
Sentiment analysis of free-text documents is a common task in the field of text mining. In sentiment analysis predefined sentiment labels, such as "positive" or "negative" are assigned to texts. Texts (here called documents) can be reviews about products or movies, articles, tweets, etc.
In this article, we'll show you how to assign predefined sentiment labels to documents, using text processing in KNIME Analytics Platform. KNIME is open-source software that you can download to access, blend, analyze, and visualize your data, without any coding. We'll look at how you can use the KNIME Text Processing extension in combination with traditional KNIME learner and predictor nodes.
A set of 2000 documents has been sampled from the training set of the Large Movie Review Dataset v1.0. The Large Movie Review Dataset v1.0 contains 50000 English movie reviews along with their associated sentiment labels "positive" and "negative". We sampled 1000 documents of the positive group and 1000 documents of the negative group. The goal here is to assign the correct sentiment label to each document.
Try out the workflow associated with this post (Fig. 1) yourself. It is available to download from the KNIME Hub.
Read the Review Texts: Text Data
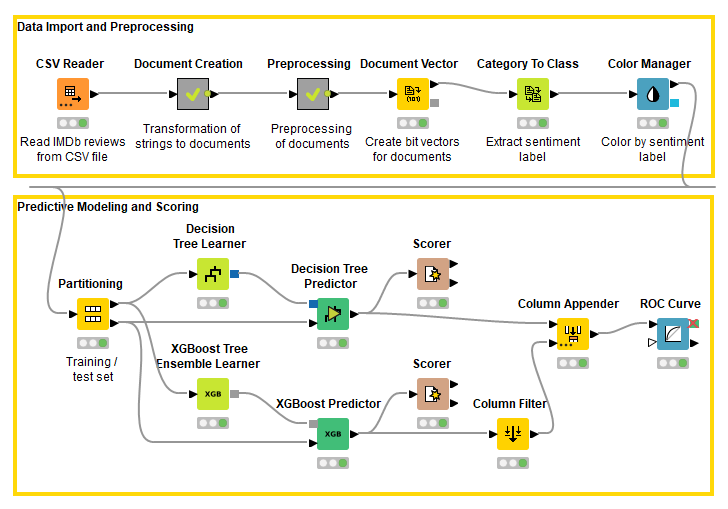
The workflow starts with a CSV Reader node, reading a CSV file, that contains the review texts, its associated sentiment label, the IMDb URL of the corresponding movie, and its index in the Large Movie Review Dataset v1.0. Important are the text and the sentiment columns. In the first metanode "Document Creation", Document cells are created from the string cells, using the Strings to Document node; the sentiment labels are stored in the category field of each document, to remain available for later tasks; and all columns, except the Document column, are filtered out.
The output of the first metanode "Document Creation" is a data table with only one column containing the Document cells.
Pre-process the Text
The textual data is preprocessed by various nodes provided by the KNIME Text Processing extension. All preprocessing steps are applied in the second metanode "Preprocessing", as shown in fig. 2.

First, punctuation marks are removed by the Punctuation Erasure node, then numbers and stop words are filtered, and all terms are converted to lowercase. After that, the stem is extracted from each word using the Snowball Stemmer node. Indeed, the words “selection”, “selecting” and “to select” refer to the same lexical concept and carry the same information in a document classification or topic detection context. Besides English texts, the Snowball Stemmer node can be applied on texts of various languages, e.g. German, French, Italian, Spanish, etc. The node is using the Snowball stemming library.
Extract Features and Create Document Vectors
After all this pre-processing, we reach the central point of the analysis which is to extract the terms to use as components of the document vectors and as input features to the classification model.
To create the document vectors for the texts, first we create their bag of words using the Bag Of Words Creator node; then we feed the data tables containing the bag of words into the Document Vector node. The Document Vector node will take into account all terms contained in the bag of words to create the corresponding document vector.
Notice that a text is made of words and a document - which is a text including some additional information such as category or authors - contains terms i.e., words including some additional information such as grammar, gender, or stem.
Tip: How to Avoid Performance Issues when Texts are Long?
Since texts are quite long, the corresponding bags of words can contain many words, the corresponding document vector can have a very high dimensionality (too many components), and the classification algorithm can suffer in terms of speed performance. However, not all words in a text document are equally important.
A common practice is to filter out all least informative words and keep only the most significant ones. A good measure of word importance can be indicated by the number of occurrences of words in each single document as well as in the whole dataset.
Based on this consideration, after the bag of words has been created, we filter out all terms that occur in less than 20 documents inside the dataset. Within a GroupBy node, we group by terms and count all unique documents containing a term at least once. The output is a list of terms with the number of documents in which they occur.
We filter this list of terms to keep only those terms with a number of documents greater than 20, and then we filter the terms in each bag of words accordingly, with the Reference Row Filter node. In this way, we reduce the feature space from 22379 distinct words to 1499. This feature extraction process is part of the "Preprocessing" metanode and can be seen in fig. 3.
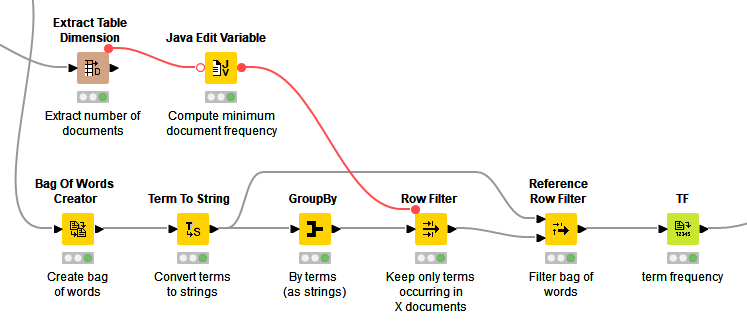
We set the minimum number of documents to 20 since we assume that a term has to occur in at least 1% of all documents (20 of 2000) in order to represent a useful feature for classification. This is a rule of thumb and of course can be optimized.
Document vectors are now created, based on these extracted words (features). Document vectors are numerical representations of documents. Here each word in the dictionary becomes a component of the vector and for each document assumes a numerical value, that can be 0/1 (0 absence, 1 presence of word in document) or a measure of the word importance within the document (e.g. word scores or frequencies). The Document Vector node allows for the creation of bit vectors (0/1) or numerical vectors. As numerical values, previously calculated word scores or frequencies can be used, e.g. by the TF or IDF nodes. In our case bit vectors are used.
Use Supervised Mining Algorithm for Classification
For classification we can use any of the traditional supervised mining algorithms available in KNIME Analytics Platform (e.g. decision trees, random forest, support vector machines, neural networks, and much more).
As in all supervised mining algorithms we need a target variable. In our example, the target is the sentiment label, stored in the document category. Therefore, the target or class column is extracted from the documents and appended as a string column, using the Category To Class node. Based on the category, a color is assigned to each document by the Color Manager node. Documents with label "positive" are colored green, documents with label "negative" are colored red.
As classification algorithms we used a Decision Tree and a XGBoost Tree Ensemble applied on a training (70%) and test set (30%), randomly extracted from the original dataset. The accuracy of the Decision Tree is 91.3%, the accuracy of the XGBoost Tree Ensemble 92.0%. The corresponding ROC curves are presented in fig. 4.
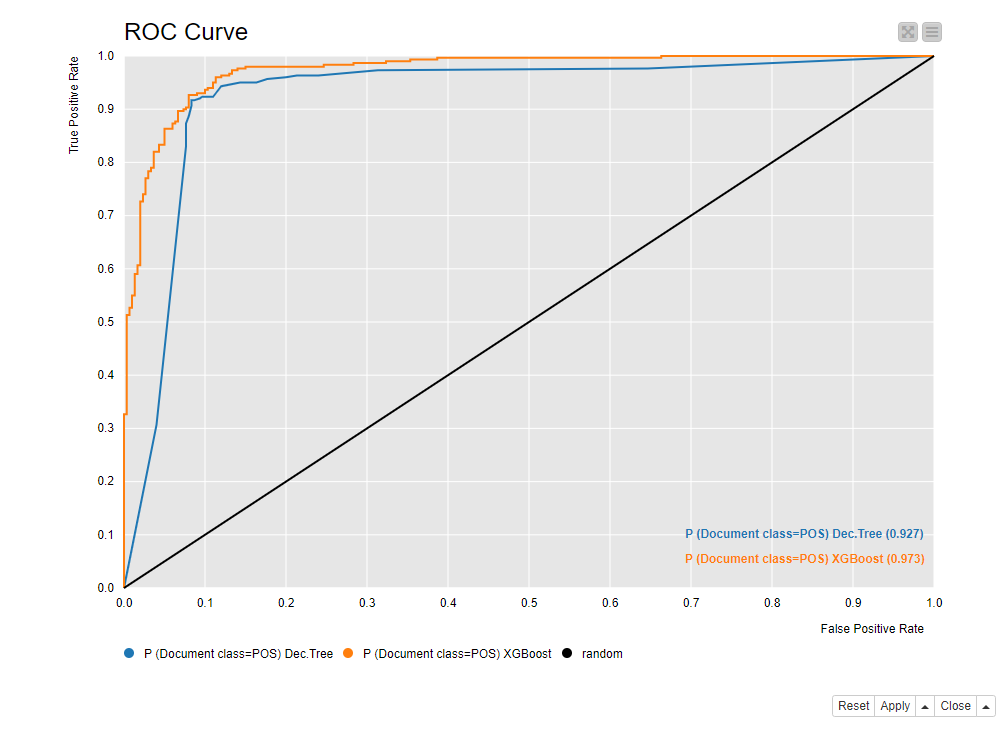
While performing slightly better, the XGBoost Tree Ensemble doesn’t have the interpretability that the Decision Tree can provide. The next figure (Fig. 5) shows a view of the first two levels of the Decision Tree. The most discriminative terms w.r.t. separation of the two classes are "bad", "wast", and "film". If the term "bad" occurs in a document it is likely to have a negative sentiment. If "bad" does not occur but "wast" (stem of waste), it is again likely to be a negative document, and so on.

There are different approaches to analyzing the sentiment of texts. Find out more about:
- Lexicon-based sentiment analysis in a tutorial, which walks you through building a predictive model that calculates a sentiment score and classifies customer tweets about US airlines.
- BERT text classification and a review of the BERT node for text classification