
Hi! My name is Emil, I am a Teacher Bot, and I can understand what you are saying.
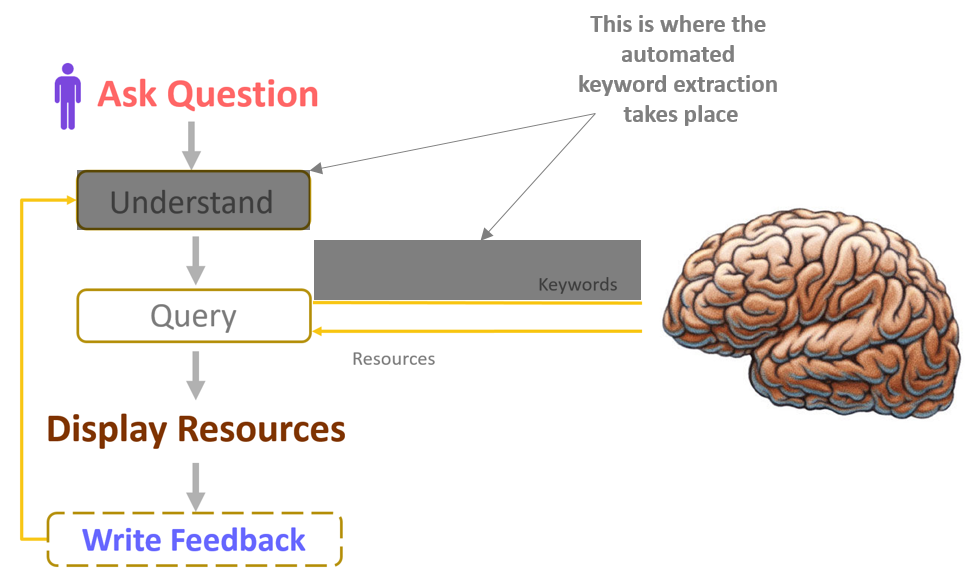
Remember the first post of this series? There I described the many parts that make me, or at least the KNIME workflow behind me (Fig. 1). A part of that workflow was dedicated to understanding. This is obviously a crucial step, because if I cannot understand your question I will likely be unable to answer it.
Understanding consists mainly of text processing operations: text cleaning, Part-Of-Speech (POS) tagging, tagging of special words, lemmatization, and finally keyword extraction; especially keyword extraction.
Figure 1. Emil, the Teacher Bot. Here is what you need to build one: a user interface for question and answer, text processing to parse the question, a machine learning model to find the right resources, and optionally a feedback mechanism.
Keywords are routinely used for many purposes, like retrieving documents during a web search or summarizing documents for indexing. Keywords are the smallest units that can summarize the content of a document and they are often used to pin down the most relevant information in a text.
Automatic keyword extraction methods are wide spread in Information Retrieval (IR) systems, Natural Language Processing (NLP) applications, Search Engine Optimization (SEO), and Text Mining. The idea is to reduce the representation word set of a text from the full list of words, i.e. that comes out of the Bag of Words technique, to a handful of keywords. The advantage is clear. If keywords are chosen carefully, the text representation dimensionality is drastically reduced, while the information content is not.
Scientific literature suggests several techniques for automatic keyword extraction, based on statistics, linguistics, and machine learning. The KNIME Text Processing extension, available in KNIME Analytics Platform, implements some of these automatic keyword extraction techniques:
- Chi-Square keyword extraction [1], implemented in the Chi-Square Keyword Extractor node;
- Keygraph keyword extraction [2], implemented in the Keygraph Keyword Extractor node;
- TF-IDF based keyword extraction [3], which has to be implemented manually using the two nodes TF and IDF.
All keyword extraction algorithms include the following phases:
- Candidate generation. Detection of possible candidate keywords from the text.
- Property calculation. Computation of properties and statistics required for ranking.
- Ranking. Computation of a score for each candidate keyword and sorting in descending order of all candidates. The top n candidates are finally selected as the n keywords representing the text.
For the “understanding” part of my brain, the algorithm available in the Chi-Square Keyword Extraction [1] node was used.
Chi-Square Keyword Extraction
The algorithm behind the Chi-square Keyword Extractor node uses a statistical measure of co-occurrence of terms in a single document to determine the top n keywords. The algorithm includes the following steps, as described in [1]:
- Selection of frequent terms. By default, the top 30% of most frequent terms is selected to form the set of frequent terms G.
- Clustering frequent terms. Frequent terms are clustered together in two steps based on two similarity measures respectively.
- Similarity based clustering. If terms g1 and g2 have similar distribution of co-occurrence with other terms, g1 and g2 are considered to belong to the same cluster, according to the Jensen-Shannon divergence
- Pairwise clustering. If terms g1 and g2 co-occur frequently, g1 and g2 are considered to belong to the same cluster. The normalized pointwise mutual information is used here to detect those terms that co-occur most frequently.
- Calculation of expected probability. Assuming that a term w appears independently from frequent terms G, the distribution of co-occurrence of term w and the frequent terms G is similar to the unconditional distribution of occurrence of frequent terms G. Conversely, if a term w has a semantic relation with a particular term g ∈ G, co-occurrence of term w and term g is greater than expected; the distribution will be biased.
Here the algorithm counts the number of times terms g and w co-occur together as freq(w,g) and computes the expected frequency of co-occurrence as nwpg, where pg is the expected co-occurrence probability of frequent term g and nw is the total number of co-occurrences of term w and elements in frequent term set G. - Computation of χ2 value. This step evaluates the statistical significance of biases based on the chi-square test against the null hypothesis that “occurrence of frequent term g is independent from occurrence of term w”, which we expect to reject.
A variation of the χ2 value for term w with respect to frequent term g is computed as:Where: nwpg is the expected frequency of co-occurrence of terms g and w;
(freq(w,g) - nwpg) is the difference between expected and observed frequencies.
This variation χ'2 of the χ2 value is more robust against bias values.
Terms with large χ'2 scores (index of bias) are relatively important to describe the content in the document; terms with small χ'2 are relatively unimportant. In other words, if a term co-occurs frequently with a particular subset of frequent terms, the term is likely to have an important meaning [1].
Keygraph Keyword Extraction
The algorithm underlying the node Keygraph Keyword Extractor analyzes the graph of term co-occurrences [2]. The algorithm includes the following steps.
- A graph G for a document D is created using the document most frequent terms as nodes. The number of co-occurrences of two frequent terms gives the connection (edge) between the two corresponding nodes.
- Selection of frequent terms. Terms are sorted by their frequency and a fraction is extracted. By default, the top 30% of the frequent terms are extracted.
- Graph creation. Frequent terms become nodes of the graph. Edges between nodes are created only if the association between the two terms is strong. For that, the following association measure is used:
Where: |w|s denotes the count of w in sentence s. Analyzing the graph edges we can define clusters on a multiply connected graph.
- Computation of key value. The formula that measures the key factor of a word is:
Where:
based(w,g) counts the number of co-occurrences of term w and terms from cluster g in the same sentence throughout the whole document D;
neighbors(g) counts the number of terms in sentences including terms from cluster g (neighbor terms) throughout the whole document D;
based(w,g) / neighbors(g) is the rate of co-occurrence of term w with respect to co-occurrence of neighborhood terms and terms from cluster g;
key(w) denotes the conditional probability that term w is used against all clusters. - Extraction of the top K keywords. The top N high key terms,e. the N terms with the highest key(w) are extracted. The default N for high key term extraction, suggested by [2], is N=12. The high key terms extracted here are used to create new nodes in the graph G, if necessary.
The final key score of a term w is calculated as the sum of key(w) values across edges and sentences in the new graph. Based on this value and on the term position in the graph, the top K keywords are extracted to represent the document D.
Note. Both Chi-square Keyword Extractor and Keygraph Keyword Extractor nodes extract keywords for each document. Computational load increases strongly with the number of keywords to extract.
TF-IDF Index for Keyword Extraction
The third algorithm that we want to introduce here is the TF-IDF (or Term Frequency, Inverse Document Frequency). This algorithm scores the importance of terms in a document based on how frequently they appear both inside the single document and across multiple documents.
Formally:
TF - IDFt,d = TFd * IDFt
Where:
TF counts the occurrences of a specific term t in document d. This can be computed as the absolute or relative count.
IDF counts the number of documents in the collection containing (or indexed by) the term t.
If term ti occurs in di documents out of all D documents, [4] suggests the following IDF weight for TF of term ti:
IDF(ti) = log (D / di)
Some other forms have been proposed to calculate the inverse document frequency IDF. For this reason, the IDF node allows to select among three different options:
- Normalized → idf(ti) - log (D / di) (which corresponds to the form showed above)
- Smooth → idf(ti) = log(1 + D / di)
- Probabilistic → idf(ti) = log ((D - di) / di)
The normalized and the probabilistic IDF options set a lower bound, to avoid a term be given weight zero when appearing in all D documents.
If a word appears frequently inside a document, it's important and will therefore get a high TF score. However, if a word appears in many documents, it cannot be used as a unique identifier of a specific document and will consequently get a low IDF score. For example, common words like “and” and “therefore” which appear in many documents, will receive a low IDF score. Words that appear frequently in only one document will receive a higher IDF score.
Literature proposes many forms of TF-IDF. Here the product was adopted as suggested in [4].
The Chosen Algorithm
So which keyword extraction algorithm to choose for my understanding skill? In general, it is hard to establish the best technique, since some algorithms might work better in some situations and some in others.
The dataset used to train my brain consisted of the 5315 questions asked on the KNIME Forum between 2013 and 2017. This is the dataset also used to evaluate the keyword extraction algorithms. All forum posts have been first cleaned to remove stop words and punctuation. All of the terms have been tagged by a dictionary-based approach and stemmed. Then the three keyword extraction algorithms were applied. The algorithms were run multiple times, to extract 5, 10, 15, and 20 keywords.
Was there a substantial difference among the keywords extracted by the three algorithms? Or do they extract all the same keywords?
Figure 2 refers to the run with 20 keywords for each algorithm. The word cloud includes the keywords extracted by all three or by two algorithms, shown in blue, and the remaining keywords - extracted by one algorithm only - in orange. The three keyword extraction algorithms thus do not produce exactly the same set of keywords. From figure 2, it is clear that some keywords are uniquely identified through only one of the three algorithms.
Which algorithm extracts the highest number of common keywords?
Let’s count them. The bar chart in figure 3 reports the number of those keywords identified by one algorithm and by at least one other algorithm. For example, the Chi-square Keyword Extractor node finds 85k keywords also identified by at least one other algorithm; the Keygraph Keyword Extractor node on the other hand, extracts only around 20k of the keywords that were also identified by at least another algorithm; TF-IDF behaves similarly to the Chi-square Keyword Extraction algorithm in terms of commonly identified keywords.
The Chi-square Keyword Extraction algorithm seems to share the most common ground with the other two algorithms. To be conservative and avoid risking a too innovative approach, it was decided to adopt the Chi-Square Keyword Extraction algorithm.
Figure 2. This word cloud shows the keywords found by the three algorithms when searching for 20 keywords to represent each document. Keywords in blue were found by either two or three algorithms; keywords in orange were found by one algorithm only.

Figure 3. This bar chart shows the number of keywords commonly identified by the three algorithms when searching for 20 keywords across all forum questions. For example, the Chi-square Keyword Extractor node finds around 85k keywords that were found also by at least one other algorithm.

Wrapping up
The understanding step that led to my brain was implemented using keywords extraction. Among the many possible keyword extraction algorithms, the KNIME Text Processing extension offers:
- Chi-Square Keyword Extraction,
- Keygraph Keyword Extraction,
- extraction based on TF-IDF score.
The three algorithms have been briefly illustrated in this blog post and their computational steps described. As a loose comparison, the three algorithms were executed to extract 5, 10, 15, and 20 keywords from all questions posted on the KNIME Forum between 2013 and 2017. The Chi-square Keyword Extraction algorithm spotted most keywords in common with the other two algorithms and, following a conservative approach, it was adopted to implement my understanding feature.
The evaluation could have been run using classic precision/recall, F-measure, or accuracy measures. However, for that a labeled dataset was required which we did not have, as keywords are concerned. Missing the possibility for a more rigorous approach, the comparison relied on the number of common spotted keywords.
Hi! My name is Emil, I am a Teacher Bot, and I can understand what you are saying.
References
- Matsuo, Y., Ishizuka, M. (2004). Keyword extraction from a single document using word co-occurrence statistical information. International Journal on Artificial Intelligence Tools 13, (157–169).
- Oshawa, Benson, and Yachida (1998) KeyGraph: Automatic Indexing by Co-occurrence Graph based on Building Construction Metaphor
- Ramos, J. (2013). Using TF-IDF to Determine Word Relevance in Document Queries.
- Sparck Jones, K. (1972). A statistical interpretation of term specificity and its application. Journal of Documentation, Vol.28, pp. 11-21.