
In this blog series we’ll be experimenting with the most interesting blends of data and tools. Whether it’s mixing traditional sources with modern data lakes, open-source devops on the cloud with protected internal legacy tools, SQL with noSQL, web-wisdom-of-the-crowd with in-house handwritten notes, or IoT sensor data with idle chatting, we’re curious to find out: will they blend? Want to find out what happens when IBM Watson meets Google News, Hadoop Hive meets Excel, R meets Python, or MS Word meets MongoDB?
Today: Twitter meets PostgreSQL. More than idle chat?
The Challenge
Today we will trespass into the world of idle chatting. Since Twitter is, as everybody knows THE place for idle chatting, our blending goal for today is a mini-DWH application to archive tweets day by day. The tweet topic can be anything, but for this experiment we investigate what people say about #KNIME through the word cloud from last month’s tweets.
Now, if you connect to Twitter with a free developer account, you will only receive the most recent tweets about the chosen topic. If you are interested in all tweets from last month for example, you need to regularly download and store them into an archive. That is, you need to build a Data WareHousing (DWH) application to archive past tweets.
As archival tool for this experiment, we chose a PostgreSQL database. The DWH application at the least should download and store yesterday’s tweets. As a bonus, it could also create the word cloud from all tweets posted in the past month. That is, it should combine yesterday’s tweets from Twitter and last month’s tweets from the archive to build the desired word cloud.
Summarizing, on one side, we collect yesterday’s tweets directly from Twitter, on the other side we retrieve past tweets from a PostgreSQL database. Will they blend?
Topic. What people say about #KNIME on Twitter.
Challenge. Blend together tweets from Twitter and tweets from PostgreSQL database and draw the corresponding word cloud.
Access Mode. Twitter access and Database access.
The Experiment
Defining the Time Frame.
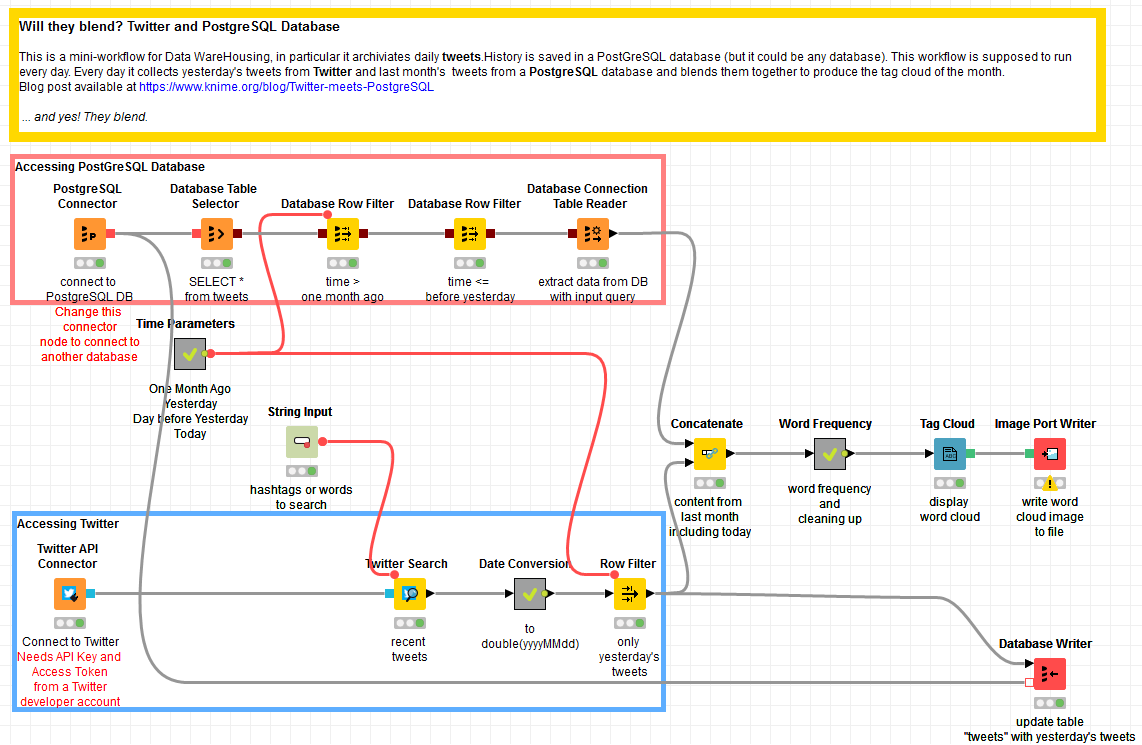
- The metanode named “Time Parameters” creates a number of flow variables with the date of today, yesterday, the day before yesterday, and one month ago. These parameter values will be used to extract the tweets for the word cloud.
Accessing Twitter.
- First of all, we created a Twitter developer account at https://apps.twitter.com/. With the creation of the account, we received an API Key with API Key secret and an Access Token with Access Token secret. Let’s remember those, because we will need them to connect to Twitter and download the tweets. Details on how to create a Twitter developer account can be found in this past KNIME blog post.
- In a new workflow, we created a Twitter API Connector node to connect to Twitter using the API Key and the Token Access we got. We then used a Twitter Search node to download all tweets around a given topic: the hashtag #KNIME. This topic string is generated by the String Input Quickform node as a flow variable and passed to the Twitter Search node. After execution, this last node produces at its output port the most recent tweets on that topic, with tweet body, time, user, location, and other related information.
- After some time format conversion operations and a Row Filter node, only yesterday’s tweets are kept and saved in a table named “tweets” in a PostgreSQL database.
Accessing PostgreSQL database (or any database for that matter).
- PostgreSQL is one of the many databases with a dedicated connector node in KNIME Analytics Platform. This made our job slightly easier. To connect to a PostgreSQL database we used the PostgreSQL Connector node, where we provided the host URL, the database name, and the database credentials.
- The recommended way to provide the database credentials is through the Workflow Credentials. In the KNIME Explorer panel, right-click the workflow and select Workflow Credentials. Provide a credential ID, username, and password. Then in the PostgreSQL Connector node enable option “Use Credentials” and select the ID of the just created credential.
- Once the connection to the database had been established, we used a series of in-database processing nodes to build the SQL query for the data extraction, such as the Database Table Selector, to select table “tweets”, and two Database Row Filter nodes, to select the tweets in the archive posted between one month ago and the day before yesterday.
- The last node, Database Connection Table Reader node, runs the query on the database and exports the results into KNIME Analytics Platform.
Blending data from Twitter and PostgreSQL database.
- Now the workflow has yesterday’s tweets from Twitter and last month’s tweet from the PostgreSQL archive. The Concatenate node puts them together.
- After some cleaning and relative frequency calculation, the word cloud is built by the Tag Cloud node.
Scheduling on KNIME Server
- When the workflow was finished, it was moved onto the KNIME Server (just a drag & drop action) and there it was scheduled to run every day once a day.
Note. If you are using any other database, just change the connector node. In the category Database/Connector in the Node Repository, you can search for the connector node dedicated to your database of choice. If you use a not so common or an older version database and a dedicated connector is not available, use the generic Database Connector node. This should connect to all databases, provided that you have the right JDBC driver file.
The workflow that blends data from Twitter and PostgreSQL and builds this mini DWH application is displayed in figure 1 and is downloadable from the KNIME EXAMPLES server under 08_Other_Analytics_Types/04_Social_Media/01_Twitter_meets_PostgreSQL08_Other_Analytics_Types/04_Social_Media/01_Twitter_meets_PostgreSQL*.
Hint. Did you see the round connections? This is a preview of how connections between nodes could look like in the new KNIME Analytics Platform 3.3 to be released on Dec 6th. Are you ready? In case you are not, join our webinar “What is new in KNIME Analytics Platform 3.3” on Dec 13, 18:00 CET.
The Results
Yes, they blend!
The resulting word cloud for tweets posted between October 31st and November 24th 2016 and containing the hashtag #KNIME, is shown in figure 2. Looks familiar? If you have been at the KNIME Spring Summit 2016 in Berlin, this word cloud, built from the tweets containing hashtag #KNIMESummit2016, was projected during the event pauses. By the way, we will use this same workflow to generate the word cloud at the upcoming KNIME Spring Summit 2017 in Berlin on March 15-16, this time around the hashtag #KNIMESummit2017.
In the word cloud we notice the predominance of the hashtags #datascience, #data, #bigdata, and #datablending, which describe the whole span of the KNIME Analytics Platform realm.
Surprising are Microsoft Azure username and hashtag. They come from the tweets about the Microsoft Roadshow, which travelled across Europe in October and November and saw KNIME as one of the involved partners.
Another unexpected username is OReilly. This originates from tweets about the newly released and announced O’Reilly media course “Introduction to Data Analytics with KNIME”.

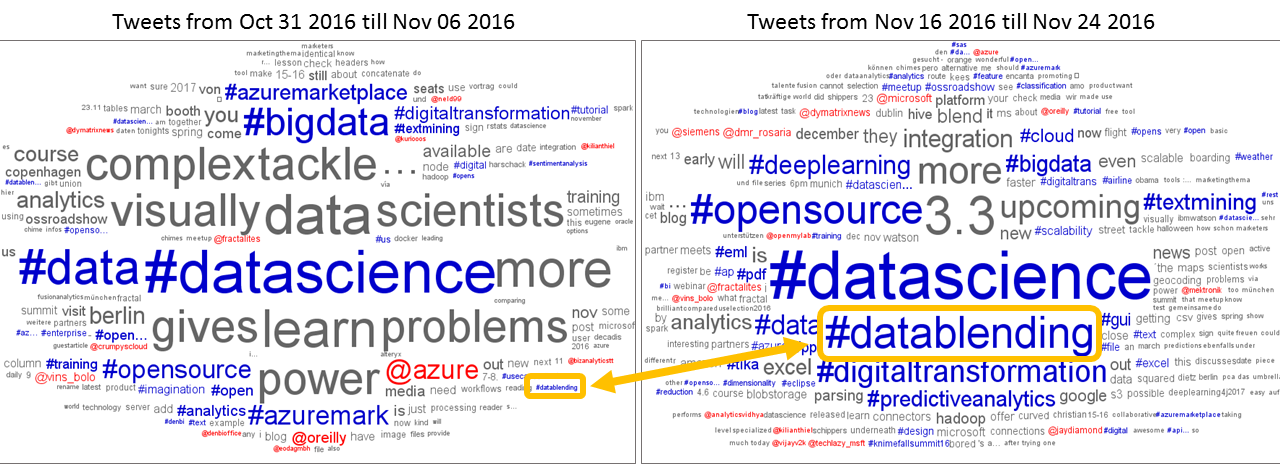
One word about the #datablending hashtag. It has not always been that prominent up there. Let’s compare, for example, the tag cloud of the first week in November – when the “Will they blend?” blog post series had just started – with the tag cloud of the week before last again in November, as in figure 3. You can see the growth of the hashtag #datablending, which directly reflects the impact of this blog series. Thanks for tweeting!
Any more words that surprise you in this word cloud? Did you find your username?
This word cloud is the proof of the successful blending of data from Twitter and data from a PostgreSQL database. The most important conclusion of this experiment is: Yes, they blend!
Coming Next …
If you enjoyed this, please share this generously and let us know your ideas for future blends.
We’re looking forward to the next challenge. There we will try to build a cross-platform decision tree ensemble, bringing together decision trees from KNIME Analytics Platform, R, and Python. Will they blend?
* The link will open the workflow directly in KNIME Analytics Platform (requirements: Windows; KNIME Analytics Platform must be installed with the Installer version 3.2.0 or higher)