
Obviously advanced analytics starts with an intuitive, yet powerful interface that allows data scientists to quickly explore different ways to blend and analyze their data. Even better, if those analysis workflows can be easily handed to others, as templates for their own analysis needs. However, when the analysis is being deployed or the results are used for business critical purposes it becomes essential that we can repeat the analytical process and guarantee that the results stay the same. In order to truly productionize advanced analytics, reproducibility is a key requirement.
Writing custom code or relying on a mix of different tools makes this complicated – changes in underlying packages or libraries can interfere with reproducibility to an extent that running the very same script produces widely different results (or no results at all – which is a tiny bit better since then you at least know that the results aren’t the same). Proprietary tools sometimes promise reproducibility but you simply have to trust the vendor.
KNIME takes a different stance here. First off, due to the platform being open, you can always inspect what’s going on underneath the hood. But just being open source is not enough to guarantee reproducibility. KNIME also makes sure that whenever any of the modules change in any way, the previous version of that module is carefully deprecated but remains part of the platform. When one loads an older workflow that used one of those now deprecated nodes, the workflow will, in fact, load that older version of the node. The example in the figure below shows what this looks like: the label tells the user that a previous version of the Naïve Bayes Learner/Predictor nodes are used (in this case we changed the implementation to support the PMML representation in the newer versions when PMML 4.2 finally supported numerical attributes).
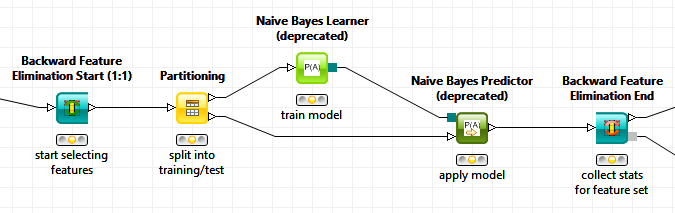
This way KNIME guarantees that the exact same results will be produced as when this workflow was first created. The user is free to replace this deprecated version with a newer one, of course, but this manual alteration of the workflow will potentially modify the output of the workflow – in this case it is only the model, of course. We do this for all our nodes, complex analytical ones and simple data preprocessing nodes. In the example above, clearly the change of model representation should not change the outcome (and our development team tested this hard and swears nothing changed) but since we cannot formally prove this to be true, the old version was kept intact and deprecated.
So if you see “deprecated” on top of a node in KNIME, don’t take this as a bad sign. Read this as a promise that KNIME will not change anything in the way it processes your data without telling you about it. As a matter of fact, the build&test system at KNIME still runs hundreds of KNIME workflows from release 1.0. We have removed or changed not a single one of those over the years.