
It is actually quite easy to build a market basket analysis or a recommendation engine [1] – if you use KNIME! A typical analysis goal when applying market basket analysis it to produce a set of association rules in the following form:
IF {pasta, wine, garlic} THEN pasta-sauce
The first part of the rule is called “antecedent”, the second part is called “consequent”. A few measures, such as support, confidence, and lift, define how reliable each rule is. The most famous algorithm generating these rules is the Apriori algorithm [2].
Here we describe two workflows: the first workflow builds the association rules on a set of example transactions; the second workflow deploys the rule engine in a productive environment to generate recommendations for new basket data and/or new transactions.
The two workflows can be downloaded from 050_Applications/050016_MarketBasketAnalysis on the EXAMPLES server.
The Dataset
This work is based on an artificially generated dataset by the workflow in the EXAMPLES server in 007_ModularDataGeneration/007008ShoppingBasket [3]. This dataset consists of two KNIME tables: one containing the transaction data ‒ i.e. the sequences of product IDs in imaginary baskets ‒ and one containing product infos – i.e. name and price.
Building the Association Rules
The central part in building a recommendation engine is the Association Rule Learner node, which implements the Apriori algorithm, in either the traditional [2] or the Borgelt [4] implementation. The Borgelt implementation offers a few performance improvements over the traditional algorithm implementation. The output association rule set, however, remains the same.
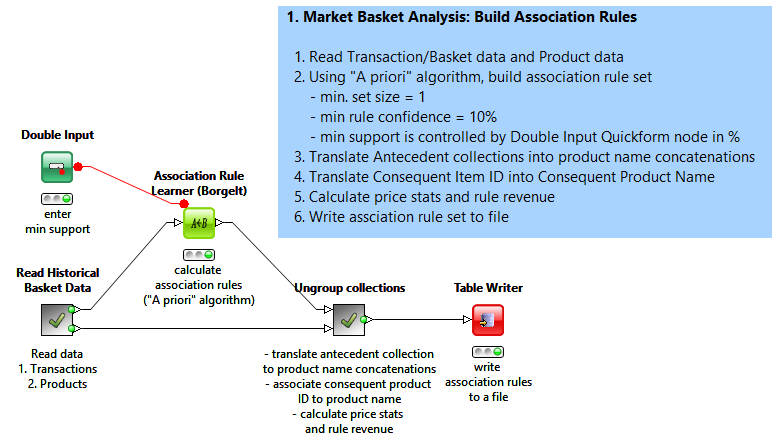
Both Association Rule Learner nodes work on a collection of product IDs. A collection is a particular data cell type, assembling together data cells. There are many ways of producing a collection data cell from other data cells [5]. We used the Cell Splitter node to split the original transaction string into many product ID substrings, using space as the delimiter character, and collecting all product ID substrings into a collection column.
We run the Association Rule Learner node on a set of basket examples, to generate the association rule set. Each rule includes a collection of product IDs as antecedent, one product ID as consequent, and a few quality measures, such as support, confidence, and lift. Quality measures describe how likely and how reliable the current rule is. You can make your association rule engine larger or smaller, restrictive or tolerant, by changing the threshold values in the Association Rule Learner configuration settings, such as “minimum set size”, “minimum rule confidence”, and “minimum support”.
For a definition of these quality measures and for more details about what they mean, please see the complete use case.
A potential revenue for each rule was also calculated, as:
revenue = (consequent price) x (rule item set support)
Based on this set of association rules, we can say that if a customer buys wine, pasta, and garlic (antecedent) usually ‒ or as usually as support says ‒ they will also buy pasta-sauce (consequent); we can trust this statement with the confidence percentage that comes with the rule.
Deploying the Association Rules into Production
Let’s move now away from the basket examples and into real life. Customer X enters the shop and buys products 1 and 6, wine and pasta. Are there any products we can recommend? If our recommendation engine performs its work decently, the customer will thank us for the advice rather than be annoyed by it and we can transform obnoxious advertisement into a win-win situation.
The central node of the second workflow, to be used in production, is the Subset Matcher node.
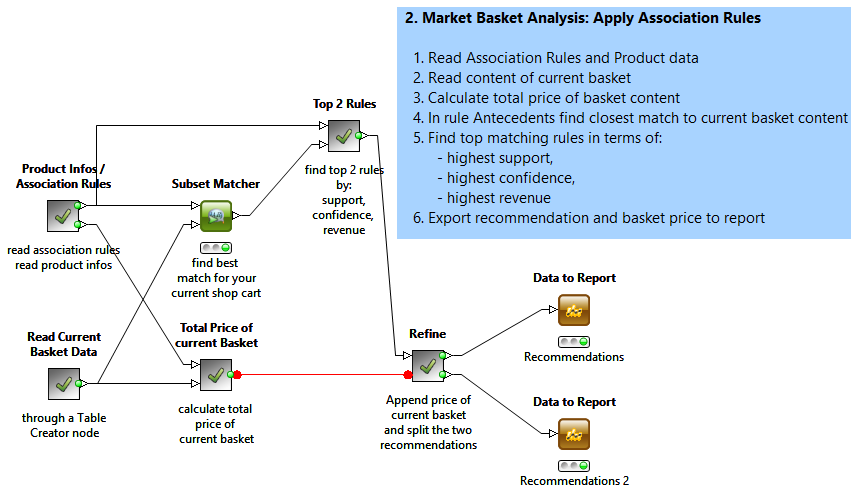
The Subset Matcher node takes two collection columns as input: the antecedents in the rule set (top input port) and the content of the current shopping basket (lower input port). It then matches the current basket item set with all possible subsets in the rule antecedents. The output table contains pairs of matching cells: the current shopping basket and the totally or partially matching antecedents from the rule set.
Of all the resulting matching rules, only the top 2 with the highest item set support (renamed as rule support), highest confidence, and highest revenue, are retained and their consequents are shown in the final report, as shopping recommendations.

For the selected shopping basket, the recommended product is always lobster, associated once with cookies and once with shrimps. While shrimps and lobster are typically common sense advice, cookies and lobster seem to belong to a more hidden niche of food experts!
References
-
“Association Rule Learning”, Wikipedia http://en.wikipedia.org/wiki/Association_rule_learning
-
“Find Frequent Item Sets and Association Rules with the Apriori Algorithm” C. Borgelt’s home page http://www.borgelt.net/doc/apriori/apriori.html
-
“Collection Cookbook”, Tobias Koetter, KNIME Blog, http://www.knime.org/blog/collection-cookbook