
Ten years ago, a corporate data science team meant one or two PhD grads huddled together in the back corner of the IT department, infrequently sharing impressive machine learning models. Today, a data science team is a profit center - supporting directly or indirectly every department throughout the business. The value of understanding and acting on big data is unquestioned and a data science function sits at every Fortune 500 company.
The function of data science is maturing within organizations, and so too, are our data science standards.
As data science outgrows a small, siloed department and becomes an integral supporting function at any modern organization, we have the responsibility to start paying much more attention to how our insights are being used.
To this end, The Data Science Life Cycle represents a new standard for how to think about data science in the modern corporate environment.
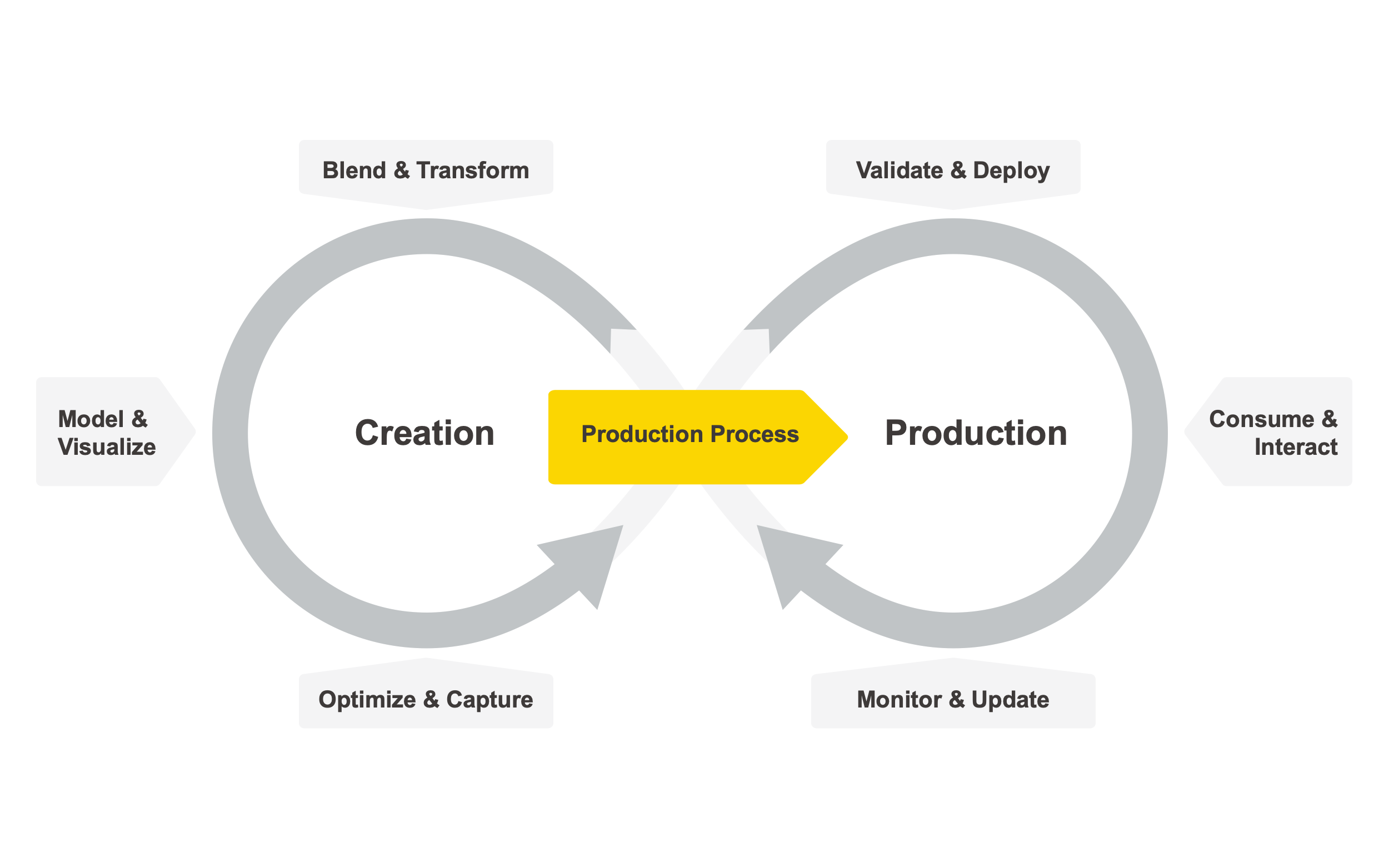
KNIME has created this standard, building on the great work of its predecessors - standards like CRISP-DM, SEMMA, K-DD. All of these frameworks, however, when applied to real-world, enterprise environments, fall short in the same way.
None of these standards detail productionization - or what happens after our production processes are deployed. Precisely, how users consume and interact with the data, and, afterward, how the data science cycle is monitored and updated, based on real world feedback.
The often neglected post-deployment steps - or where the data science actually gets used - are depicted in the right-hand loop of the Data Science Life Cycle. These include choosing the appropriate method of deployment, facilitating consumption and interaction, and finally monitoring performance and incorporating feedback to improve the data science process over time.
Establishing this parlance enables us to better balance the pure science of data exploration and modeling with the practical applications of the specific insights we uncover. In other words, the Data Science Life Cycle helps us fill the gap between the creation and production of data science.
The Steps of the Data Science Life Cycle
Let’s take a closer look at each of the key steps in our infinity loop:
- Blend & Transform: In this phase of the data cycle relevant data, sometimes forming disparate systems, are combined, cleaned and prepared based on the requirements of the desired data science technique
- Model & Visualize: Here, analysts make sense of data through a combination of various modeling and visualization techniques, that might include statistical analysis, data mining or machine learning methods.
- Optimize & Capture: The models and methods are tweaked to increase the overall performance. The data science team then determines which precise data transformations and computations should be captured as part of the final production process. This capturing procedure becomes extremely easy to perform and automate if performed via Integrated Deployment. Note that this Capture step means much more than shipping an isolated model or method, but rather defining a complete production process, which includes any of the data transformations from the previous steps that are required by the trained process to properly work in production.
- Validate & Deploy: The captured production process is now tested and validated. Validation typically requires measuring the added business value, confirming statistical performance or verifying compliance. In case of a successful validation the production process can be deployed in various forms.
- Consume & Interact: After deployment, the production process is available remotely, typically in one of these forms: as a data science application for users to interact with, as a data science service to integrate in other systems, as a data science component for process reusability by other data scientists, or as a scheduled and automated production process digesting data and returning results in a routine fashion.
- Monitor & Update: After deployment, the production process has to be maintained - by overseeing its behavior, monitoring when something breaks or behaves unexpectedly, and updating the process with enhancements and bug fixes.
In order to successfully follow the steps listed above, each data science team needs to tailor the Data Science Life Cycle to their use case by defining their own Data Science Operations (DSOps): the tools, activities and procedures required for operationalizing every step in the cycle.
For example when training a machine learning model the DSOps will focus on designing a system made of people and software that manages the deployment, consumption and monitoring of the entire data science process. Note that in your further reading, you may stumble upon many slight variations of the same concept (e.g., MLOps, AIOps, ModelOps, DataOps). Data Science Operations or DSOps summarizes all these concepts that deal with data science operationalization.
The Iterative Nature of Data Science
The Data Science Life Cycle accounts for the phases of iteration that are often necessary for the engineering and processing of your production process solution.
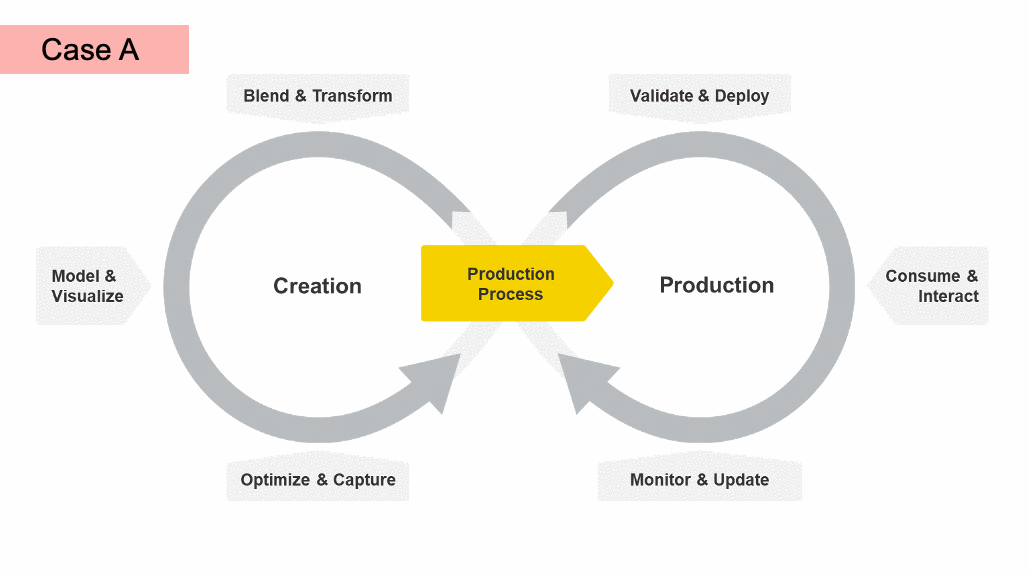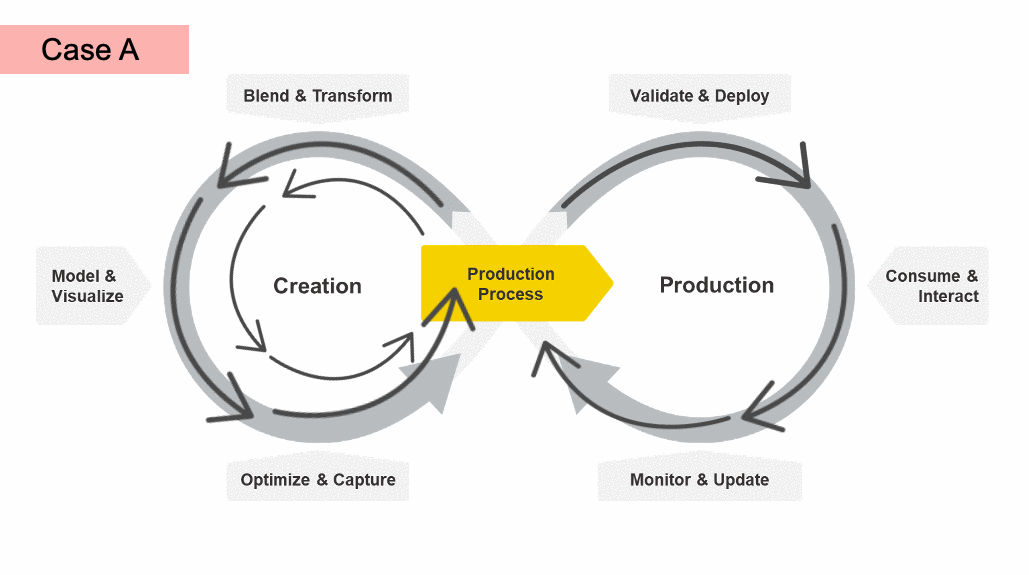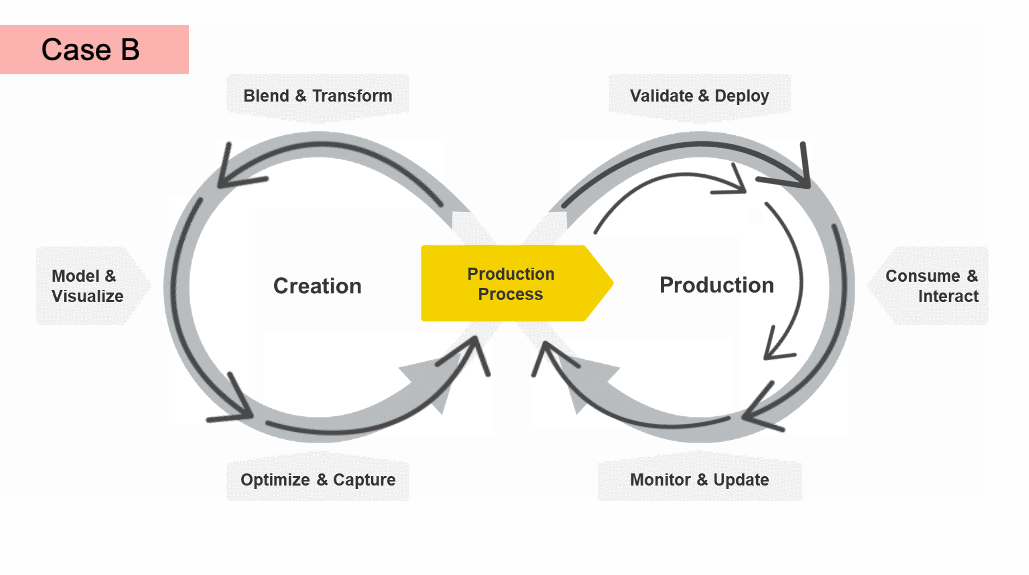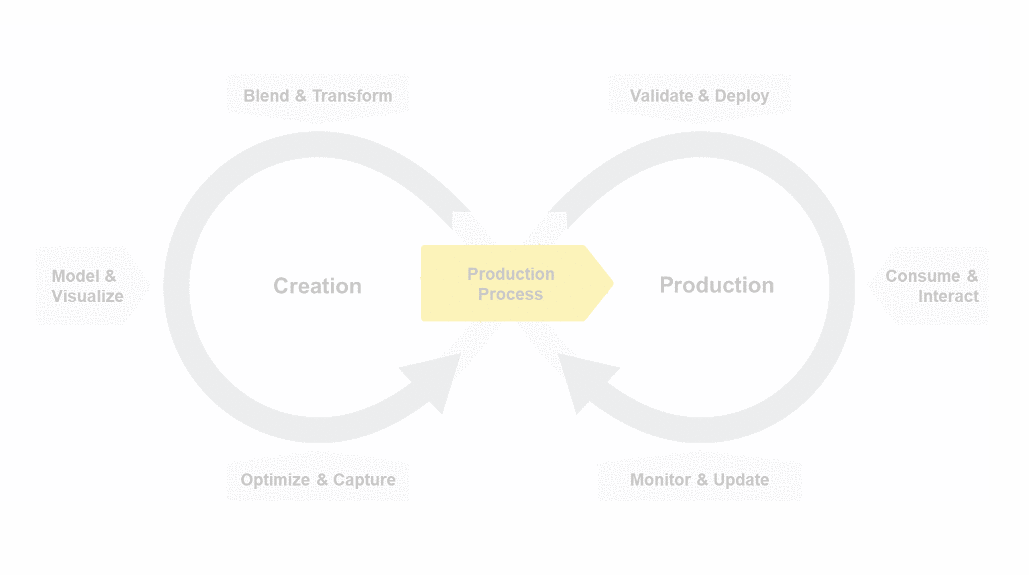
For example, after evaluating the performance of your models in the Optimize & Capture phase, you might find that you need to change how you prepare your data in the future. In this case (Case A in the animation above), you start the creation cycle again before moving on to validating and deploying your process.
Similarly, you might get to the end of the production loop and restart the right hand cycle - validating and monitoring to make sure the production process is properly consumed in production (Case B in animation). Or, after the step Monitor & Update, you might detect a loss in performance and need to go all the way back to train new development models (Case C in the animation).
This iterative process is anticipated and included in the design of these two interconnected iterative cycles.
The New Standard for Bringing Business and Data Science Closer Together
Beyond detailing more of the technical steps of data science, the Data Science Life Cycle provides a quality framework for how to think about sustainable solutions. Rather than considering “deployment” as an end to any project, we’re suggesting that a successful data science project, truly, has no end.
Once your machine learning model is no longer in use, for example, the insight from that data has ideally affected how a business user makes their decisions. And their more-informed feedback affects the next problem. And the next. Eventually, the data science solutions are based on a combination of business expertise and data science methodologies. This makes business users happier, data scientists more efficient, and the organization more effective in acting on facts.