
KNIME has always supported the mixing and matching of different file systems within the same workflow. Now, with increasing numbers of users working with KNIME in cloud and hybrid environments, the File Handling Framework has been rewritten to give KNIME users a consistent experience across all nodes and file systems. The new framework simplifies file handling significantly and introduces the following benefits:
- Consistent user experience across all nodes and file systems
- Easy to use different file systems and migrate from one cloud to another
- Managing of various file systems within the same workflow
- Powerful framework that allows us to integrate more and more file systems
- Performance improvements
In this blog post, we provide an:
- Overview of the File Handling framework
- A closer look at File Handling based on example workflows
- Blending and switching between file systems on the example of Amazon S3 and MS Azure
- Accessing file systems and web services on the example of Amazon S3 and DynamoDB
- Reducing the complexity on the example of local and remote archived files
- Reducing complexity for example when reading multiple Excel files and data transformation
- Resources
Overview of the File Handling framework
File systems, connections, and dynamic ports
The new File Handling framework has standardized the connection process, ports, nodes, and configuration interfaces across the different files and file systems.
Let’s first briefly describe the two types of file systems we can access: standard and connected.
- Standard file systems do not require a dedicated connection, you can choose your system from a dropdown menu. Examples are local file systems, KNIME Server mount points, ‘Relative to’ file systems, and ‘Custom/KNIME URL’. Find more information about this in our documentation.
- Connected file systems require a dedicated connector which allows the user to tweak file system specific settings, e.g. authentication and encryption. KNIME provides connectors for all major cloud platforms such as Amazon, Azure, Databricks and Google (figure 1).
Authentication and Connector nodes
The new File Handling Framework enables standardized and easy access to both standard and connected file systems. You can read files directly from all the supported connected file systems without needing to download them locally first.
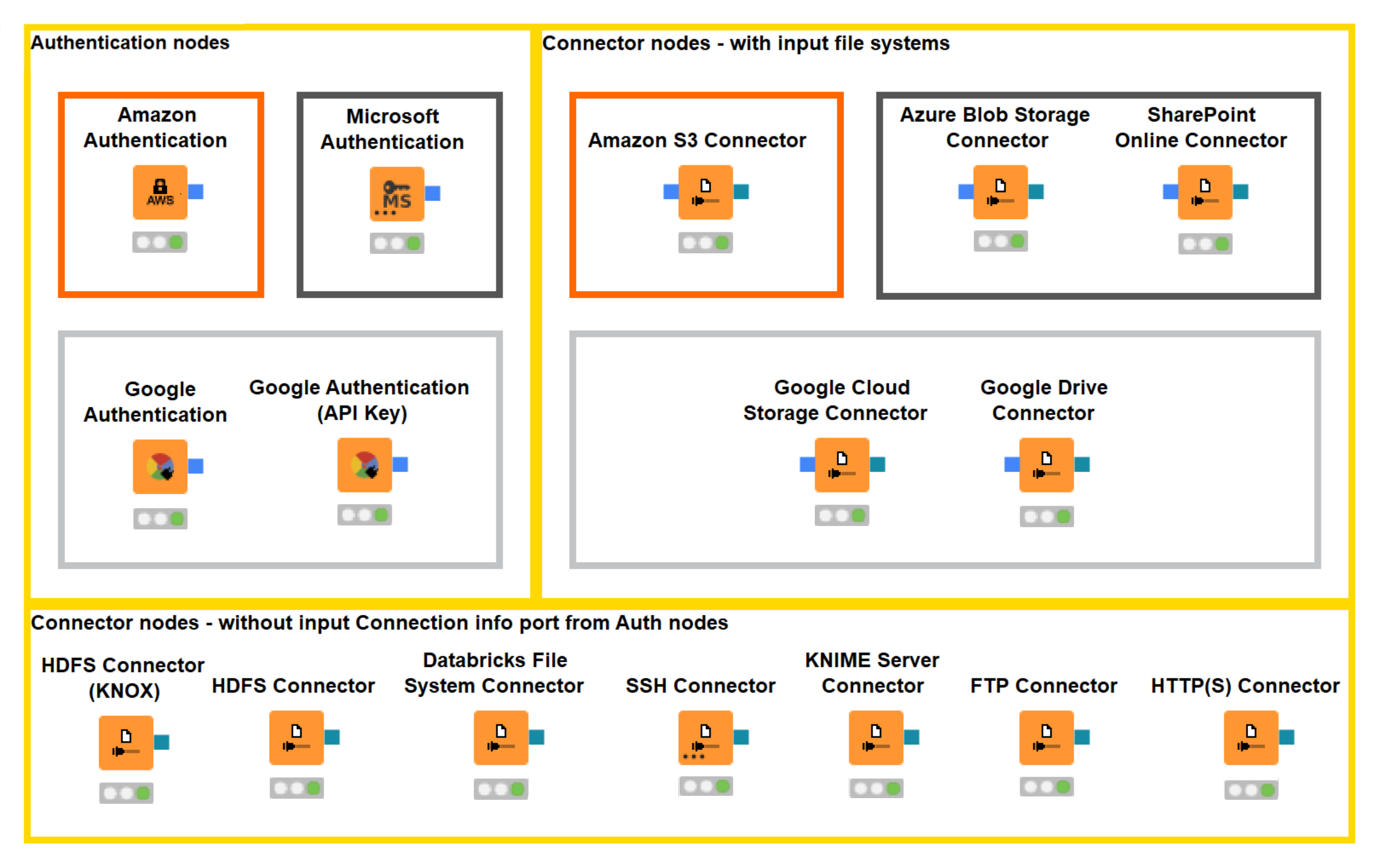
Figure 1. New Authentication and Connector nodes
One of the great features of the new File Handling is dynamic ports – the green/blue colored ports provide a connection via the respective Connector node. The ports are standard across all the connected file systems. This makes it easy to switch between different file systems if needed. You can add or remove a dynamic port at the bottom left corner of the new Reader, Writer, and Utility nodes (figure 2).
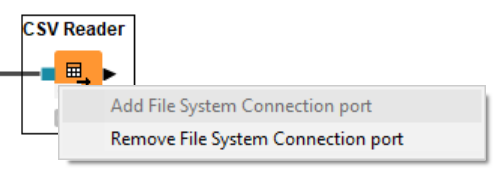
Figure 2. Dynamic port’s configuration
Reader and Writer nodes
The new Reader and Writer nodes (figure 3) provide enhanced consistency in the configuration. Dedicated nodes have been developed to address the specifics of different file types. What is then similar between, for example, an Excel Reader and a Model Reader configuration, and why would you need consistency here?
What do the Reader and Writer nodes now support:
- Dynamic ports: provide easy and straightforward reading from and writing to the connected file systems.
- Read from or write to options: Updated functionality for providing the input and output location i.e. the “Read from” or a “Write to” options, respectively.
- These two options significantly simplify specification of a file or a folder location relative to a mount point, a workflow or workflow data area - you don’t need to write the workflow relative paths from scratch. And in the case of connected file systems, the “Read from” or “Write to” options are automatically changed to the respective connected file system.
- Read multiple files: When data is in tabular format, the new Reader nodes support reading multiple files in a folder with similar columnar structure simultaneously via concatenating them into one KNIME table.
- Data preview: Whenever possible, the Reader nodes allow you to preview the data, both for standard and connected file systems: You can preview the data without needing to download and read the files into KNIME Analytics Platform.
- Table transformation: Another feature available for nodes that read tables is the transformation of the tables directly in a Reader node configuration window, before actually reading the data into the KNIME Analytics Platform. “Transformation” tab allows you to filter the columns and change their names, types, and order.
- New directory creation: The feature available in all the new Writer nodes is creating new directories directly in a Writer node configuration by simply crossing the “Create missing folders” box. Thus, the new Reader and Writer nodes allow you to avoid using additional utility nodes.

Figure 3. New Reader and Writer nodes with the dynamic ports
Utility nodes
Our utility nodes have also undergone great changes! They also have dynamic ports and support the “Read from” and “Write to” options.
These new and updated nodes also bring new opportunities for managing files and folders within one or several file systems:
- Transfer Files node allows you to easily transfer - copy or move - files and folders between file systems without the need to download or upload them first.
- List Files/Folders node have been updated to allow you to specify the listing mode between files, folders, or both.
- New path type: The new framework also comes with a new path type that uniquely identifies files and folders within a file system. Besides the file path the path type contains further information about the file system itself and thus consists of three parts:
- Type: Specifies the file system type e.g. local, relative, mountpoint, custom URL, or connected.
- Specifier: An optional string that contains additional file system specific information such as the location the relative to file system is working with such as workflow or mountpoint.
- Path: Specifies the location within the file system with the file system specific notation e.g. ``C:\file.csv`` on Windows operating systems or ``/user/home/file.csv`` on Linux operating systems.
- Path examples are (LOCAL, , C:\Users\username\Desktop) for a local directory or (CONNECTED, amazon-s3:eu-west-1, /mybucket/file1.csv) for a csv file on Amazon S3.
- String to Path (Variable) and Path to String (Variable) nodes allow for a seamless conversion from the old String and URI based path representation to the new path type and vice versa. The advantage here is that you can use the new file handling nodes with those file based nodes that have not yet been migrated to the new framework.
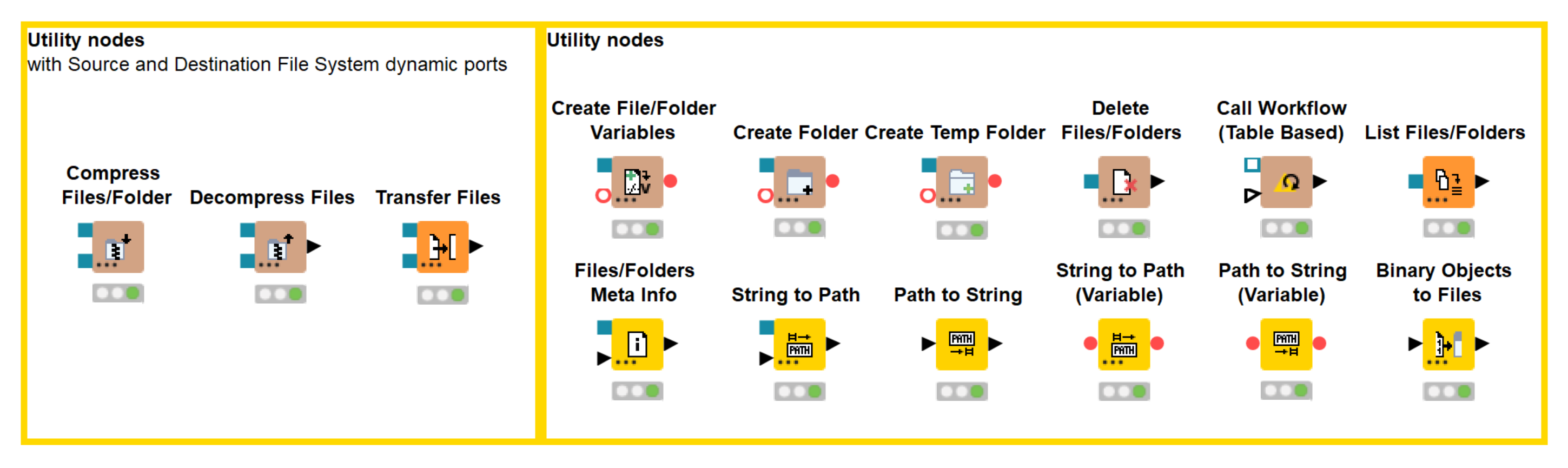
Figure 4. New Utility nodes with the dynamic ports
Referencing the new nodes
Please note that some nodes in the new File Handling framework are referenced differently. For example, the Zip Files nodes is no longer in the 4.3.0 Node Repository. Users who are familiar with that node, need to search instead for Compress Files/Folder.
To hopefully avoid confusion, Table 1 shows an overview of the old and new names. The affected nodes are also documented in the File Handling Guide.

Table 1: List of nodes showing how the old nodes reference to the new nodes in the new File Handling framework.
A closer look at File Handling based on example workflows
Blending and switching between file systems on the example of Amazon S3 and MS Azure
This first example is based on the workflow, Will They Blend? Amazon S3 meets MS Blob Storage plus Excel, which you can download from the KNIME Hub.
We want to show here how:
- The former file handling framework with Connection and File Picker nodes can be easily and fully replaced by the new nodes
- The additional advantages gained by using the new File Handling
In the example workflow we want to access two CSV CENSUS files: one, with the data on houses in Maine (United States), located on Amazon S3, and the other, with the data on people living in Maine, located on Microsoft Azure Blob Storage (figure 5).
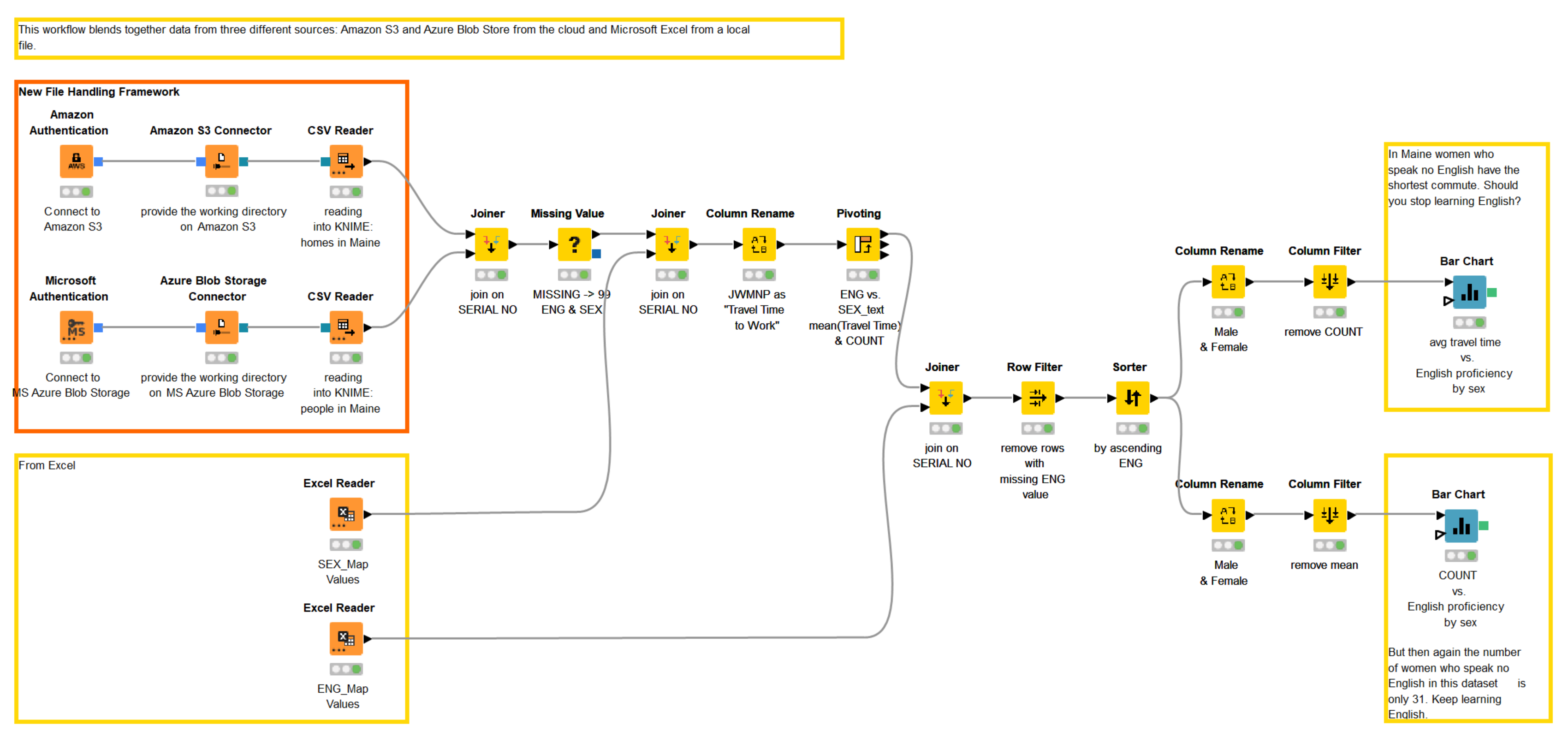
Figure 5. Accessing and blending the data from Amazon S3 and MS Azure Blob Storage using the new File Handling framework. The workflow can be downloaded from the KNIME Hub.
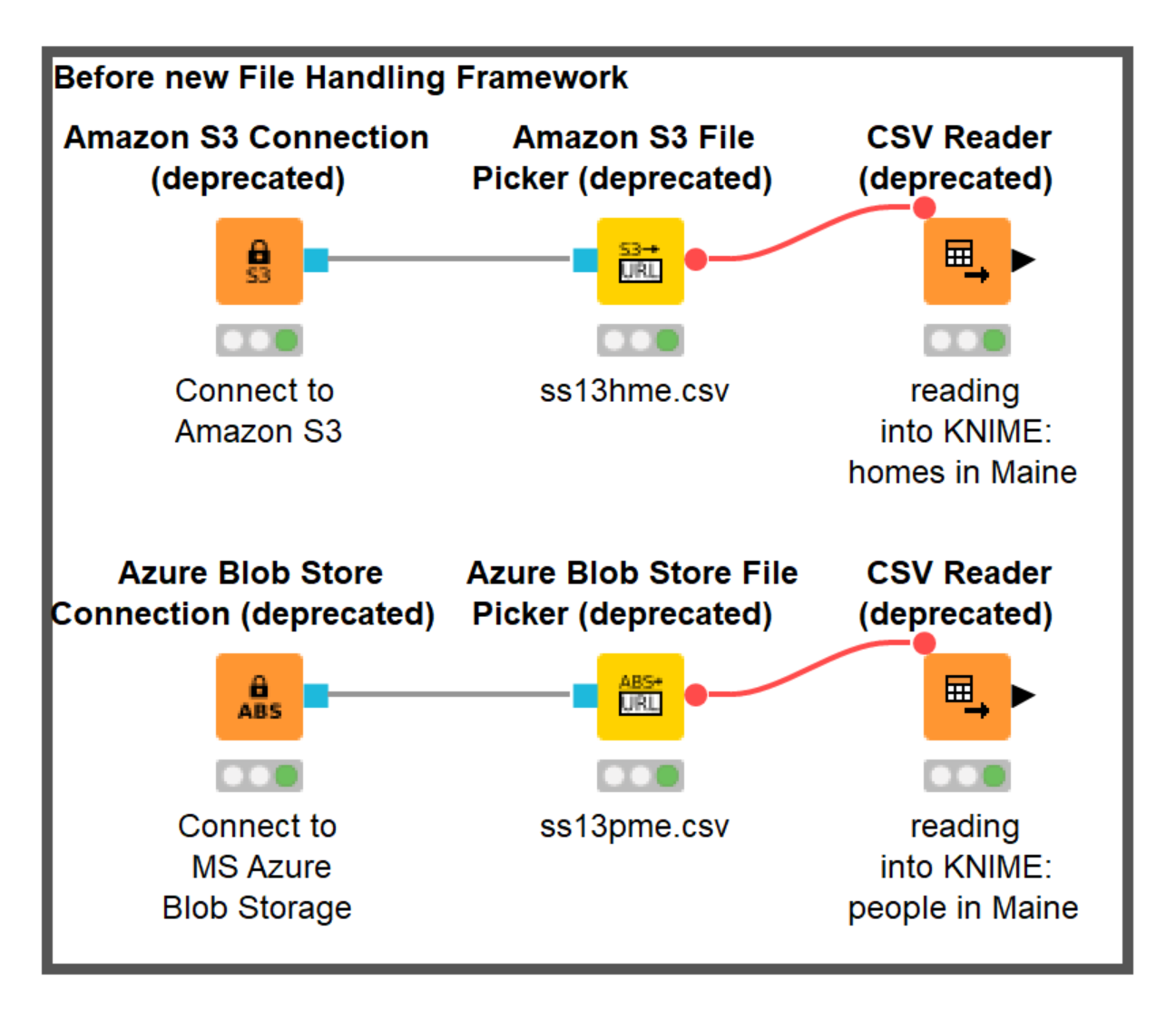
Figure 6. Old file handling framework with Connection and File Picker nodes can be easily replaced by the new nodes but is still working without changes
How are the new nodes configured?
Let’s start with the authentication in Amazon S3.
- We provide the Access Key ID and Secret Key and select the proper region to configure the Amazon Authentication node (figure 7).
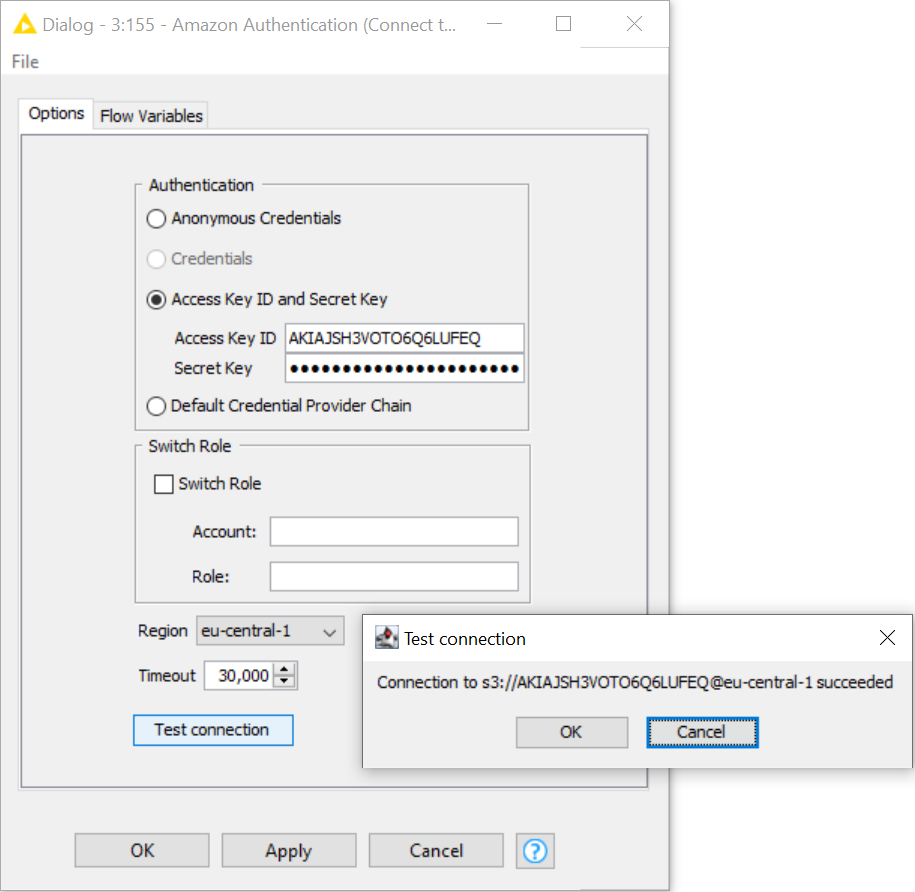
Figure 7. Amazon Authentication node configuration
- Next, we connect the Amazon Authentication node with the Amazon S3 Connector via blue authentication ports.
- In the configuration dialog of the Amazon S3 Connector, we can provide the working directory of any depth. The Amazon S3 Connector node allows intuitive browsing of your folders on Amazon S3 just like on your local file system (figure 8).
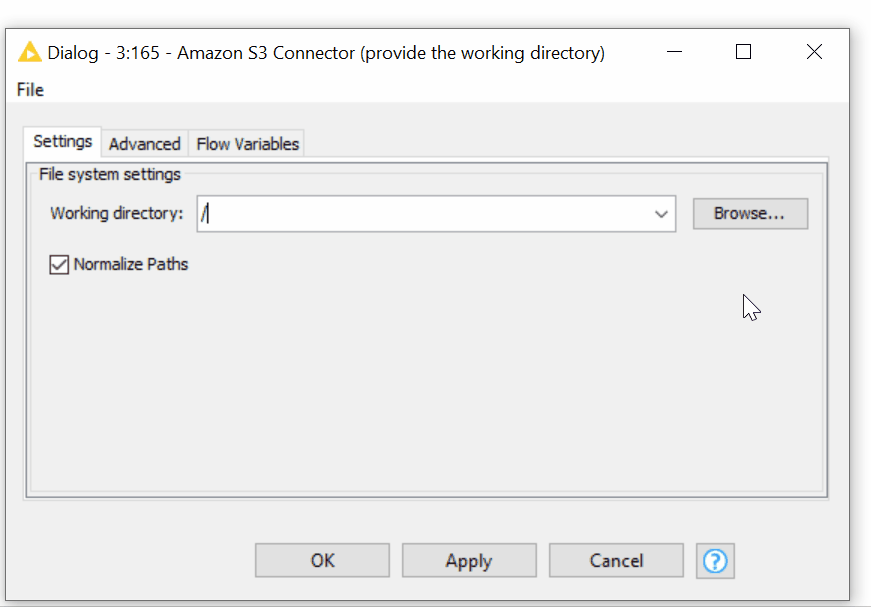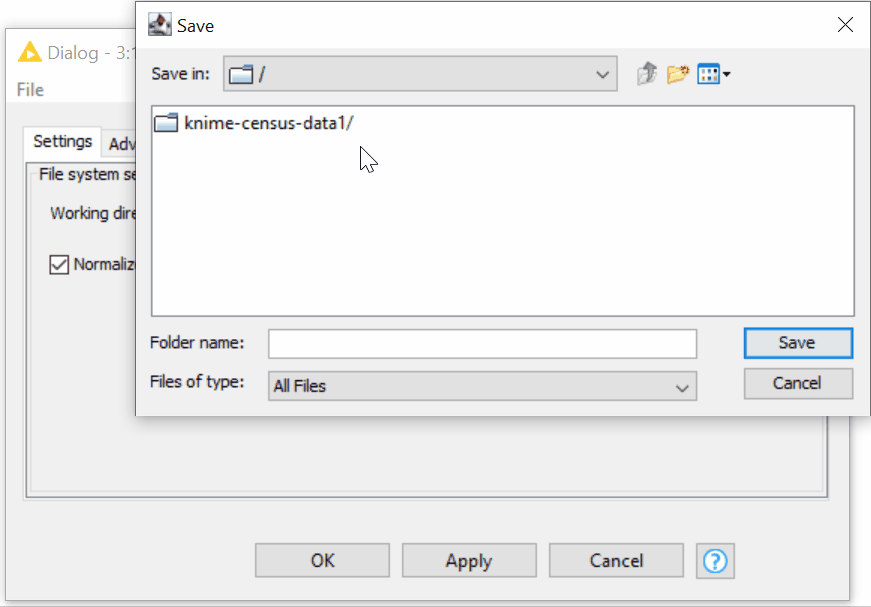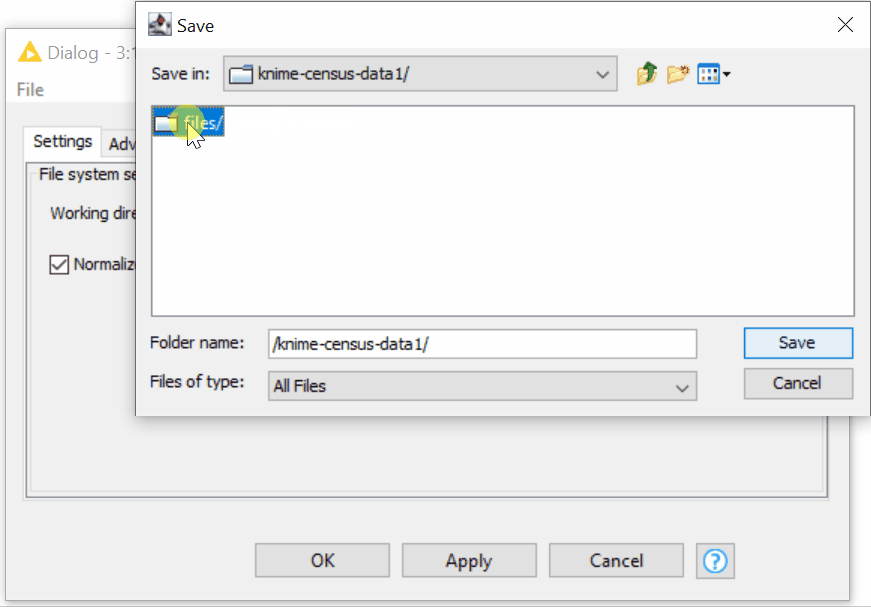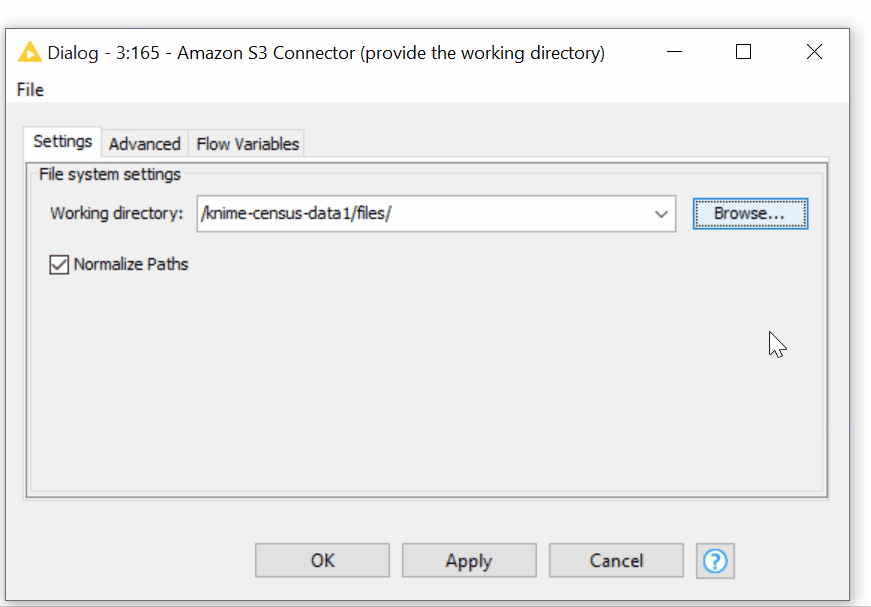
Figure 8. Browsing over the folders on S3 in the configuration of the Amazon S3 Connector
- Now, we can access the CSV file using the new CSV Reader node by connecting it via dynamic port to the respective Connector node. Amazon S3 is automatically selected for us in the “Read from” option. We find the desired file by browsing the S3 folders.
- The new CSV Reader node provides a wonderful option to autodetect the format of the CSV file. After detecting the format, we can preview the correctly parsed data in the Preview window.
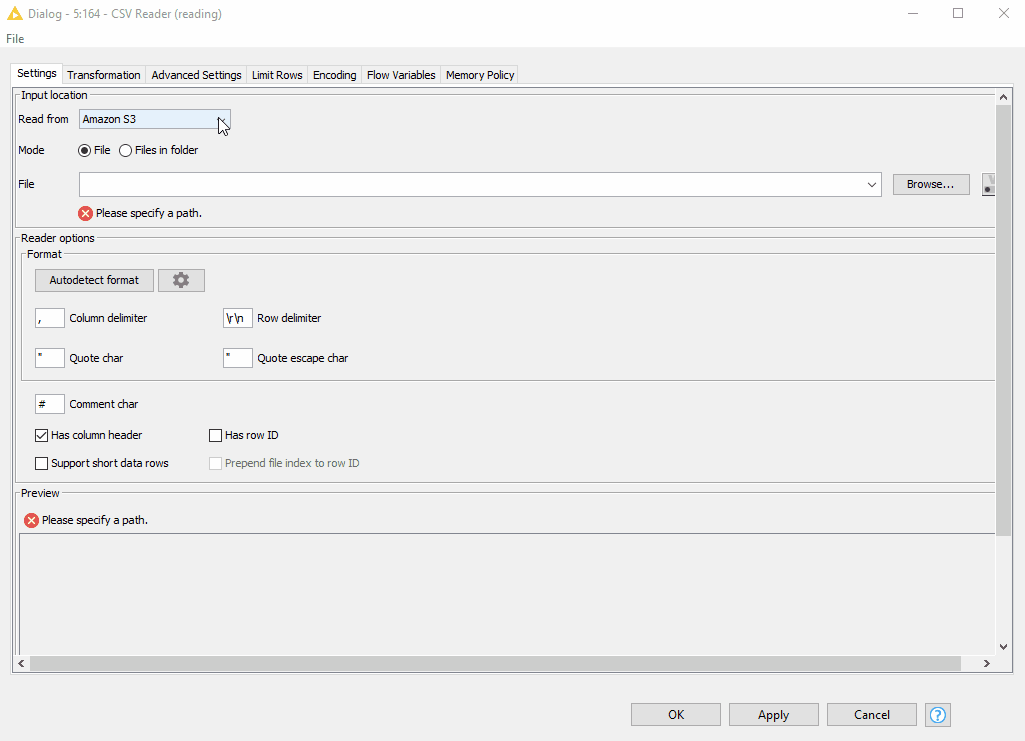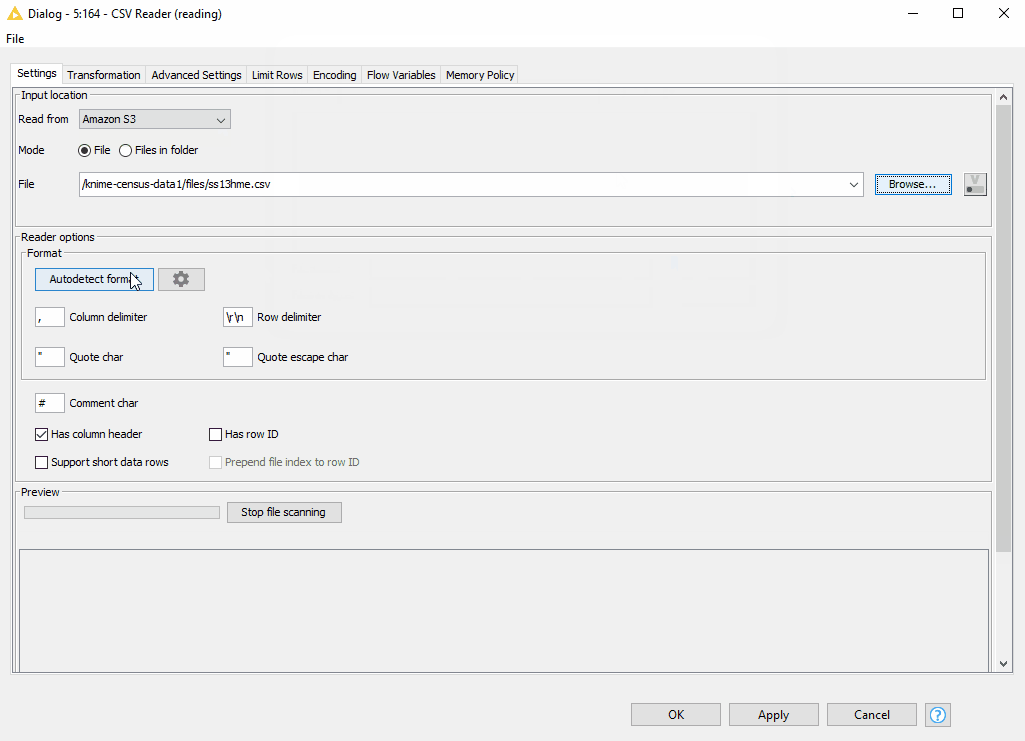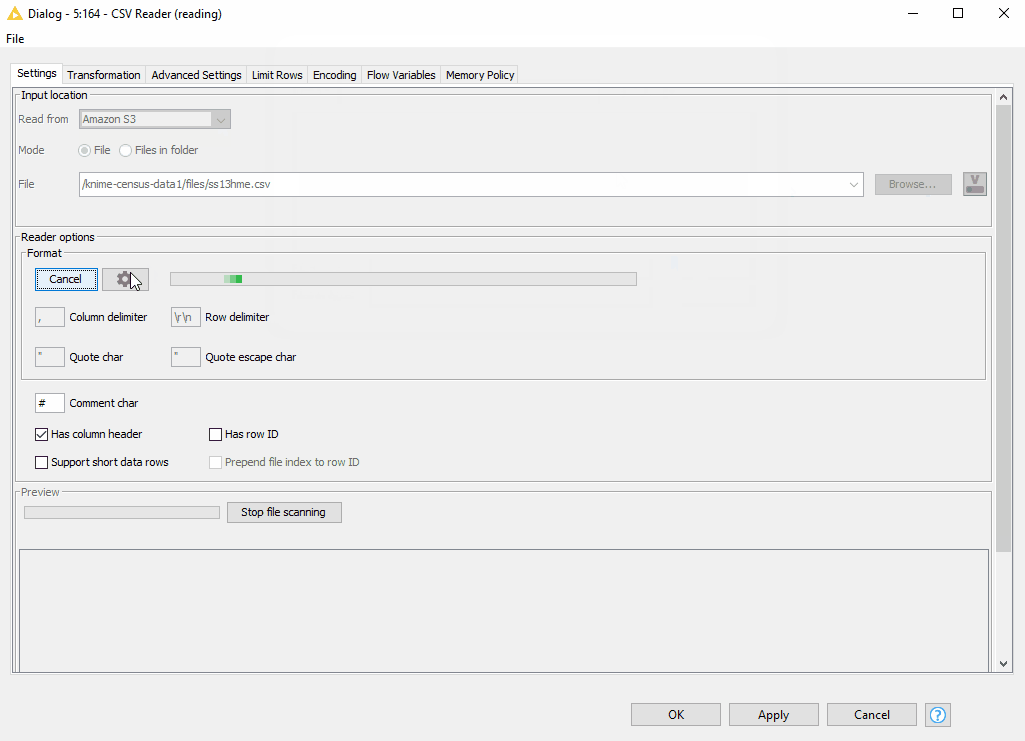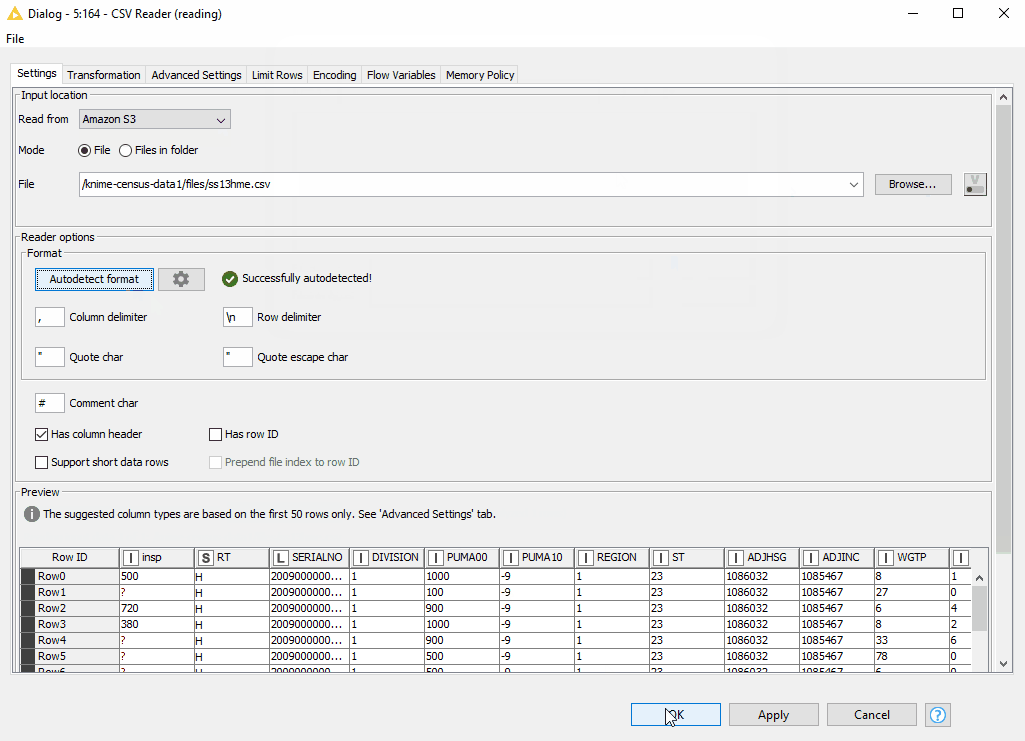
Figure 9. Browsing over the folders on S3 and autodetecting the format in the configuration the CSV Reader node
- We have now successfully read the data from Amazon S3.
- Note that even though configuration of the Microsoft Authentication node is slightly different from the Amazon Authentication node (figure 10), configuring the Azure Blob Storage Connector and the CSV Reader nodes is identical to configuring similar nodes we used to connect to and read from the S3. This is what we call consistency!
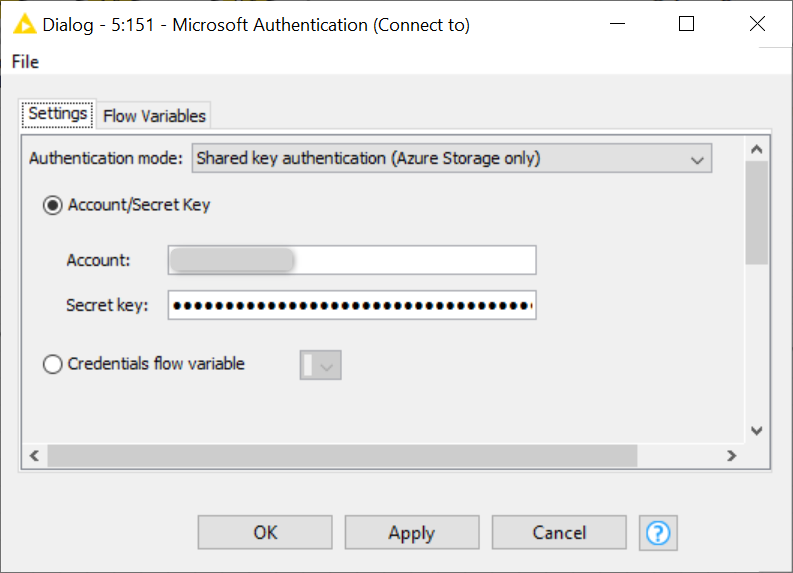
Figure 10. Configuration of the Microsoft Authentication node
Additional advantages of the new File Handling in this example
You might have noticed that the new File Handling allows you to specify the path to the file twice: in a Connector and in a Reader node. Providing a working directory, specific for this particular file system in the Connector node and a universal path or simply a file name in the Reader node allows you to easily switch between the different file systems.
Let’s imagine that we now have both our files on Azure Blob Storage. In order to access the file from the new file system, all we need to do is to change the connection to the CSV Reader from Amazon S3 Connector to Azure Blob Storage Connector! No other adjustments are needed (figure 11).
In case you provided a more specific path in the Reader node, simply browse your file again in the configuration of the Reader node.
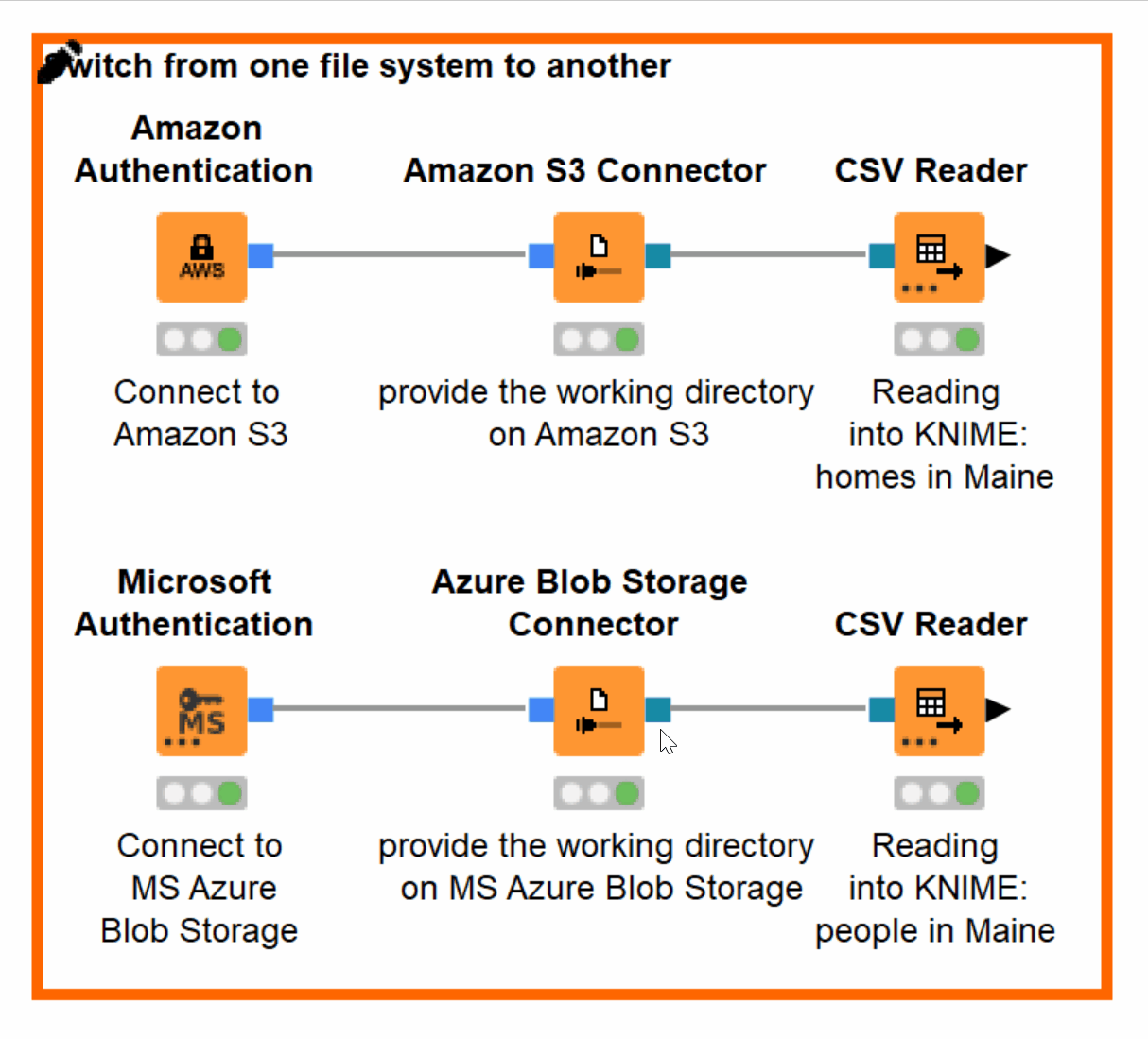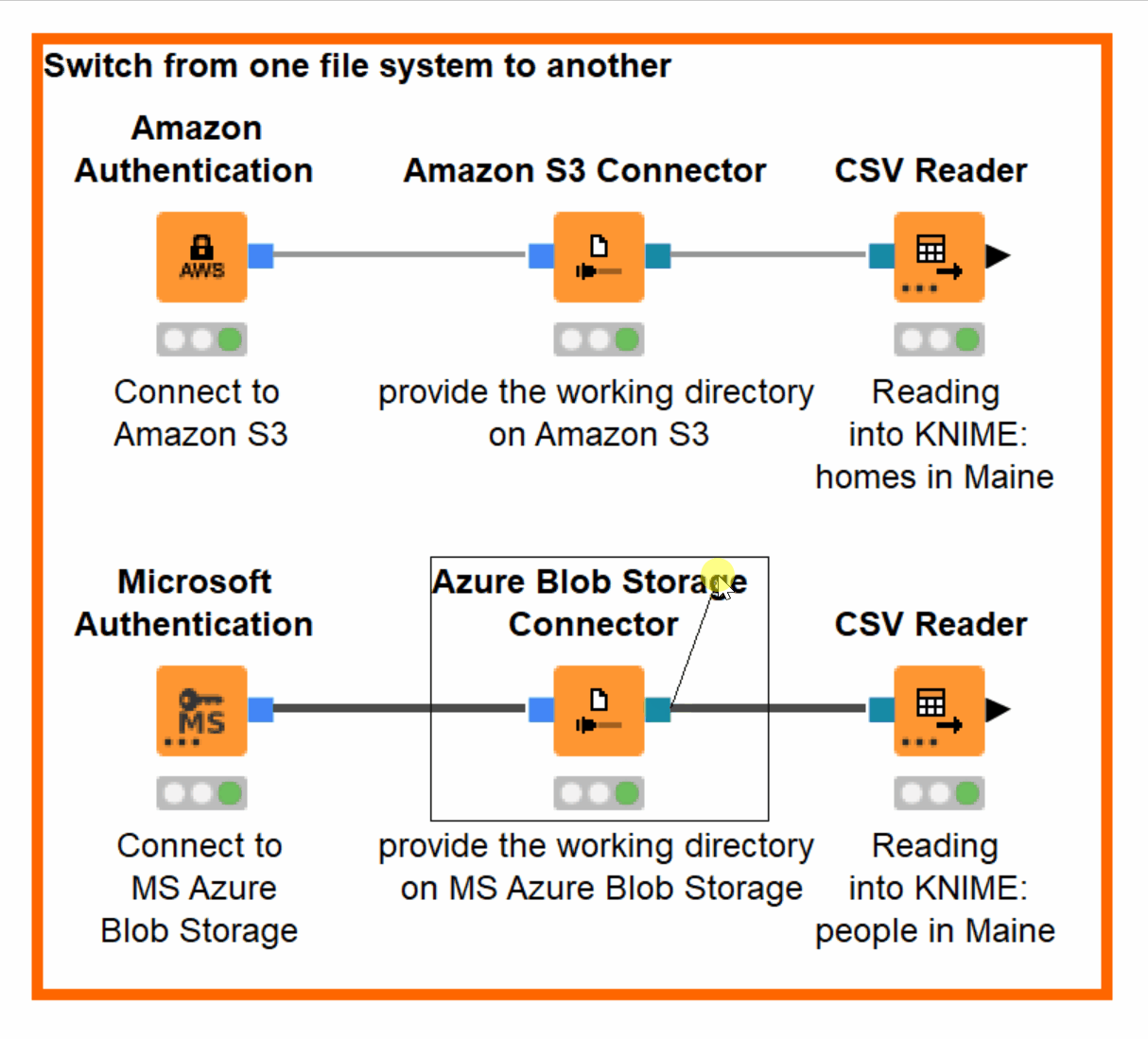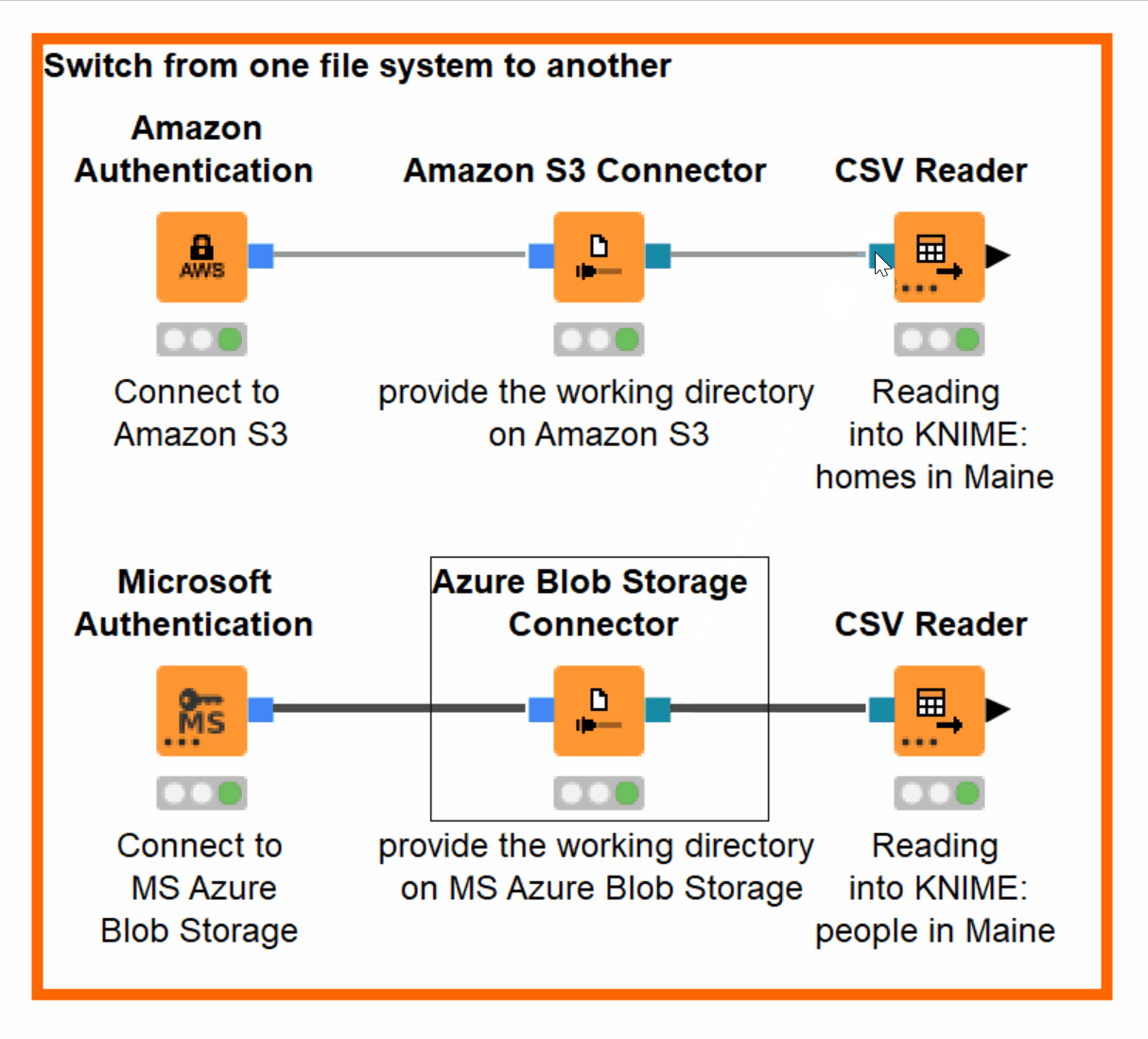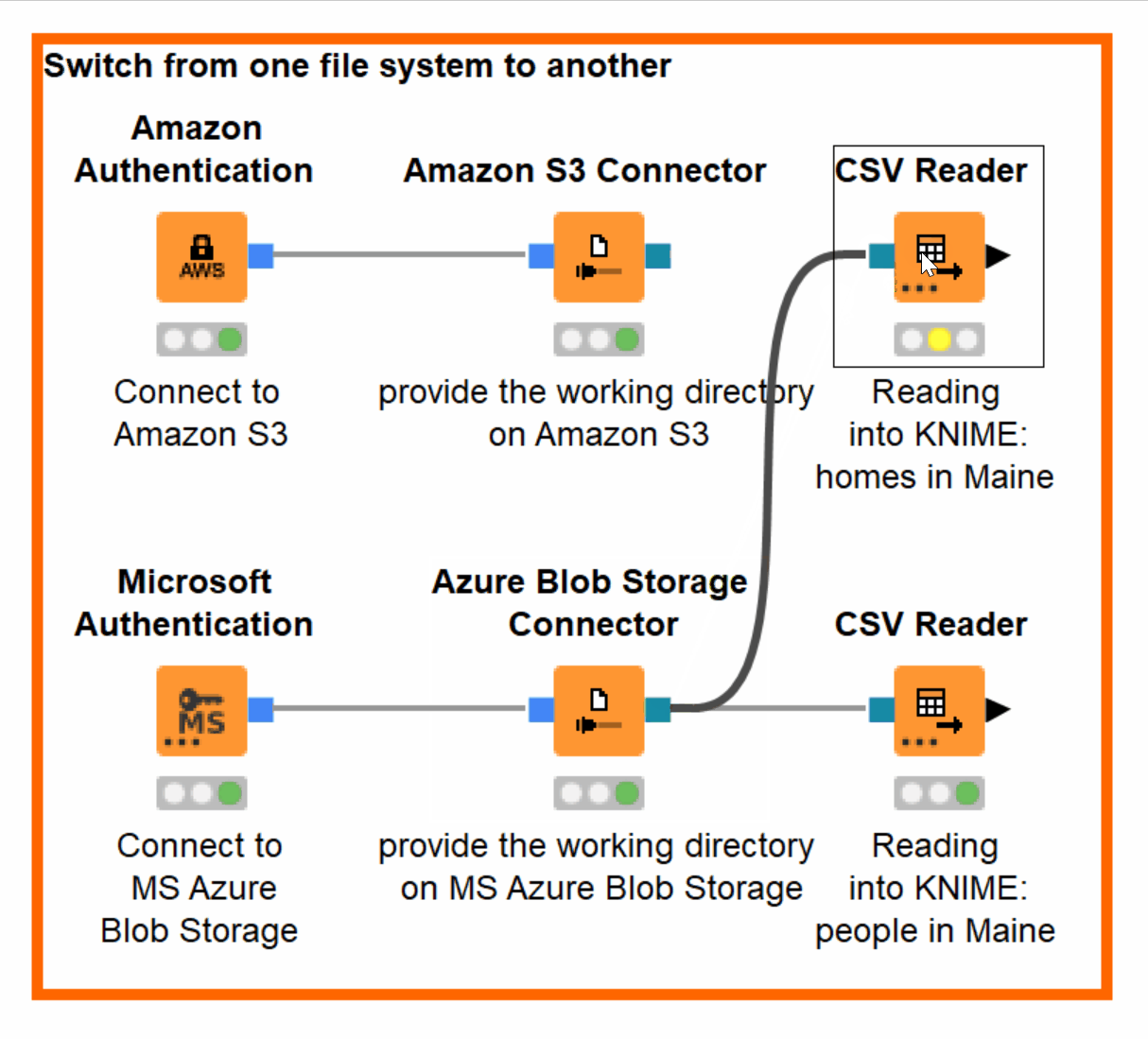
Figure 11. Switching from Amazon S3 to Azure Blob Storage without adjustments in configuration when accessing the same file
You can find another example of blending two connected file systems with the new File Handling nodes in the blog post Will They Blend? Microsoft SharePoint meets Google Cloud Storage.
Accessing file systems and web services on the example of Amazon S3 and DynamoDB
Our next example is based on the workflow Amazon S3 meets DynamoDB, which you can download from the KNIME Hub to try out yourself.
We would like to show here:
- How the new File Handling simplifies the connection to file systems and cloud services provided by the same platform
You might already know that KNIME provides various extensions for cloud services, for example, KNIME Amazon DynamoDB Nodes and KNIME Amazon Machine Learning Integration. And there will be more in the future. The new File Handling Framework simplifies the connection to file systems and cloud services provided by the same cloud platform - an additional advantage of replacing deprecated Connection and File Picker nodes with the new File Handling nodes.
In the following example workflow:
- We connect to Amazon providing credentials only in the Amazon Authentication node.
- Next, using the blue authentication port, we connect both to Amazon S3 and Amazon DynamoDB (figure 12)
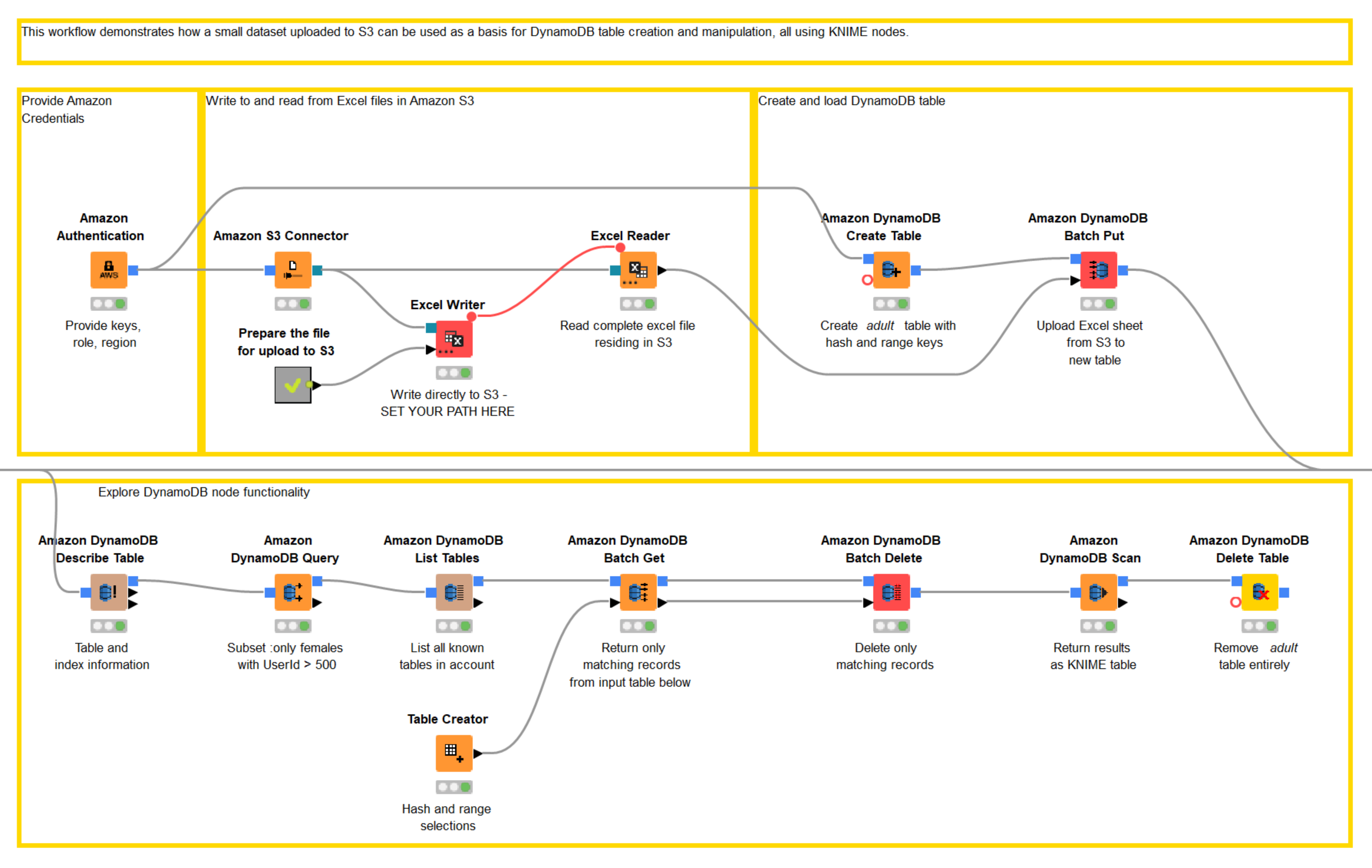
Figure 12. A workflow to access data via S3, load the data into a DynamoDB table, and perform various ETL operations on that table. The workflow can be downloaded from the KNIME Hub.
More details
For more details around this example workflow we suggest looking up the blog post Amazon S3 meets DynamoDB: Combining AWS services to access and query data.
Reducing the complexity on the example of local and remote archived files
Our next example is based on the workflow, Local vs Remote Archived file where we access two compressed CSV files, which contain flight data. The data for 2007 are stored remotely on a public space at the KNIME Hub; the 2008 data are stored locally. The new File Handling allows us to reduce complexity in several ways simultaneously (figure 13).
Here we want to show:
- There is now no need to download the remote file
- The new CSV Reader node supports reading compressed CSV files in .csv.gz format
- There is no need to send the paths as flow variables from one node to another – this job is conveniently performed by the new dynamic connection ports
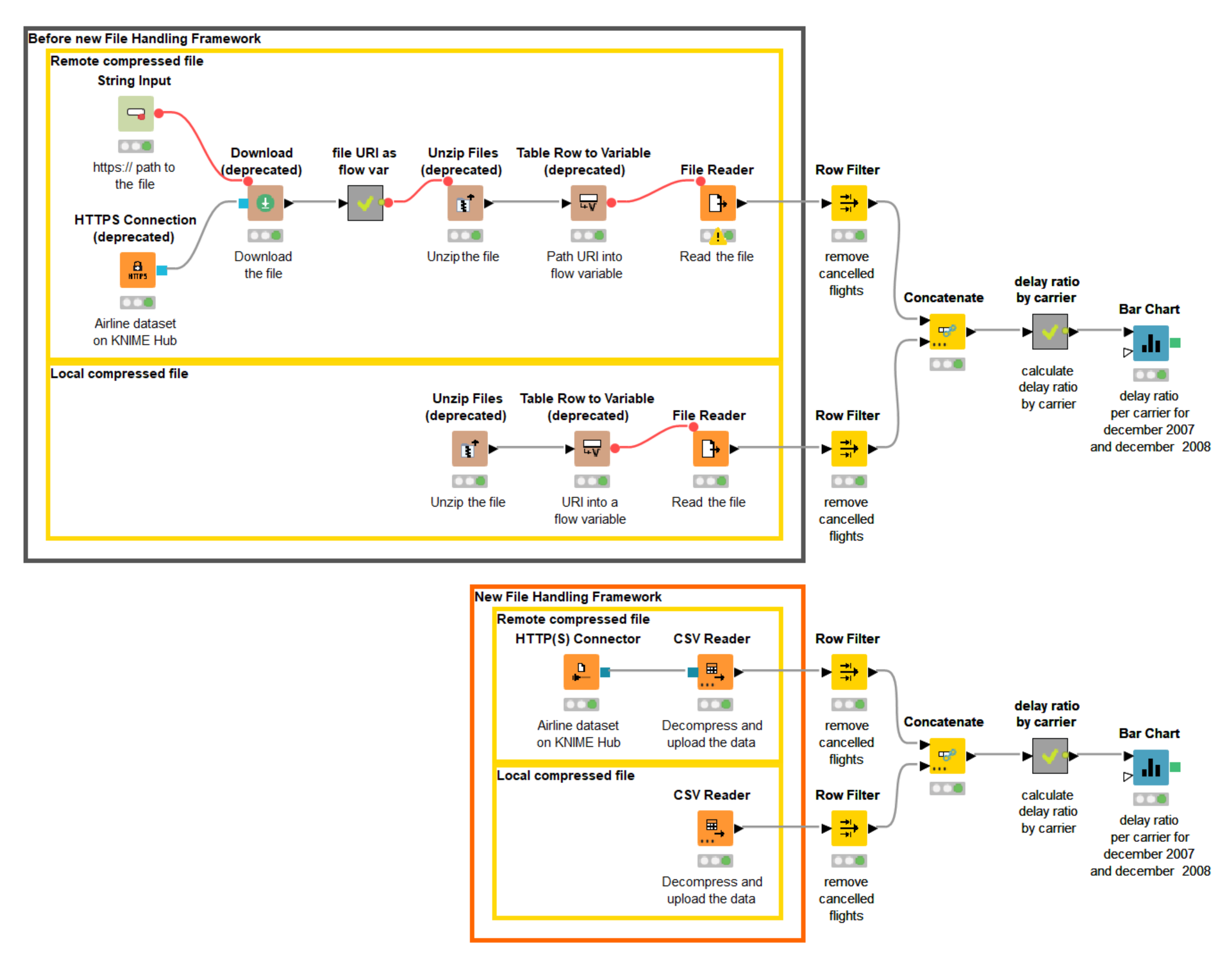
Figure 13. The workflow blends archived CSV files from a local and a remote location. The workflow can be downloaded from the KNIME Hub.
We have already seen the example of how the new CSV Reader node can connect to the cloud file systems. Now let’s get from clouds back to earth and see how to read the files on the standard file systems (figure 14).
Reading files on standard file systems
- First of all, instead of writing a workflow relative path, we can specify the option to “Read from” the “Current workflow data area”.
- Next, in the File field, we just need to provide the file name and extension. And of course, we can preview the data.
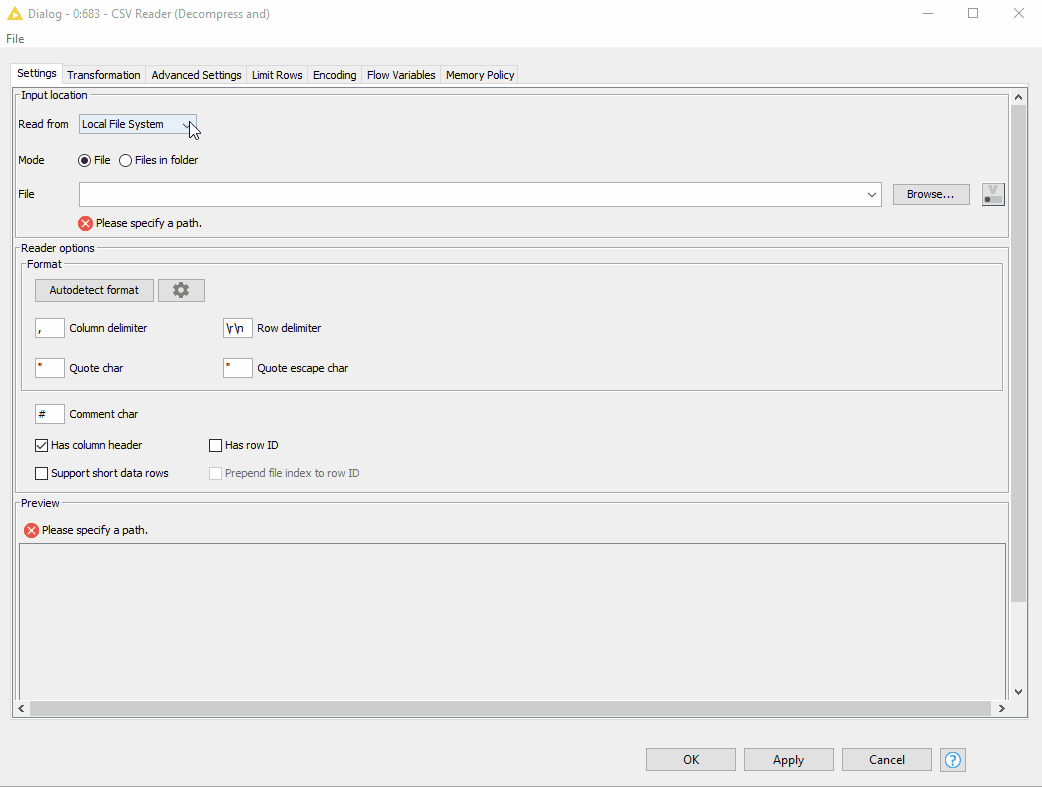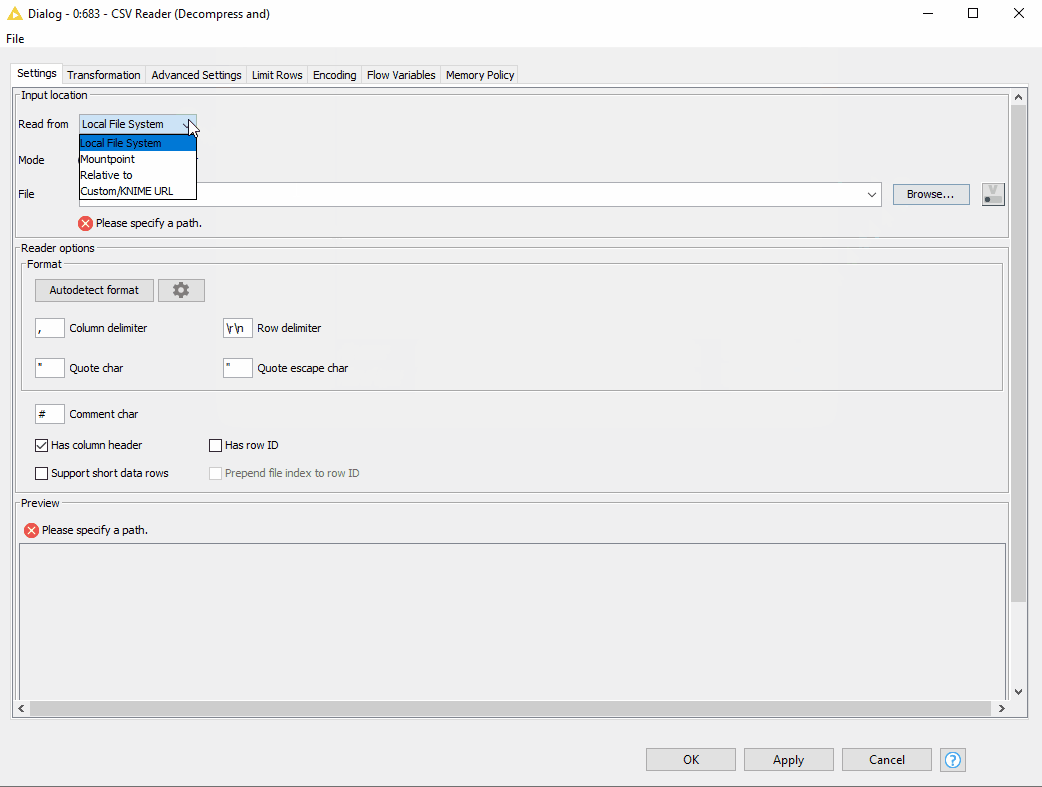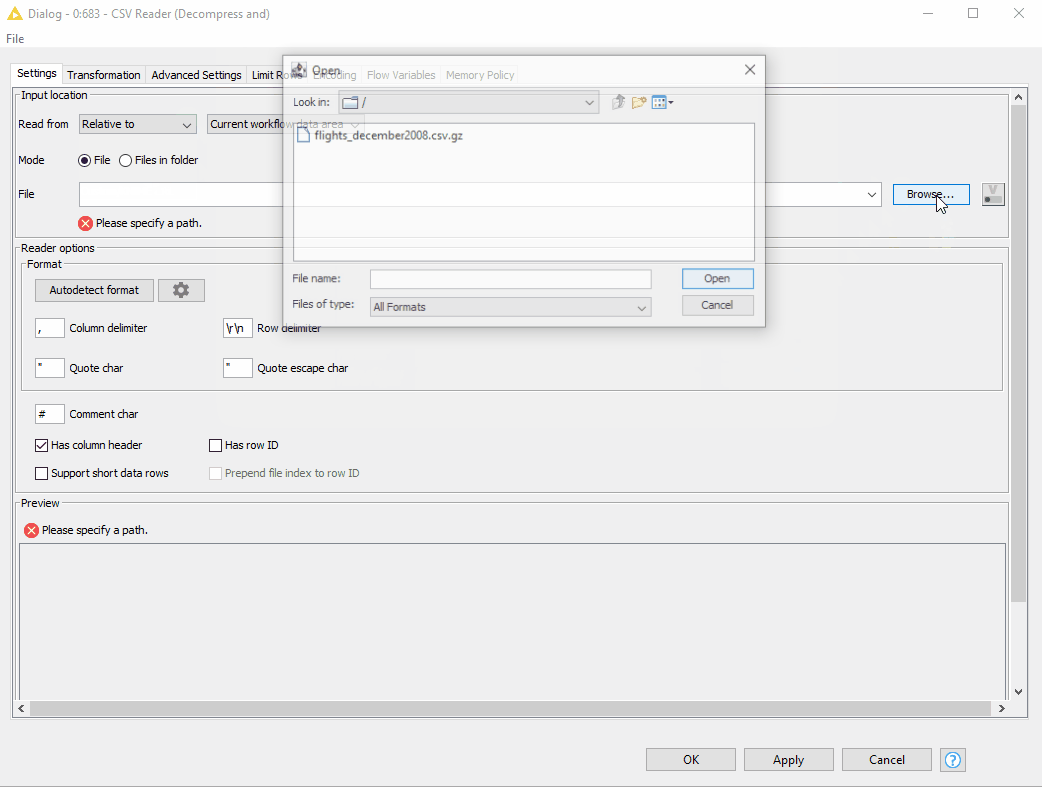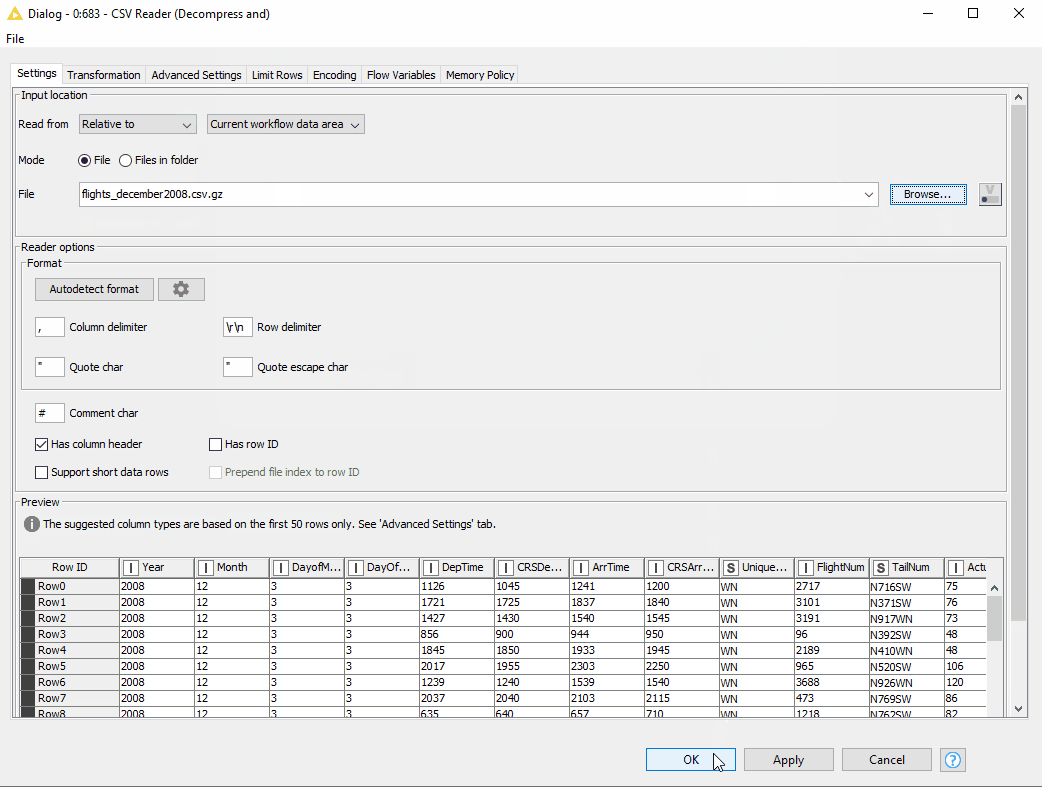
Figure 14. Reading compressed CSV file located in the current workflow data area
Accessing remote files is now much easier as well. Via the new dynamic port, you can easily connect not only to the major cloud platforms, for which the dedicated connectors are available, but also to any remote host. Thus, we can connect to any website, in our case – to the KNIME Hub – using the HTTP(S) Connector node.
Easy configuration
- Provide just a URL to the website where the file is located. No need to specify host and port (figure 15)
- After successfully connecting to the remote host, the “Read from” option is automatically switched to “HTTP” in the CSV Reader node configuration (figure 16). Now, we just need to specify the name of the file.
- Now we can also preview the content from the web site directly in the CSV Reader node - without needing to download the file!
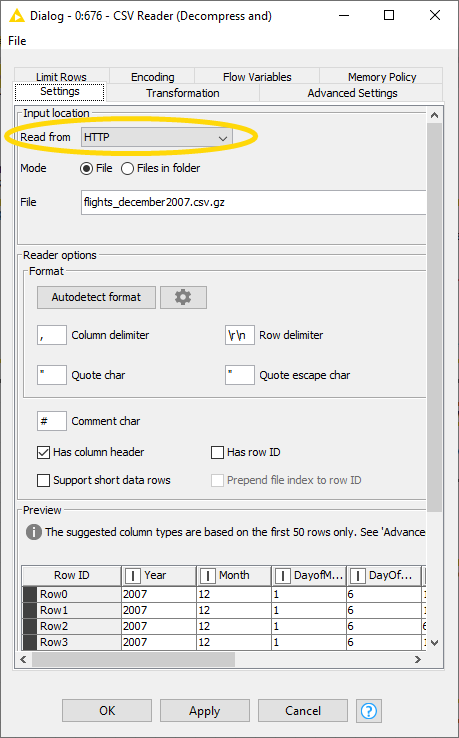
Figure 15. Connecting to the KNIME Hub with the HTTP(S) Connector node
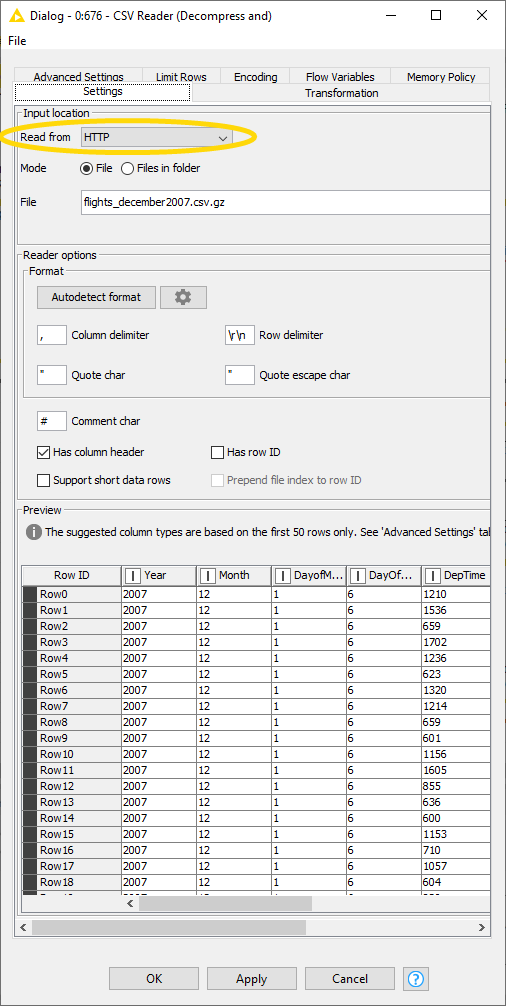
Figure 16. Reading the file from the KNIME Hub with the CSV Reader node
Summary
While providing the same results, the new File Handling Framework has allowed us to significantly reduce the complexity: We need just one node instead of three to read the compressed CSV file; the number of nodes needed to read the compressed CSV file located remotely is just two instead of eight. We are impressed!
Reducing complexity for example when reading multiple Excel files and data transformation
One of the nicest features of the new Reader nodes is the opportunity to avoid looping multiple files if the files have similar column structures. In our next example, we would like to read some data on invoices. As an input data we have a ZIP archive with multiple Excel files containing the data on invoices for customers from different countries as well as two files with some metadata in different formats. After reading, we want to clean and transform the data a bit to analyze the receivables status.
Here we would like to show how the new File Handling framework again allows us to reduce complexity in several ways:
- How to use the Decompress Files node for automatic folder creation
- How to use the new Excel Reader node for reading multiple files in the selected folder
- How to transform data before reading it into KNIME Analytics Platform
Decompress Files node
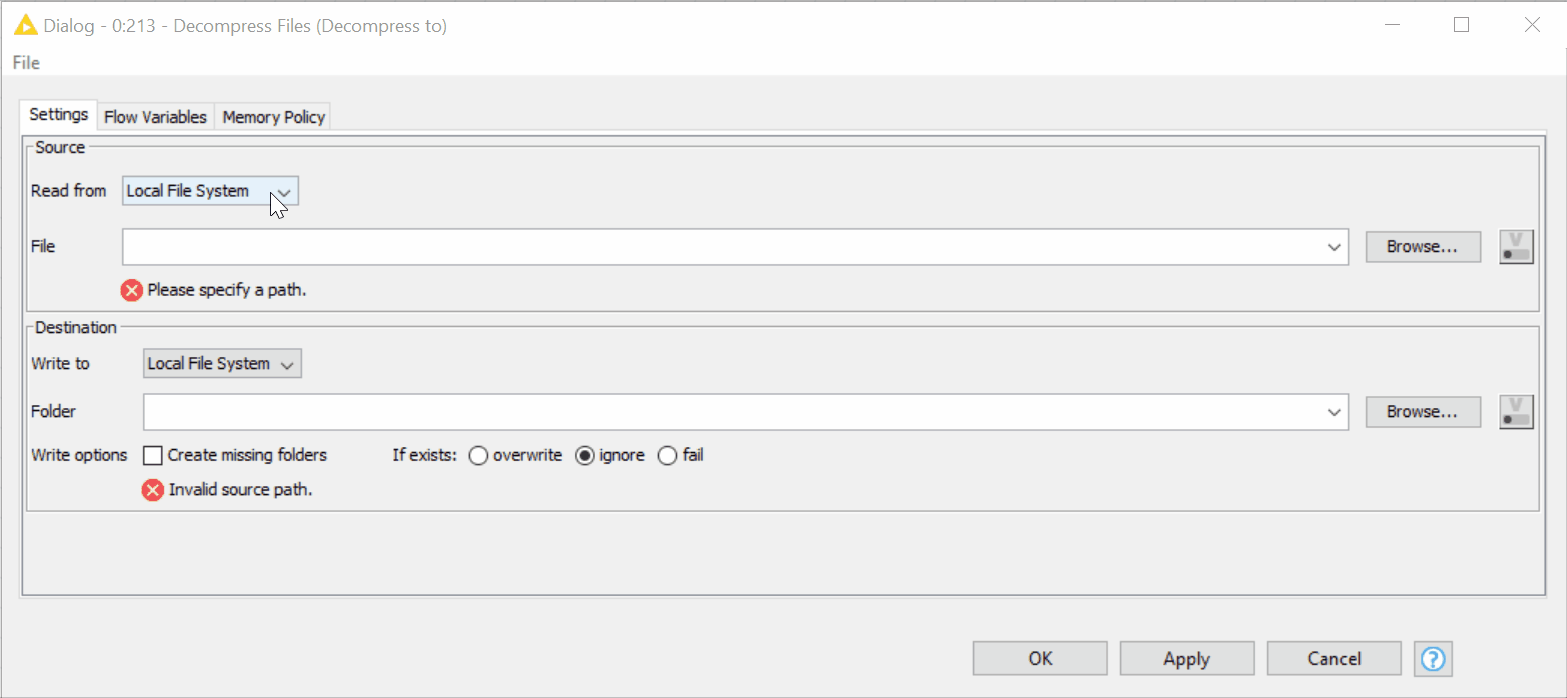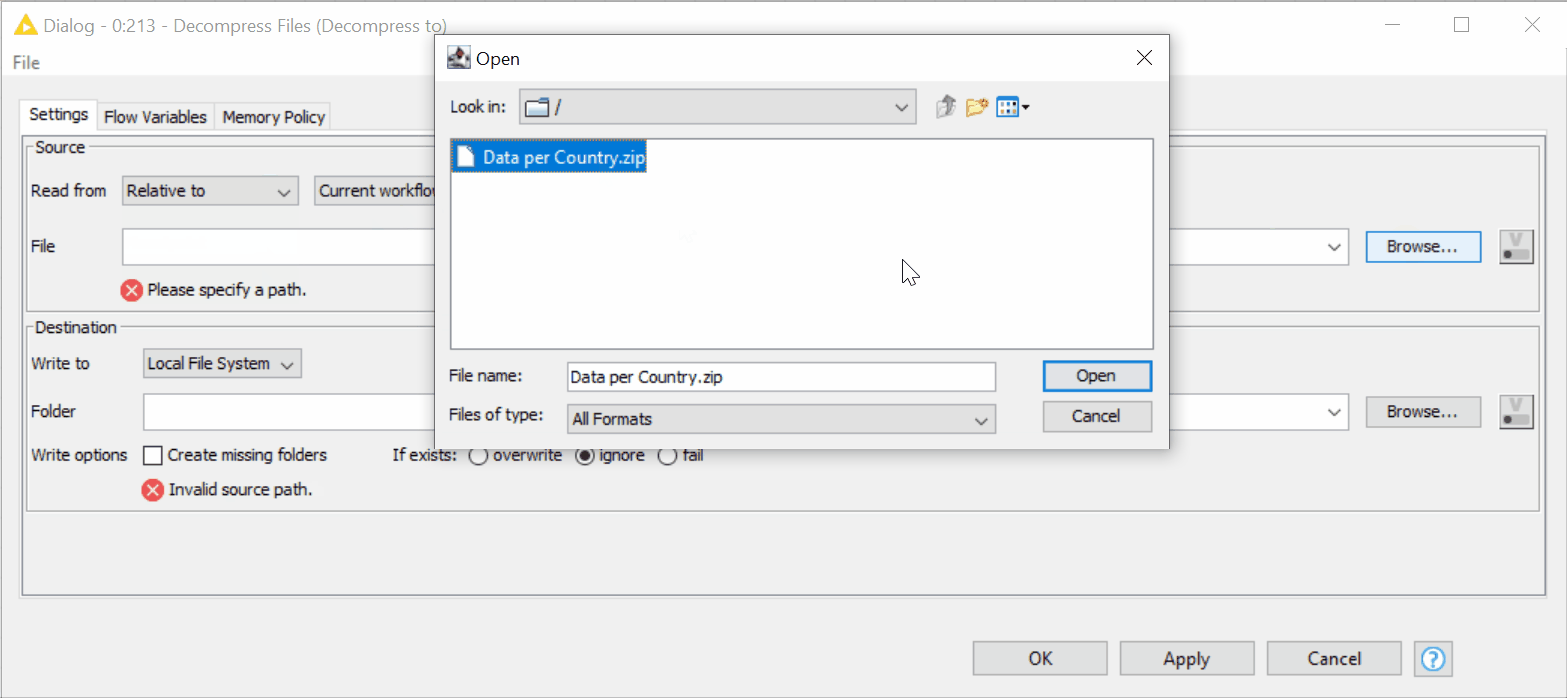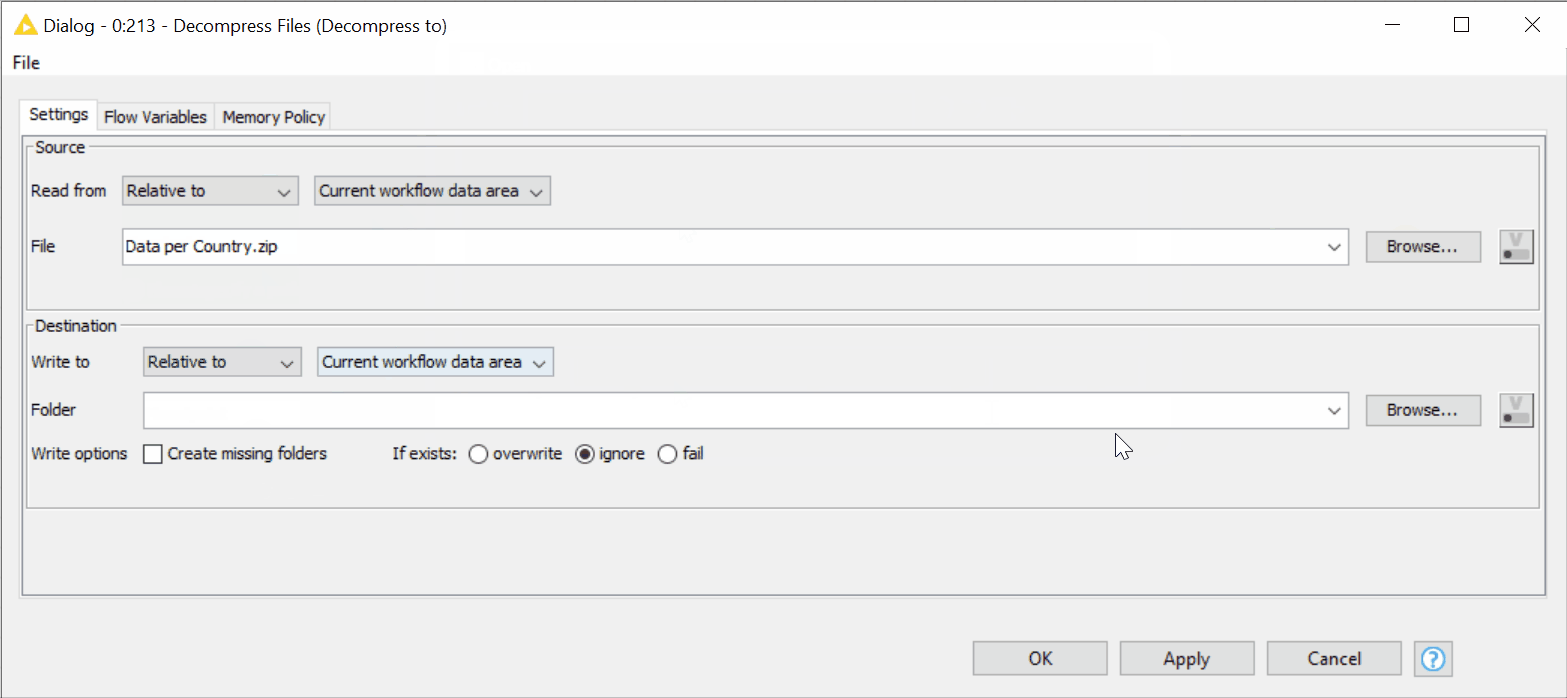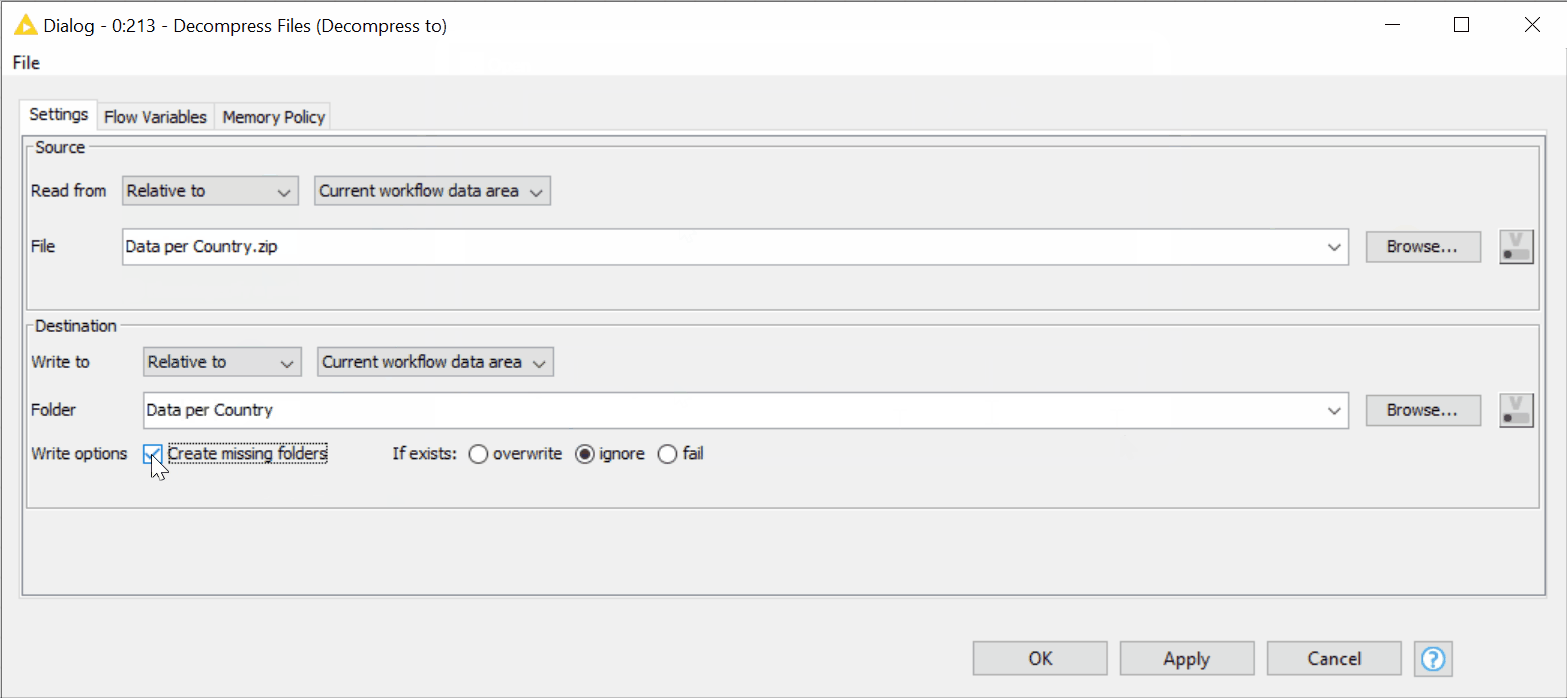
The new Decompress Files node can automatically create a new folder where the decompressed files will be saved. We simply:
- Check the box “Create missing folders”; there is no need to create the directory first.
- Both source and destination paths in the Decompress Files node can be provided using the new “Read from” and “Write to” options (figure 17).
The Excel Reader node
As all the Excel files have similar columns, we don’t need to loop the reading process – the Excel Reader node elegantly reads multiple files in the selected folder. The embedded option to filter the files allows you to filter by extension or name (figure 18).
Transform the data before reading it into KNIME
Yes! We can now transform the data before reading it into KNIME Analytics Platform! In our example, in order to analyze the receivables status:
- We don’t need the personal data of managers, therefore we would like to remove the respective columns
- We would also like to rename some columns for better readability and reorder the data in a clearer way
- Finally, we would like to have our company ratings in the numeric format
→ The “Transformation” tab in the Excel Reader node allows you to implement this all without needing additional manipulation nodes (figure 18).
Tip. The functionality of the “Transformation” tab is also available for any number of KNIME data tables via the new Table Manipulator node.
While the old file handling framework can implement the same process and provide the same result, the new framework significantly simplifies the process by avoiding looping and increasing the functionality of both Utility and Reader nodes, and, thus, reducing the number of nodes from ten to just two nodes (figure 19).
Note. Most of the new table based Reader nodes support streaming execution and read the same data much faster than the predecessors.
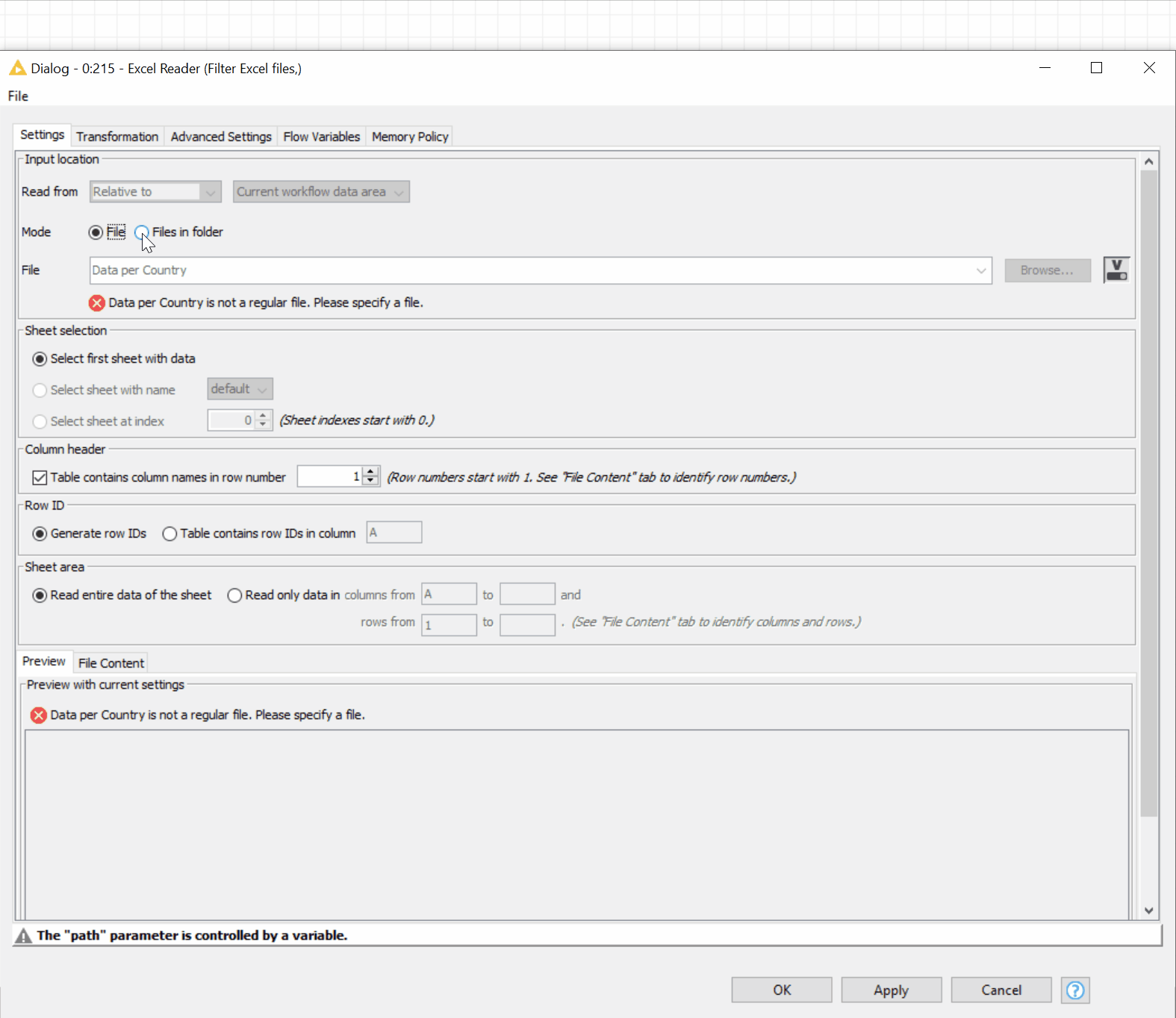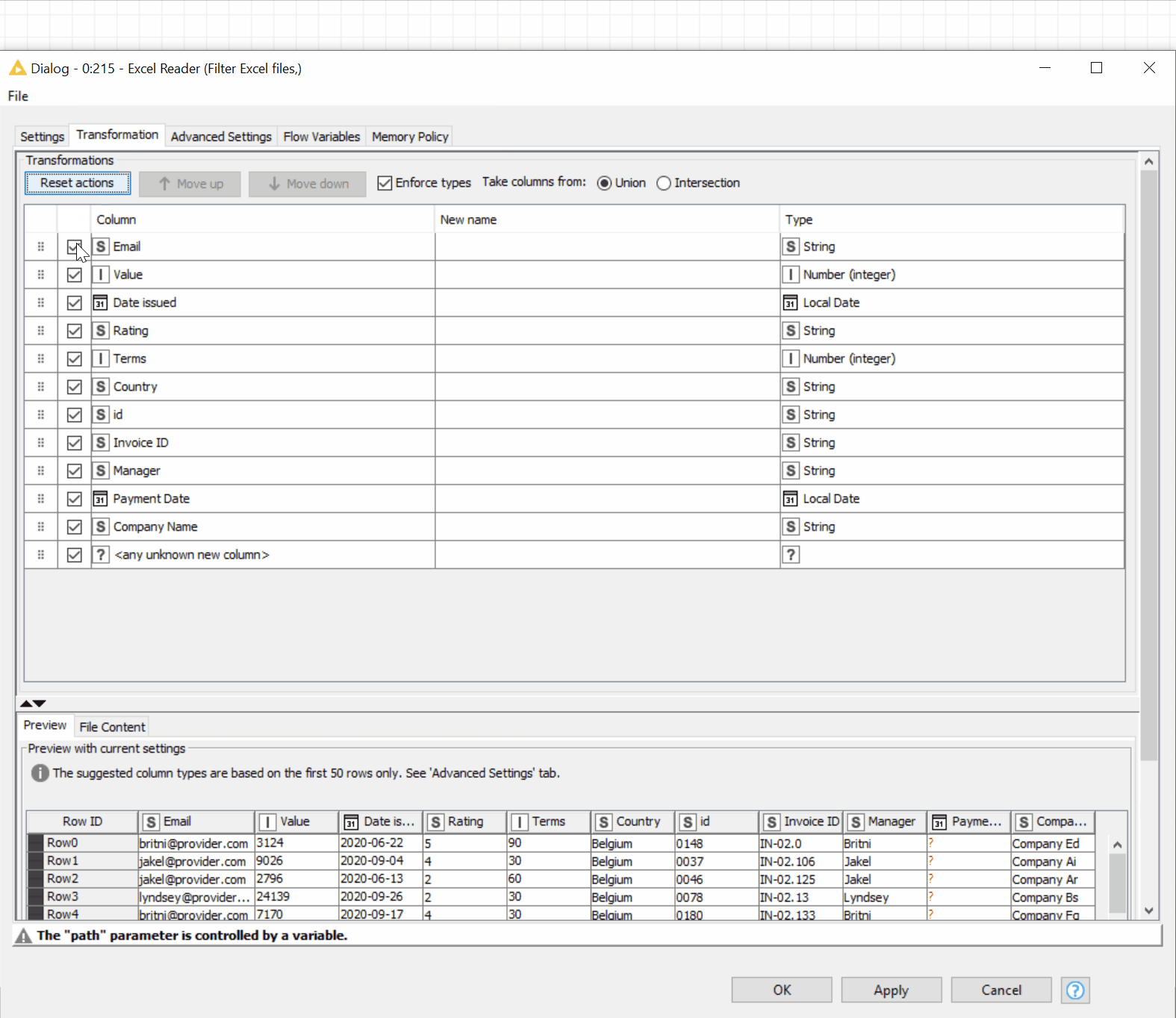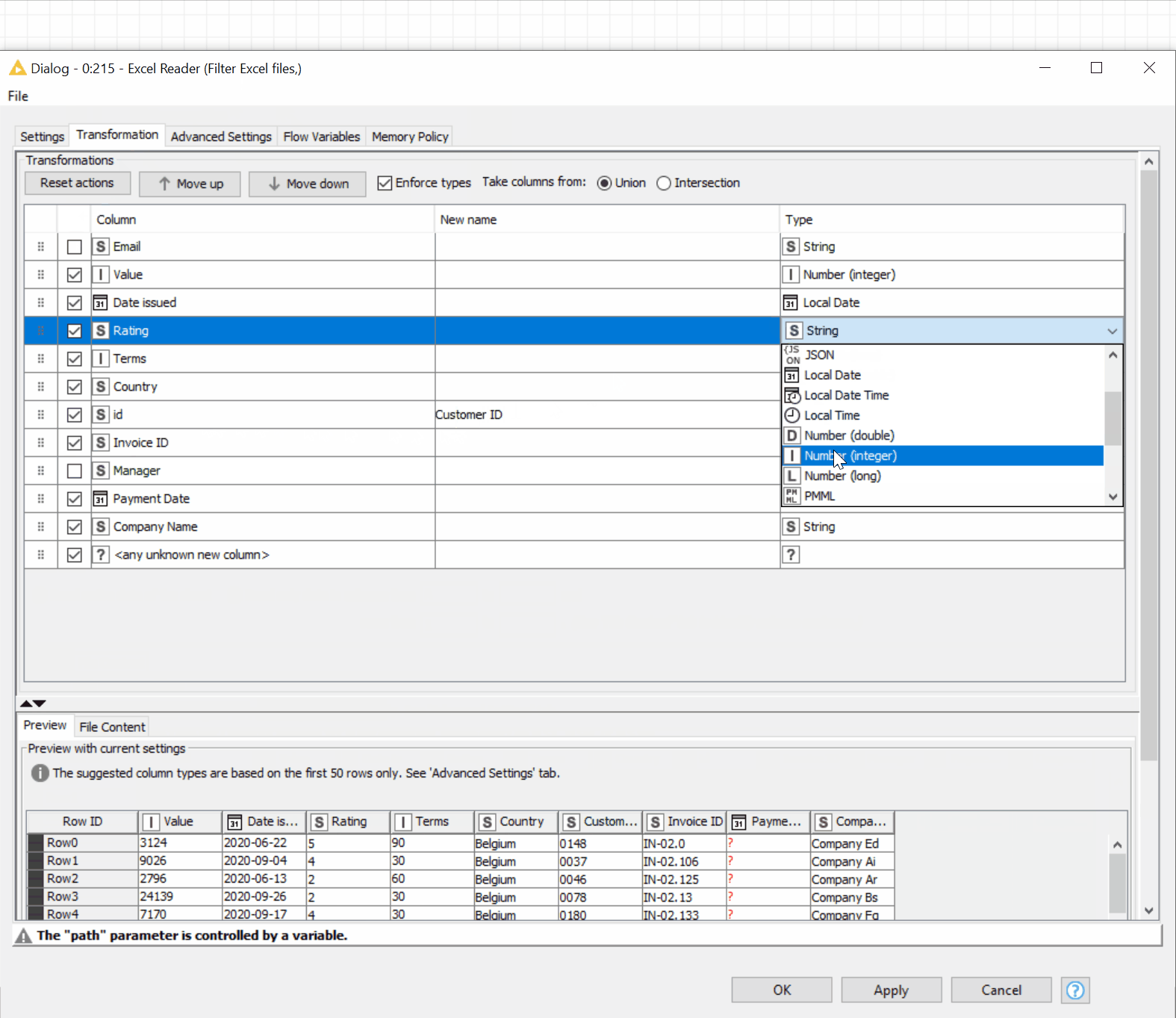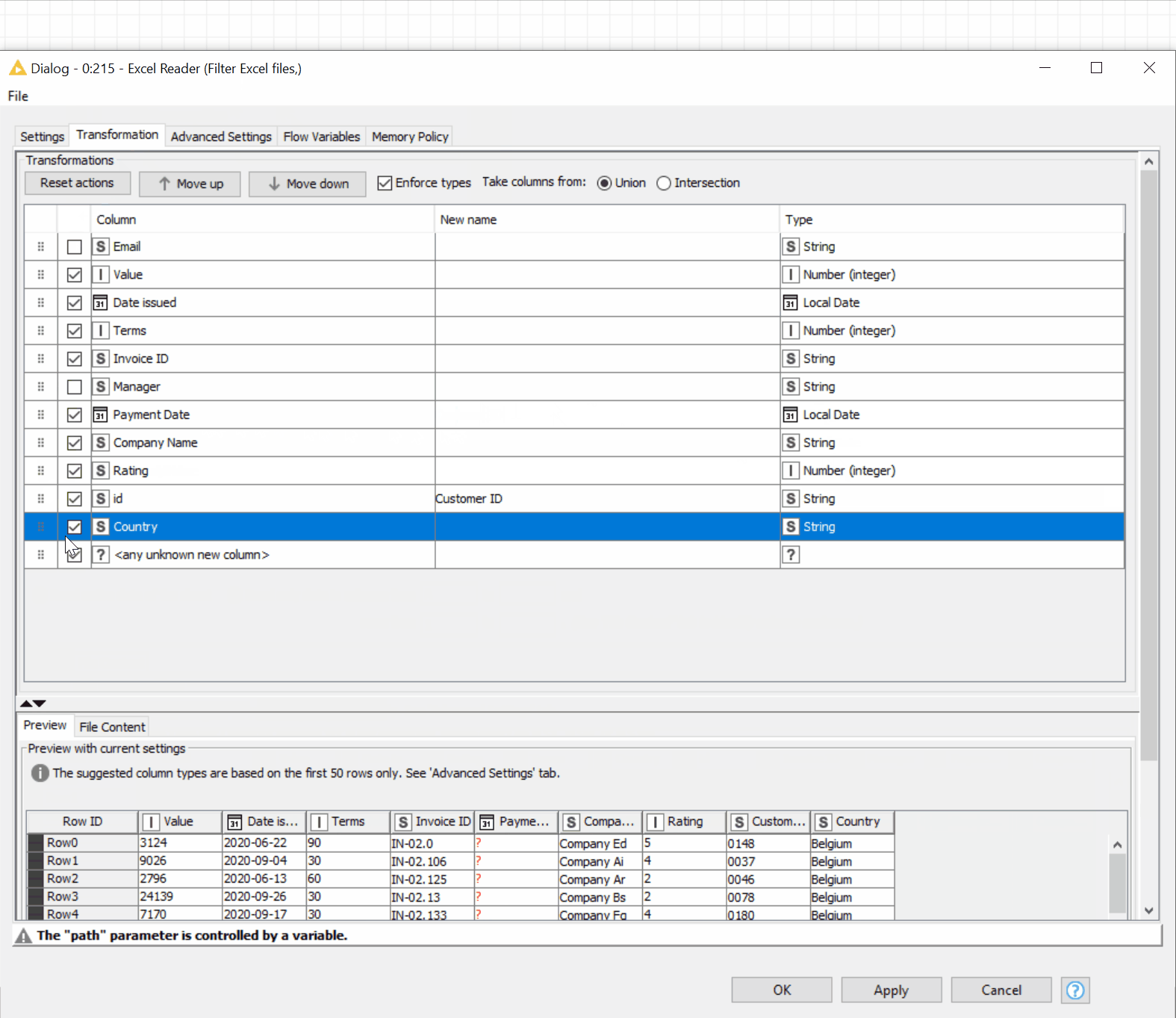
Figure 18. The new Reader nodes, e.g., Excel Reader, allow you to read multiple files in the folder and transform the data before reading
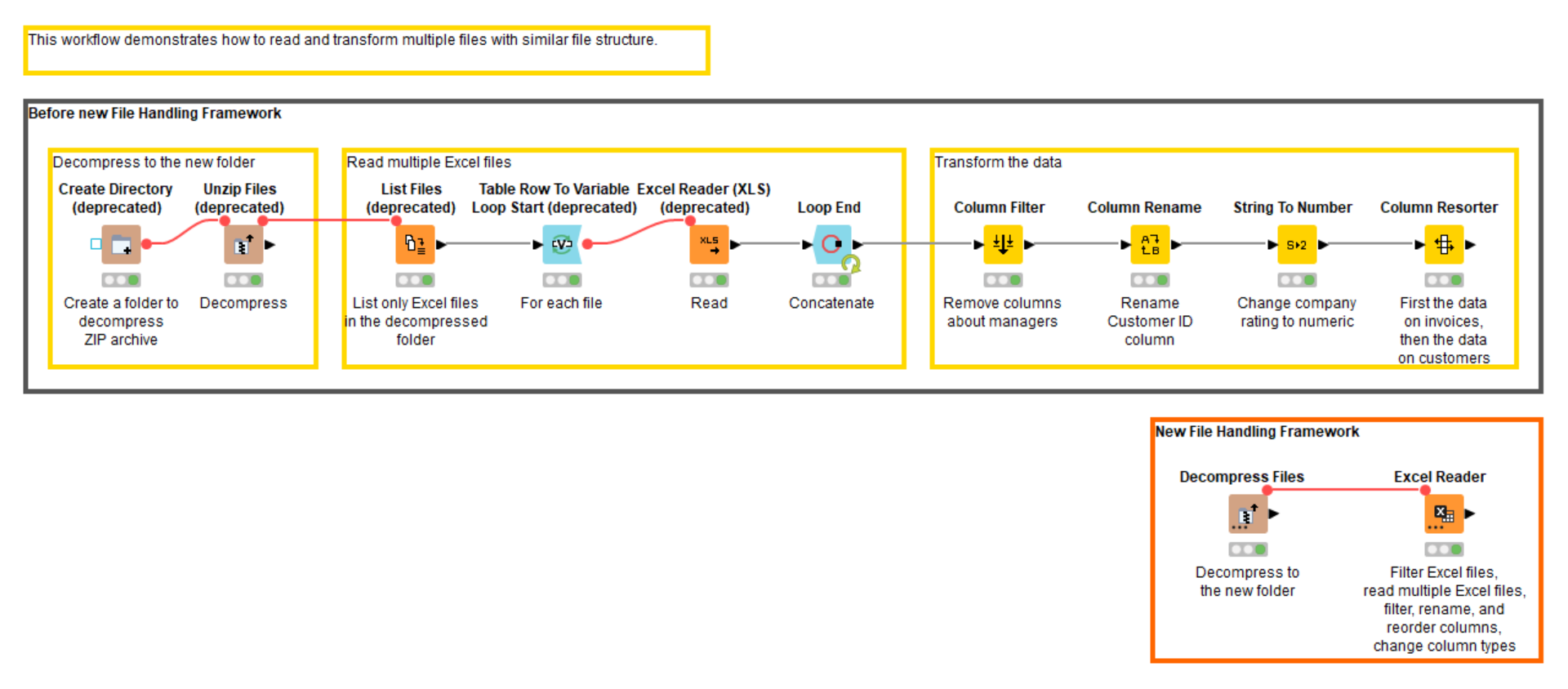
Figure 19. This workflow reads multiple Excel files from the ZIP archive and transforms the data before reading. The workflow can be downloaded from the KNIME Hub here
Conclusion
In this blog post, we provided an overview of the new File Handling framework and took a closer look at some of the new nodes in the example workflows. These examples cover only a few of the newly available functions, since one blog post is not enough to cover the whole functionality of the new framework. But these examples already show how powerful the new framework is in simplifying the file handling. The detailed documentation is already available here. More examples on the new Reader, Writer, and Utility nodes are coming soon.