
One of the highlights of the KNIME Analytics Platform 4.3 release is the new KNIME Columnar Table Backend. While this isn't a new node extension or new piece of functionality of direct use it's still an exciting new capability. So, what is it and why should you be interested?
A Framework that Enables Flexibility
One of the strengths of KNIME – and one of the reasons why it's used in so many different industries – is its type richness and flexible API. The type of data that can be processed in a workflow can range from simple data (numbers, character strings, dates) to complex objects such as text documents, predictive models, molecules, images, or even other workflows. The framework was designed to support these types and that flexibility has always been a priority. However, this flexibility also causes some overhead, in particular if the data to analyze is 'simple'. This overhead is mostly around some suboptimal use of main memory as cell elements in a table are represented by Java objects (in nerd lingo you would call it GC pressure and object representation over using primitives – in any case it’s something to avoid and improve on). So it was time to review the underlying data representation and also optimize for the case when that is as simple as a bunch of numbers and strings.
An Extension that Boosts Performance
The new Columnar Table Backend addresses these issues by using a different underlying data layer (backed by Apache Arrow), which is based on a columnar representation. The main advantage is: Performance! (Columnar vs. row-based data representation is a topic by itself, and there are many great articles describing what they do and why that is smart – this is a good overview).
The Benefits:
- The data is kept in a much more compact form (= more data fits into main memory)
- The data lives "off-heap" (a region of the memory that isn’t suffering GC pressure)
- Most importantly, simple data is kept … simple (no objects created)
- Smaller chunks of data are held (“cached”) in-memory, making the memory footprint of KNIME much more stable and controllable
- It is a first step in enabling shared memory with other programming languages such as Python (= even more performance gains down the road)
This new backend is available in KNIME Labs. It contains the backend itself and a new API for nodes to use it. Over time, we will gradually convert nodes in KNIME to make best use of the new API. Currently, all nodes will use a transition layer that uses the new backend but doesn’t exploit all possible benefits.
How to Install and Run the New Columnar Backend
To work with the Columnar Table Backend you need to first download KNIME Analytics Platform 4.3, which will be available from December 6, 2020. In order to run KNIME Analytics Platform after your download is complete, extract the archive or run the installer, and start the executable file.
If you want to test the improved performance on specific workflows, import these workflows from the existing workspace.
1. From the KNIME Analytics Platform go to File → Install KNIME Extensions… and select KNIME Columnar Table Backend extension, under KNIME Labs Extensions.
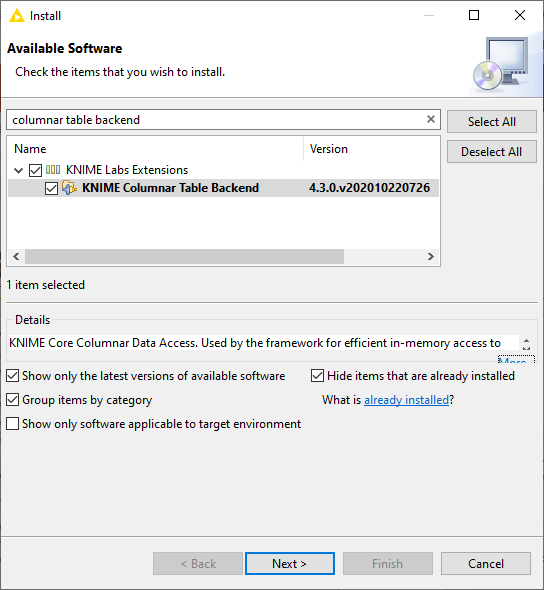
Fig. 1. Selecting the KNIME Columnar Backend extension from KNIME Labs.
2. After restarting KNIME Analytics Platform, define the type of Table Backend used for each workflow. Open the workflow, or create a new one, then, in KNIME Explorer, right-click the workflow and select Configure… from the context menu.
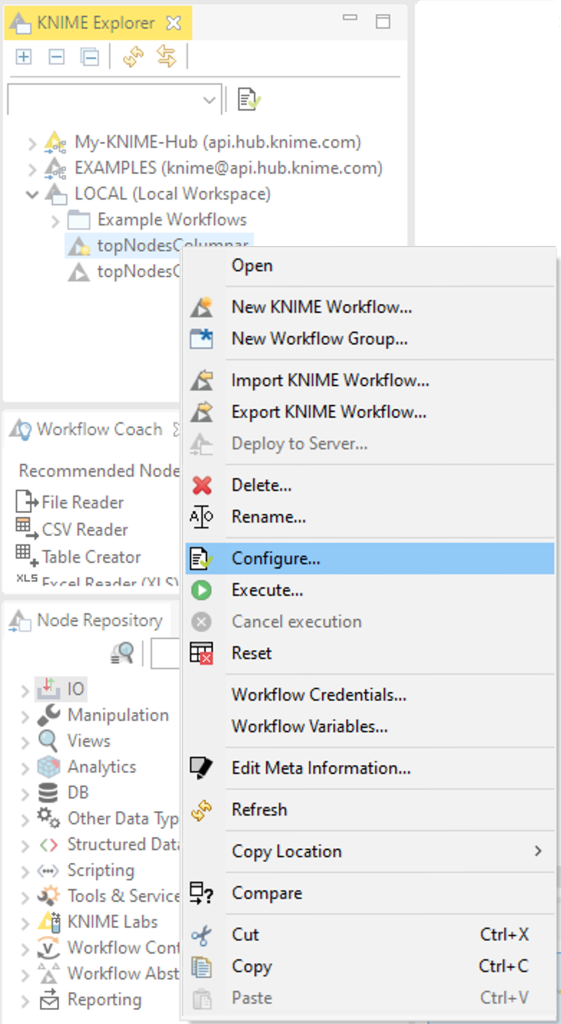
Fig. 2. Selecting Configure in order to define the type of Table Backend used for the selected workflow.
3. In the window that opens select the Columnar Storage (Labs) option from the drop-down menu in the Table Backend tab and click Apply.
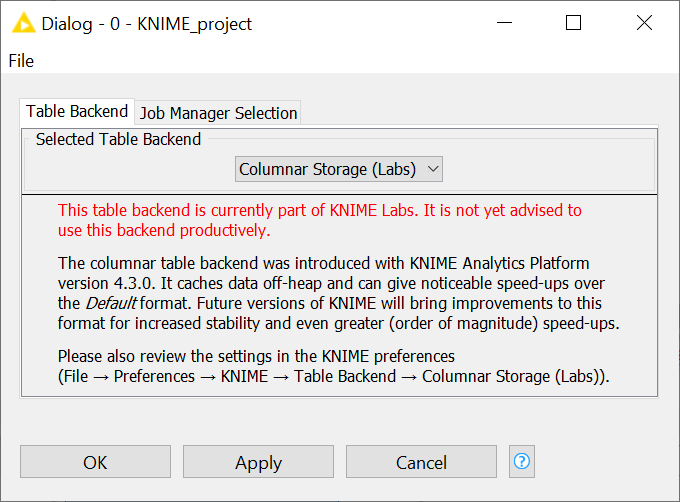
Fig. 3. Selecting the Columnar (Labs) type from the Table Backend tab.
4. The parameters relative to memory usage of the Columnar Table Backend can also be configured. Go to File → Preferences and select Table Backend → Columnar Storage (Labs) under KNIME in the left pane of the preferences window.
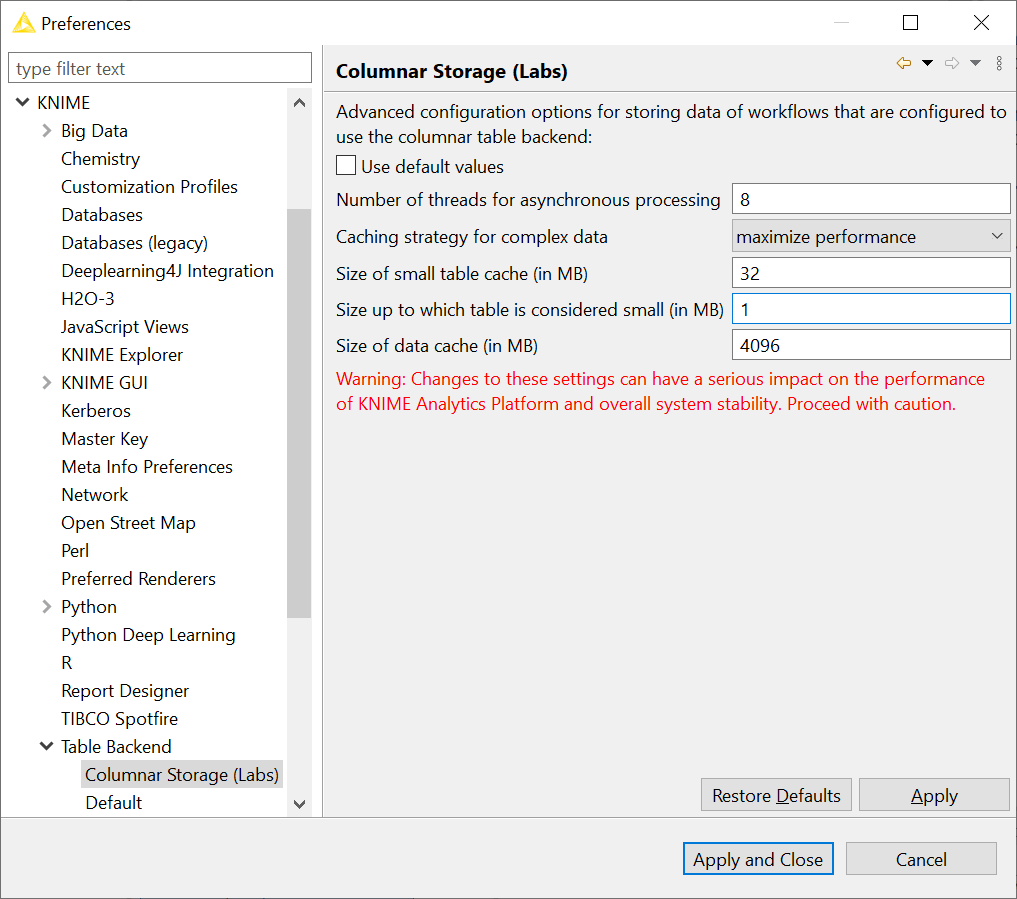
Fig. 4. The Columnar Table Backend preference page, which allows for advanced customization of the memory footprint and performance of workflows using the Columnar Table Backend.
Some default values are already set automatically, based on the system specifications where the current KNIME Analytics Platform is installed. However, unchecking the Use default values option activates the fields below, where the advanced configuration options can be set. Be aware that changes to these settings can seriously impact the performance of KNIME Analytics Platform and overall system stability.
Technical Background and Configuration
With the new Columnar Table Backend, any tabular data created inside a KNIME workflow traverses multiple layers of caches before it is written to disk (see Figure 5). A cache is a software component which buffers data such that future reads of that data can be handled more quickly. Data held by a cache is volatile in the sense that the cache can decide to drop it at any point in time.
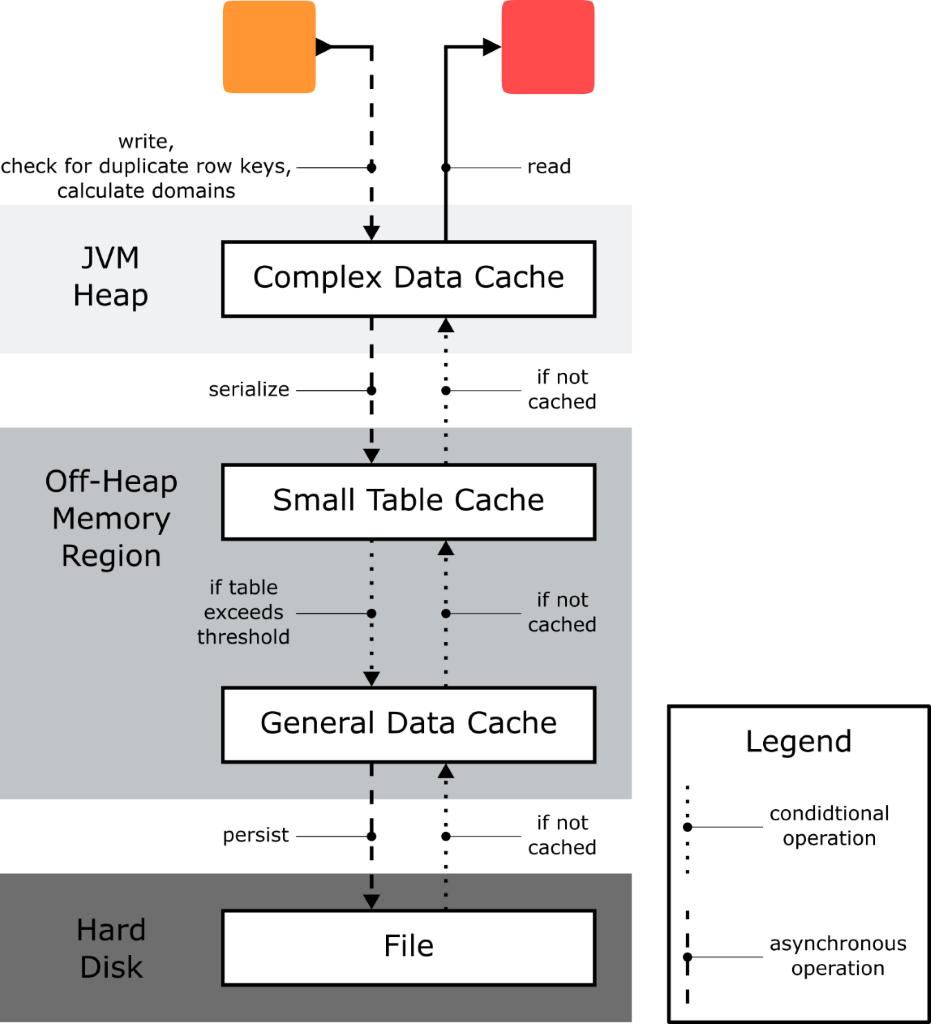
Fig. 5. Tabular data is written by a KNIME node. It asynchronously traverses multiple layers of caches and is eventually persisted to disk. When a KNIME node intends to read the data, it goes through this layer of cache to obtain the data. If the data has been evicted from all caches, it reads the data from disk and re-enters it into the caches.
The movement of data from one cache to the next and, eventually, to disk, is performed asynchronously by a configurable number of dedicated threads. In other words, a node that generates data will already be displayed as executed and downstream nodes will already be able to work with that data even though the data might not have been fully persisted to disk yet. Each cache makes sure that it never releases any data before that data has been passed on to the next cache layer.
Configuring Size and Behavior of Caches
In the Columnar Table Backend, there are currently three caches, the size and behavior of which can be configured via the Columnar Table Backend preference page (see Figure 4) as well as, eventually, through the knime.ini.
- The Complex Data Cache holds data in the Java Virtual Machine’s heap region of memory and can be configured to minimize memory usage or maximize performance.
- The Small Table Cache holds recently used small tables in the off-heap memory region. The threshold up to which a table is considered small and the size of the cache (in megabytes) can be configured through the Preference page
- The General Data Cache holds recently used chunks of arbitrarily-sized tables up to a configurable total size (in megabytes) in the off-heap memory region.
Note that the caches that reside in the off-heap memory region require an amount of memory in addition to whatever memory you have allotted to the heap space of your KNIME's Java Virtual Machine via the -Xmx parameter in the knime.ini. When altering the sizes of these cache via the preference page, make sure not to exceed your system’s physical memory size as otherwise you might encounter system instability or even crashes.
Outlook
In this blog article, we introduced the new Columnar Table Backend – a complete rewrite of how KNIME handles internal tables.
While the new Columnar Table Backend is fully compatible with all existing nodes through a transition layer, we will be changing our own nodes to make full use of this technology and, eventually, we will make this new API available to our partners and community. In turn, partner and community extensions will also be able to contribute their own data types to the framework.
Your Feedback
We’re looking forward to receiving your feedback. If you’re a KNIME AP user, let us know, by posting in this thread in the KNIME Forum, if you run into any problems or have further suggestions for us.
If you’re a KNIME node developer, expect more on the API, data type extensions, and other technical background in upcoming blog posts.
Now we hope you enjoy trying out the new Columnar Table Backend extension.