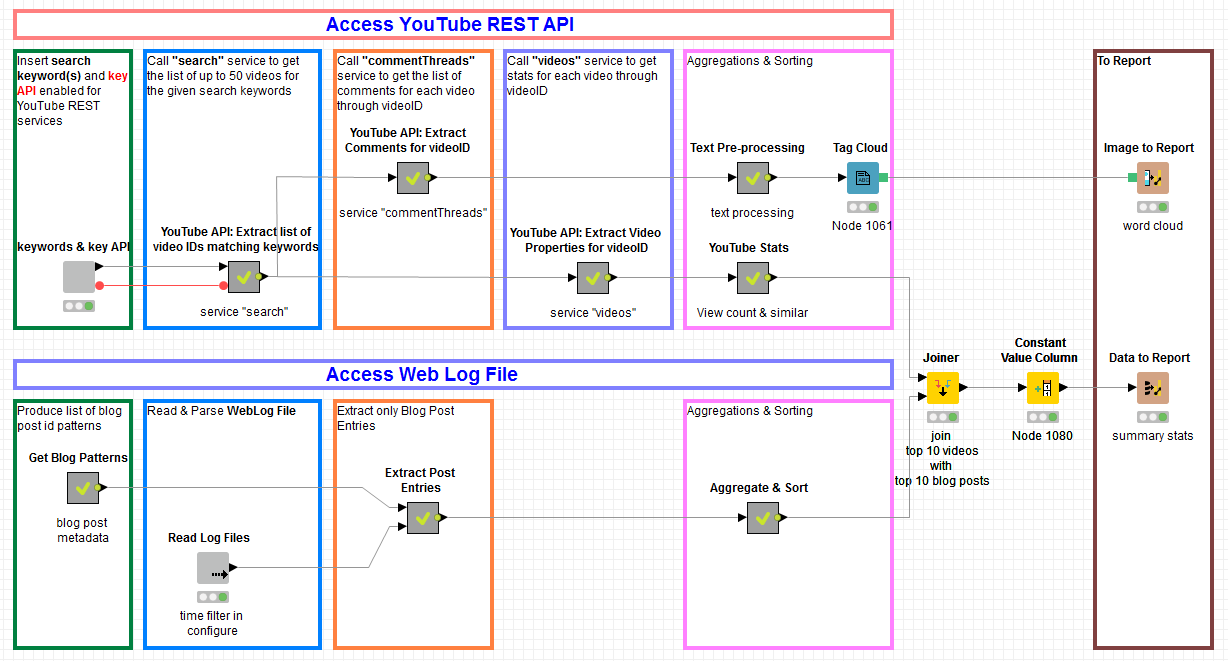
For privacy reasons, we could not make this workflow available as it is on the KNIME EXAMPLES server.
However, you can find an example workflow for the WebLog Reader node on the EXAMPLES server under 01_Data_Access/07_WebLog_Files/01_Example_for_Apache_Logfile_Analysis01_Data_Access/07_WebLog_Files/01_Example_for_Apache_Logfile_Analysis*.
The upper part of this workflow can be found on the EXAMPLES server under 01_Data_Access/05_REST_Web_Services/03_Access_YouTube_REST_API01_Data_Access/05_REST_Web_Services/03_Access_YouTube_REST_API*, without the key API information. You will need to get your own key API, enabled for the YouTube REST API, from the Google API Console.
The Results
The report created from the workflow is exported as pdf document in figure 4. On page 2 and 3, you will see two bar charts reporting the number of views for the top 10 most viewed YouTube videos and the top 10 most read blog posts, respectively.
Here are the top 10 YouTube videos:
- “An Introduction to KNIME” by KNIME TV
- “Learning KNIME through the EXAMPLES Server – Webinar” by KNIME TV
- “Introduction to the KNIME Data Mining System (Tutorial)” by Predictive Analytics
- “Text Mining Webinar” by KNIME TV
- “KNIME Workflow Introduction” by KNIME TV
- “Building a basic Model for Churn Prediction with KNIME” by KNIME TV
- “KNIME: A tool for Data Mining” by Sania Habib
- “Analyzing the Web from Start to Finish - Knowledge Extraction using KNIME - Bernd Wiswedel - #1” by Zürich Machine Learning and Data Science Meetup
- “Recordings of "Database Access with KNIME” Webinar” by KNIME TV
- “Tutorial about the new R Interactive nodes in KNIME” by KNIME TV
Here are the top 10 KNIME blog posts:
- “Sentiment Analysis” by K. Thiel
- “7 Techniques for Data Dimensionality Reduction” by R. Silipo
- “7 Things to do after installing KNIME Data Analytics Platform” by R. Silipo
- “Semantic Enrichment of Textual Documents” by J. Grossmann
- “From D3 example to interactive KNIME view in 10 minutes” by C. Albrecht
- “To Code or not to code – Is that the question?” by M. Berthold
- “Anomaly Detection in Predictive Maintenance with Time Series Analysis” by R. Silipo
- “Author ranking and conference crawling for gene editing technology CRISPR-Cas” by F. Dullweber
- “Market Basket Analysis and Recommendation Engines” by R. Silipo
- “The KNIME Server REST API” by J. Fuller
In both lists, we find abundant material for KNIME beginners. The readers of the KNIME blog posts seem to enjoy a post or two about some specific topics, such as gene editing technology or the KNIME Server REST API, but in general they also use the KNIME blog posts to learn new how-to procedures.
The last page of the pdf report document contains the word cloud of comments in English on the YouTube videos. We would like to take the opportunity in this blog post to thank the YouTube watchers for their kind words of appreciation.
In general, we have more views on the YouTube videos than on the blog post. It is also true that the KNIME TV channel started4 years ago, while the KNIME blog only 2 years ago. Since we have not set any time limits, the number of views are counted from each video/post uploading date. So, it is hard to conclude the proportion of KNIME users who prefer watching videos over reading posts.
Summarizing, in this experiment we tried to blend data from a weblog file with metadata from YouTube videos. Again, the most important conclusion is: Yes, they blend!
What about you? Which kind of KNIME user are you? A video watcher or a blog post reader?
News! If you are a video watcher type, we have a new treat for you. A full e-learning course to introduce new and old users to the secrets of KNIME Analytics Platform is now available on the KNIME web site.
This e-learning course consists of a series of short units. Each unit involves a brief YouTube video and often a dedicated exercise to allow data scientists to learn about KNIME Analytics Platform and ETL operations at their own pace.
So, if you are looking for something fun to do this evening, you can start exploring this new e-learning course. The intro page has a lot of information.

Coming Next …
If you enjoyed this, please share this generously and let us know your ideas for future blends.
We’re looking forward to the next challenge. There we will find out if we can blend two different SQL dialects: Spark SQL and Hive SQL. Will they blend?