
Note. With KNIME Analytics Platform 4.7 or following versions, the Python features described in this article are now out of KNIME Labs. The new and more performant Python Script node can now be found in the KNIME Python Integration (which, in this article is still referred to as "KNIME Python Integration (Labs)". Find information regarding the new performance in this article. Learn more about other Python features now available v4.7 in the article, The New Python Script node with Bundled Packages.
What if we told you that the recently introduced Python Script (Labs) node makes Python just as fast in KNIME as it is anywhere else? That’s right, no latency when KNIME transfers tables to Python nodes.
In this blog post, we discuss the Python Script (Labs) node, currently available as part of the KNIME Python Integration (Labs) extension.
KNIME Python Integration Links Coders and Non-Coders
In recent years, low-code tools have made data science accessible to a wide range of users. Data science has become an integral aspect of all industries, and people in every field are embracing it, from HR managers to accountants, chemical engineers, and more. Users prefer software that is compatible with the existing technology or programming languages in their respective domains.
KNIME Analytics Platform is one such low-code software, used across a wide range of industries because it can be integrated with any tool, software, or programming language.
Every organization consists of coders and non-coders. Coders prefer programming languages for their daily data science tasks, while non-coders prefer low-code platforms. The KNIME Python Integration has already proved to be the link between these two groups. It allows KNIME users to run Python scripts inside the KNIME Analytics Platform, and also enables Python users to package their custom libraries in the form of a KNIME Component so they can run them seamlessly.
With the KNIME Python Integration (Labs) extension, a new API is available to access the data. In this article, I will look at some use cases to understand the boost in performance, and then showcase how batch processing can be used to avoid local memory issues during execution.
Tip: Install the KNIME Python Integration (Labs) extension by following the steps described in our documentation.
Understanding the Boost in Performance – Use Case 1
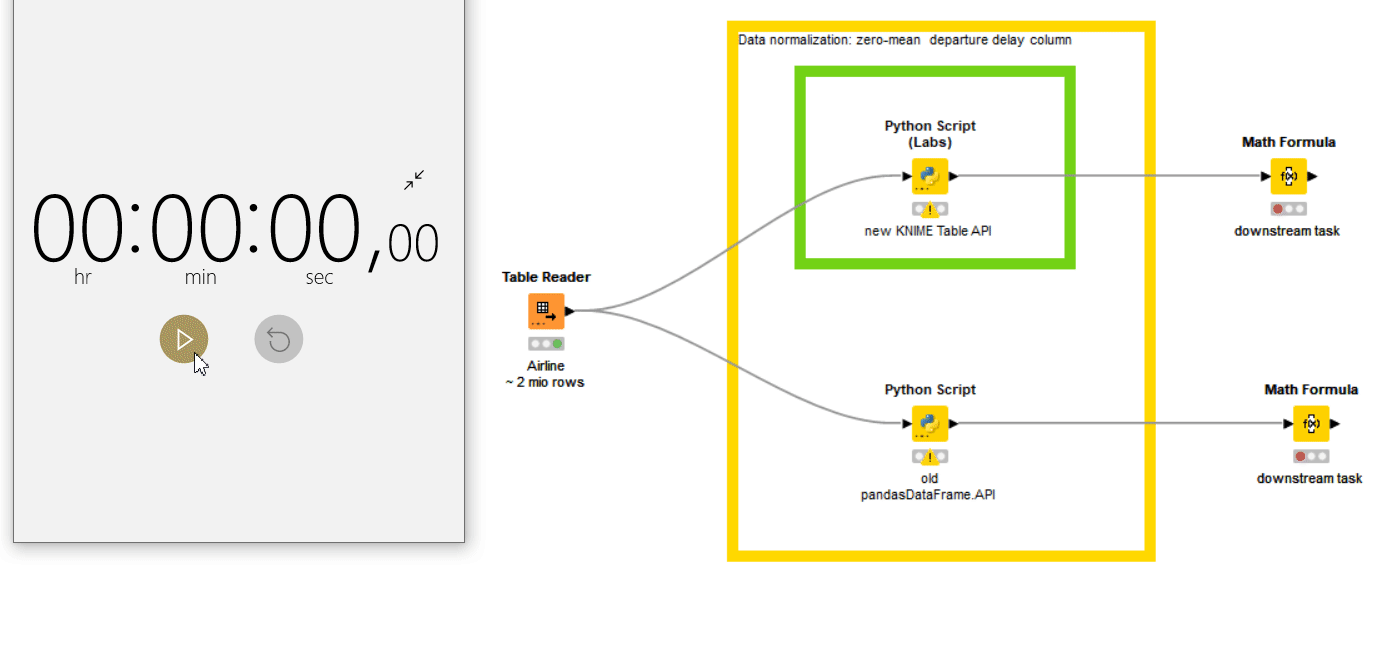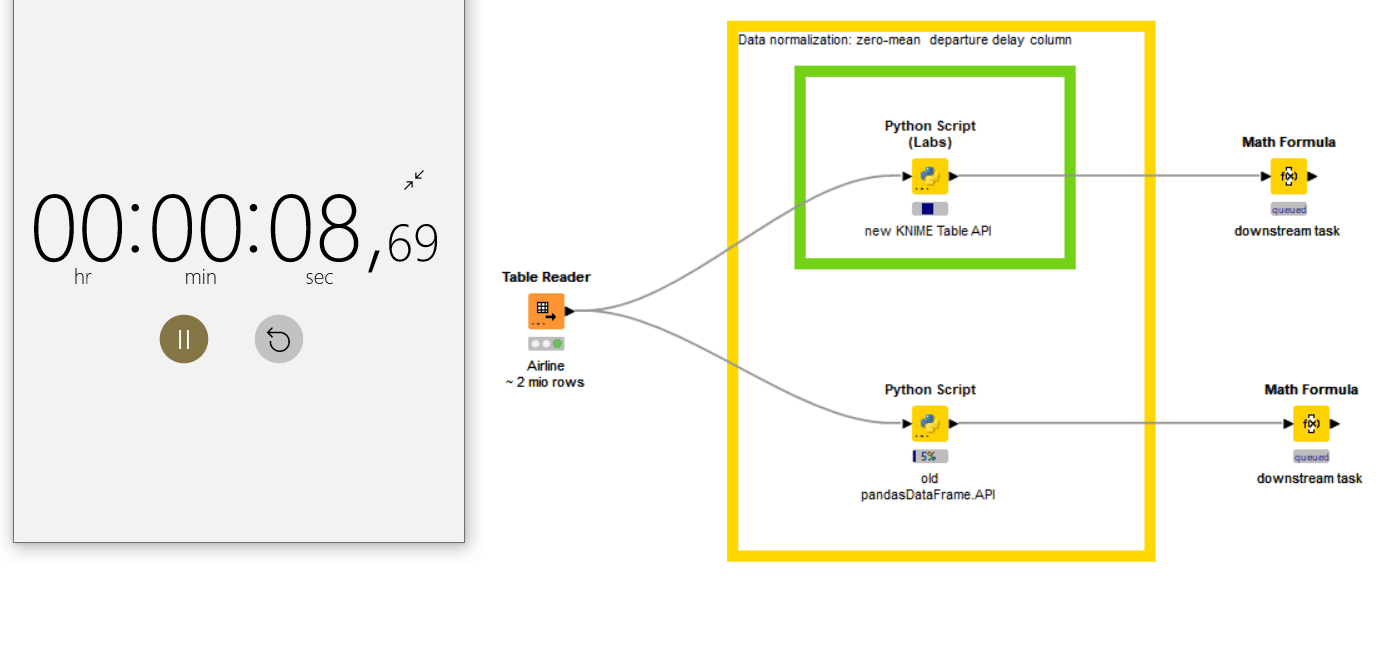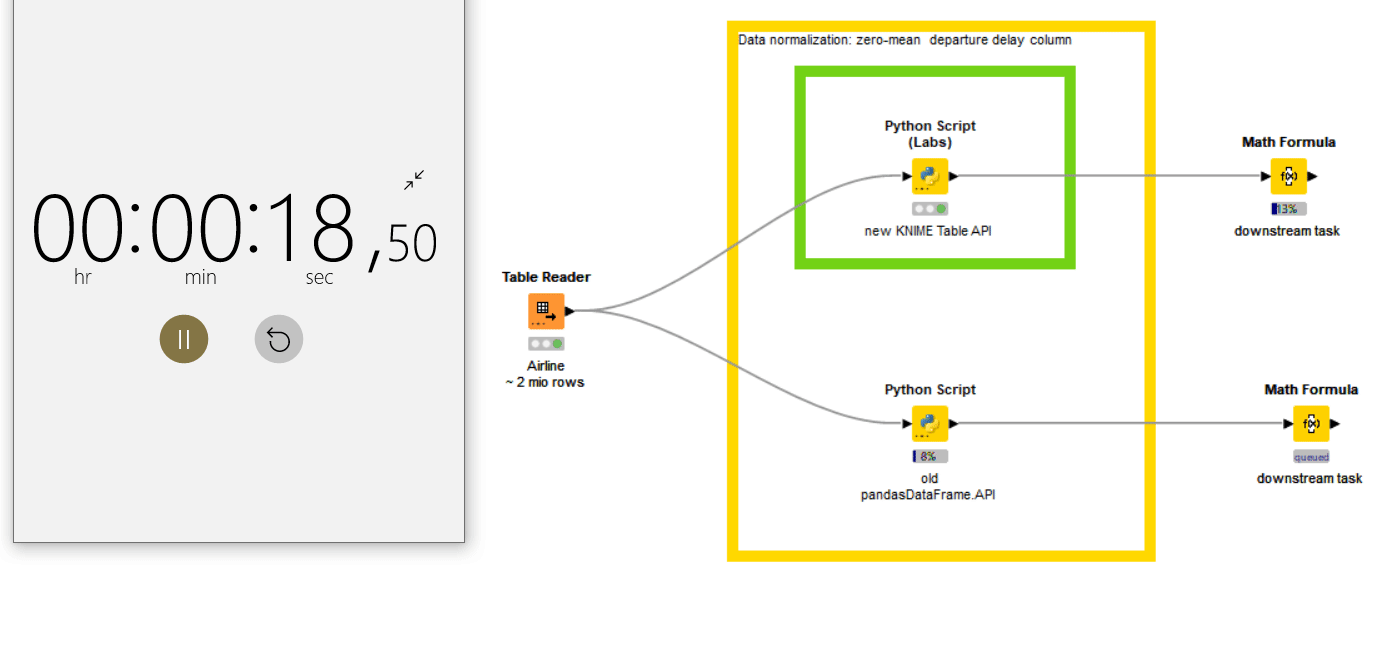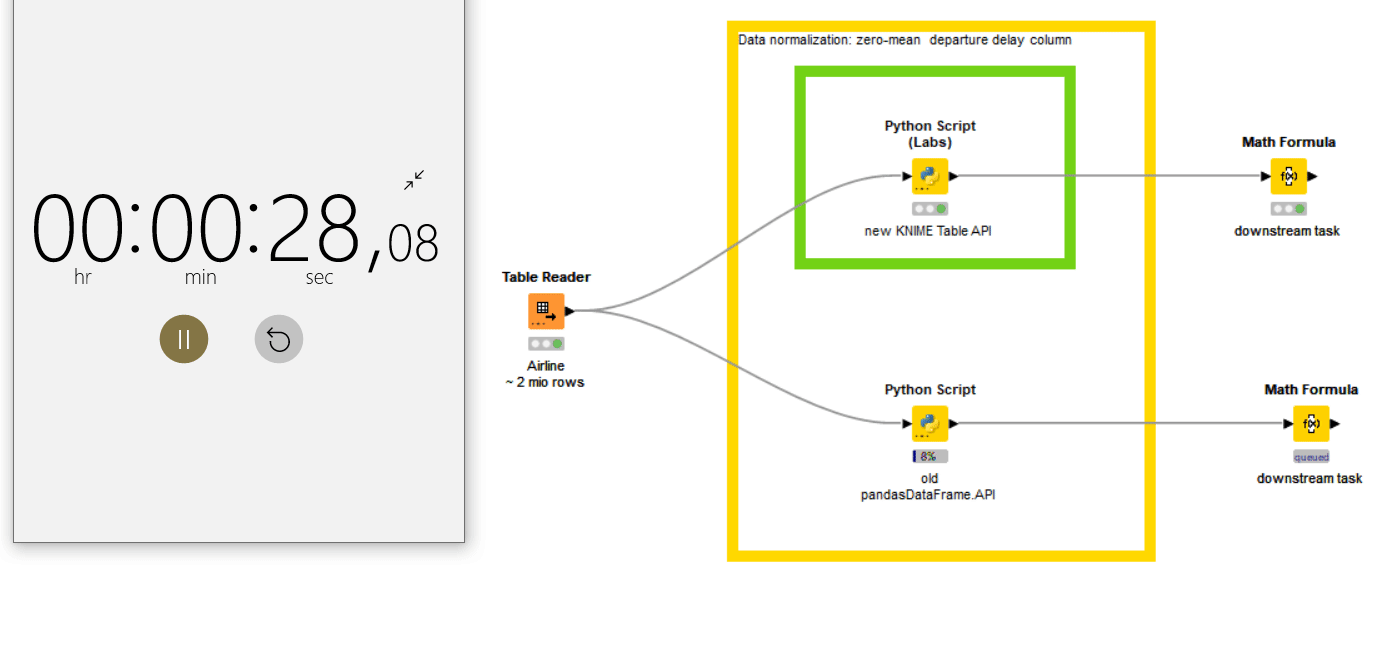
For this example we have the famous Airline Dataset from 2008, which contains around 2 million rows, each denoting the information of an individual flight on a particular day and whether it was diverted, canceled, or delayed. As a data scientist, we intend to apply some data transformations to this dataset so that we can ready this data for a downstream task. We decided to compute the deviation from the mean for the “Departure Delay” column. Although KNIME provides various native nodes for data transformation, we are particularly interested in applying the transformation using python packages. For this, we'll use the Python Script node, as well as the recently released Python Script (Labs) node, to compare their performance. The workflow used for this task is shown in Fig. 2.
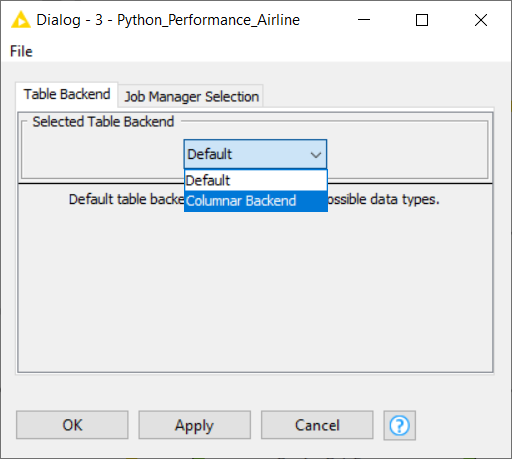
To make sure we get the fastest performance, we'll switch to the KNIME Columnar Table backend extension. This can be configured by right-clicking the workflow name in the KNIME Explorer and then clicking the “Configure” option. Select the Table Backend as “Columnar Backend,” as shown in Fig. 1.
Tip: Read more about the Columnar backend in the article, Inside KNIME Labs: A New Table Backend for Improved Performance.
50x performance improvement on 2-million-row data operation
As evident from the film shown in Fig. 2, it takes only 15 seconds to access the KNIME table from Python and apply the data operation on 2 million rows – using the Python Script (Labs) node with Pyarrow or Pandas (green annotation box). The old Python Script node needs more than 5 minutes. This is nearly a 50x improvement. The Apache Arrow backend drastically reduces the overhead of the data transfer between KNIME and Python.
Note that even if we use the default backend for the workflow, the Python Script (Labs) node is still faster for data transfer operations between KNIME and Python, compared to the Python Script node. But we recommend switching to “Columnar Backend” This provides the best performance with the Python Script (Labs) node.
How do I use the new API?
The new API, available via the knime_io module, provides a new way of accessing the data coming into the Python Script (Labs) node. When you drag the node to the KNIME Analytics Platform, the knime_io is imported into the script by default. The data coming into the node can be accessed as Pandas DataFrame or PyArrow Table. This is pretty cool, as we can access the input data as a PyArrow table when we want to perform some data operations, and can also access the data as Pandas DataFrame if we want to run machine learning models on the data. Fig. 3 shows the code snippet for accessing the data coming into Python Script (Labs) node.
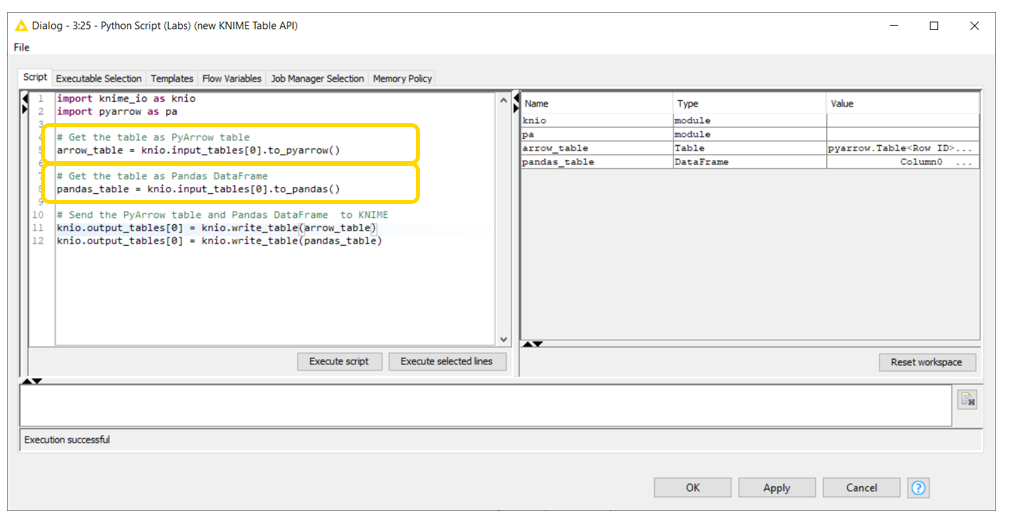
Note. For complete documentation of the new API, please refer to our documentation page.
Showcasing Batch Processing – Use Case 2
In this example, we want to train a classification model on the 2008 Airline Delay dataset to predict whether a given flight will be delayed or not. This trained model will also be used to predict the statuses of upcoming flights.
We use the workflow shown in Fig. 4 for this task. On the left side we import the biannual data files and append them. This appended data is then processed and supplied to the partitioning node to divide into a train set and a test set. As the set is huge, we use only 10% of the data for training, as it will be enough for the model to learn; the remaining 90% is kept as a test set.
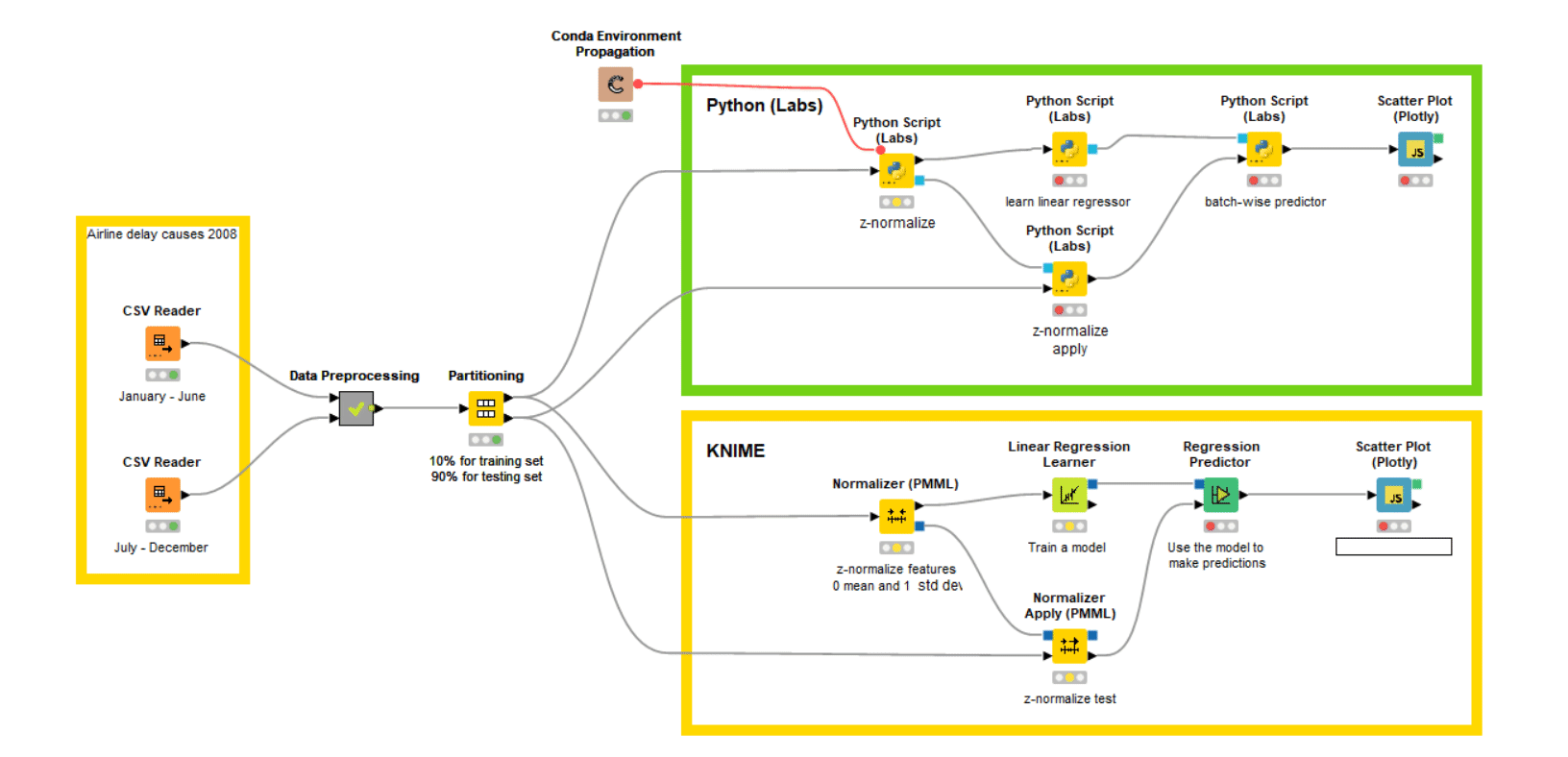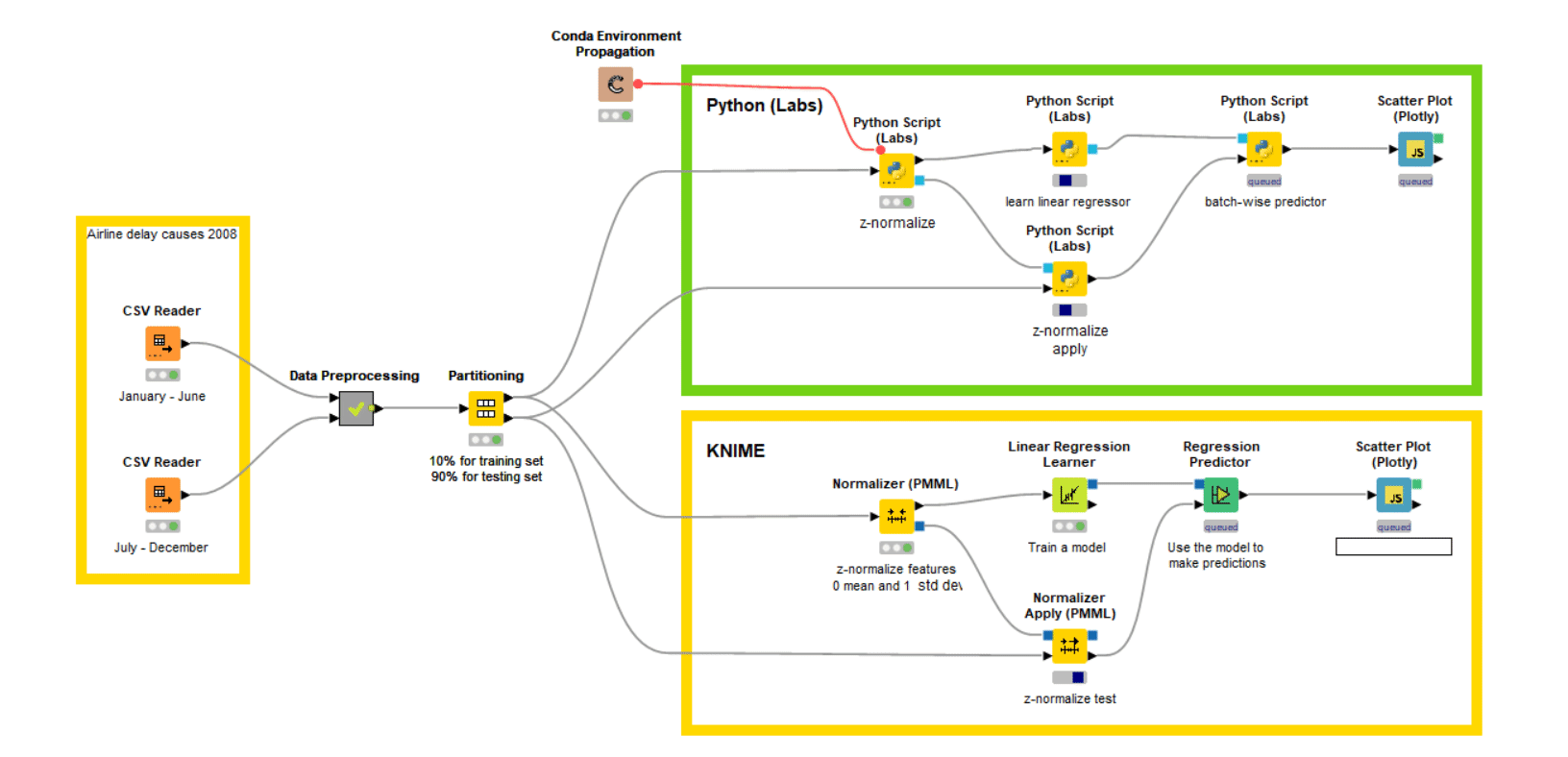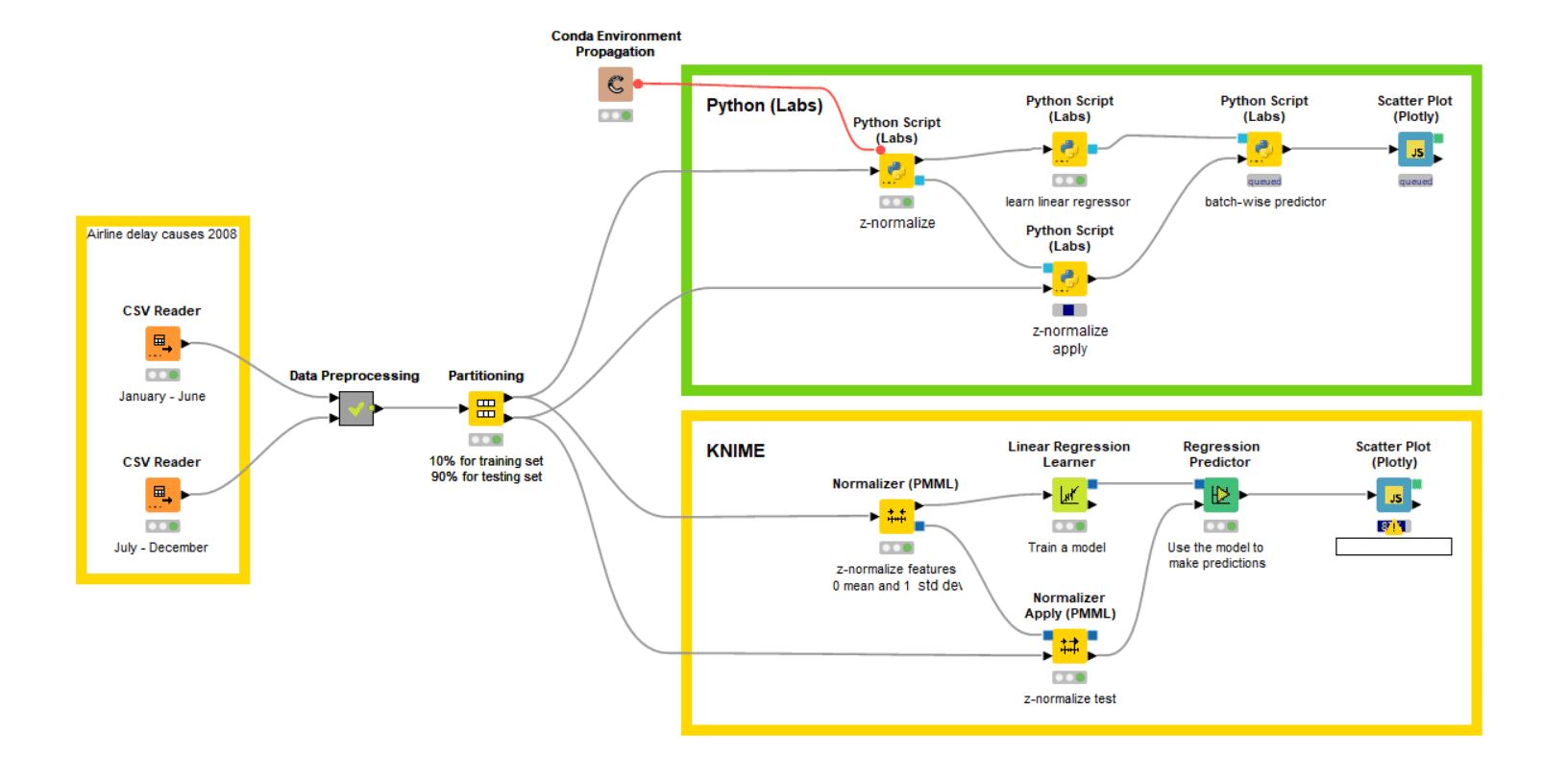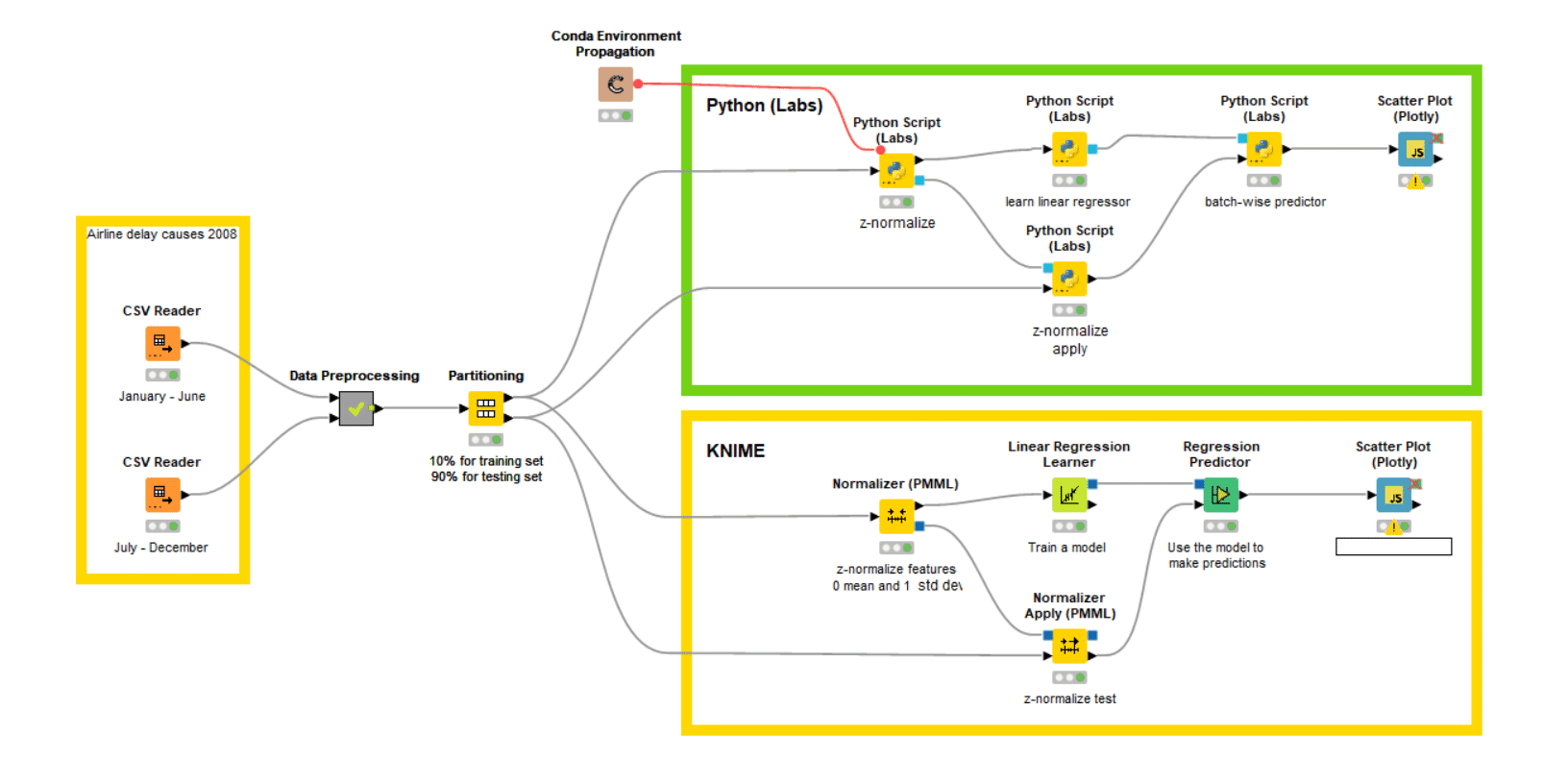
We decided to use logistic regression for this classification task. Again, we perform this task with two different branches, which will help me analyze the performance. In the first branch (green annotation box) we use the Python Script (Labs) node for training the model and the batch processing for prediction on the huge test set (around a million rows). This batch processing helps us to access these million rows in batches, even with a smaller amount of RAM. In the second branch (yellow annotation box), we use the native KNIME nodes.
As you can see in the film above in Fig. 4, the Python Script (Labs) nearly reaches the performance of native KNIME nodes.
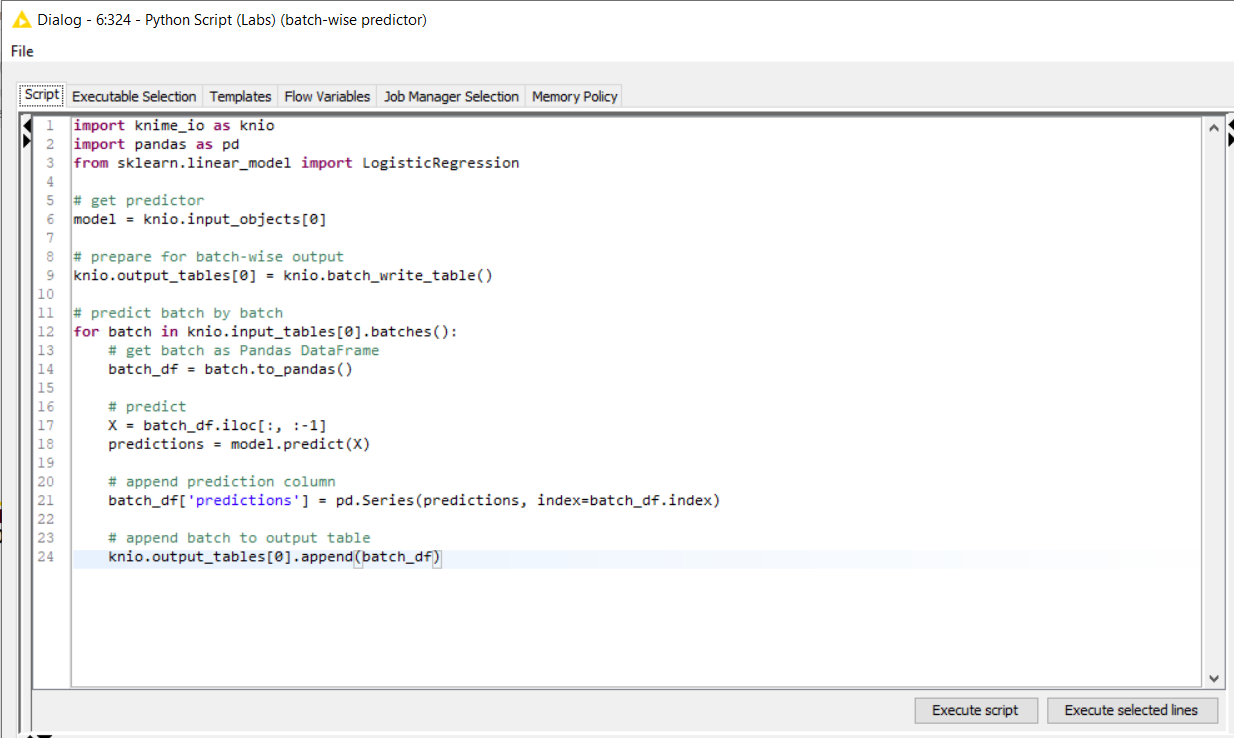
What is Batch processing in the Python Script (Labs) node?
The Python Script (Labs) node supports batch processing: This is an exciting new functionality that allows us to process data in batches using the knime_io module. Whereas previously the size of the input data was limited by the amount of RAM available on the machine, the Python Script (Labs) node can process arbitrarily large amounts of data by accessing it in batches, as shown in Fig. 5.
Porting Old Python Scripts
If you have been using the Python Script node from a previous integration to develop components or workflows, you can simply adapt those to work with the Python Script (Labs) node by adding the code shown in Fig. 6.

Fast Data Transfer between KNIME and Python Confirmed
In the new KNIME Python (Labs) Integration, the entire backend has been rewritten so that the data transfer between KNIME and Python will be much faster. Furthermore, we recommend using the Columnar Backend extension to achieve the best performance with the Python Script (Labs) node. The new API with the knime_io module allows you to access data via PyArrow tables for efficient data transformation, and you can use pandas dataframes for machine learning tasks. The module can also efficiently process data tables that are larger than your available RAM by utilizing batching.