Welcome to the fifth episode of our Guided Labeling KNIME Blog Series. In the last four episodes, we introduced Active Learning and a practical example with body mass index data, which shows how to perform active learning sampling via the technique “exploration vs exploitation”. This technique employs label density and model uncertainty to select which rows should be labeled first by the user of our active learning application deployed on KNIME WebPortal.
Limitations of Active Learning
Active learning is a powerful technique to train a supervised model when you have data for your model input, but no labels attached. Despite its effectiveness injecting human expertise during the training of your model, active learning can still be time expensive.
The active learning iterative process reduces the time required to label samples in order to train a model, but still requires manual labeling. In fact active learning allows you to reduce the number of manually labeled samples necessary to train a model, but it still might be necessary to label thousands of samples. The more complex your classification task is, the more labels are needed to teach your model even via active learning.
Imagine a use case where labeling samples in a random order would take you several months before achieving good model performance. In this case applying active learning would still require your expert to label a large amount of samples, maybe reducing the time it takes from months to weeks. So the question is: besides active learning, is there another technique to save even more time?
When few or no labels are available, there are a few additional techniques to active learning you can use to train a model (e.g. semi-supervised learning, transfer learning, etc). In this episode we will focus on a technique called weak supervision. While active learning focuses on training a model aiming at gathering a small sample of labels of high quality, weak supervision instead leverages on gathering an enormous sample of labels of doubted quality from several and totally different sources. Let’s see more in detail what this other technique is about.
Learning from Weak Label Sources
While active learning was already well known way before the terms “data science” and “AI” were coined, weak supervision became popular in recent years when the Stanford AI Lab released a Python library called Snorkel in around 2019.
To understand how weak supervision works we'll use the following example. Imagine you want to decide whether or not to watch a list of movies based only on your friends suggestions and ignore any features of the movies. Your friends give their opinion based on whether they watched it or not and whether they liked it or not. If they did not watch the film they will simply not share any opinion, but if they have watched it they will give you a positive or negative opinion.
To summarize:
- Each “friend” can output for each “movie”:
- “good movie” (?),
- “not seen movie” ( - ),
- “bad movie” (?).
- Assumptions:
- You never watched any of those movies.
- You do not know which friend has a taste similar to yours.
- You want to ignore any information about the movie
(e.g. movie genre, main actor, ...). - Your friends' opinions are independent from one another (they do not know each other).
Technically you could join together all your friends' opinions on a single movie and compute an outcome whether the movie is worth watching or not. You could for example use a simple majority vote (Fig. 1).

Figure 1 : Weak Label Sources Example: each friend is asked an opinion on a movie and can answer: “good movie” (?), “not seen movie” ( - ), “bad movie” (?). The combined result could be already computed via a simple majority vote.
By collecting opinions on all the movies on your list (Fig. 2), getting out the majority vote and watching the movie, you might realize that one friend's opinion might be more reliable than other ones. Is there a way to detect those friends before even watching the movies and compare the majority vote with the future public opinion from, for example, the next Oscars Academy Awards? In other words, is there a way to measure the accuracy of your friends in recommending movies? Keeping in mind whose opinion is more reliable might be wiser rather than a simple majority vote; that means basically weighting the opinion of certain friends more than others.
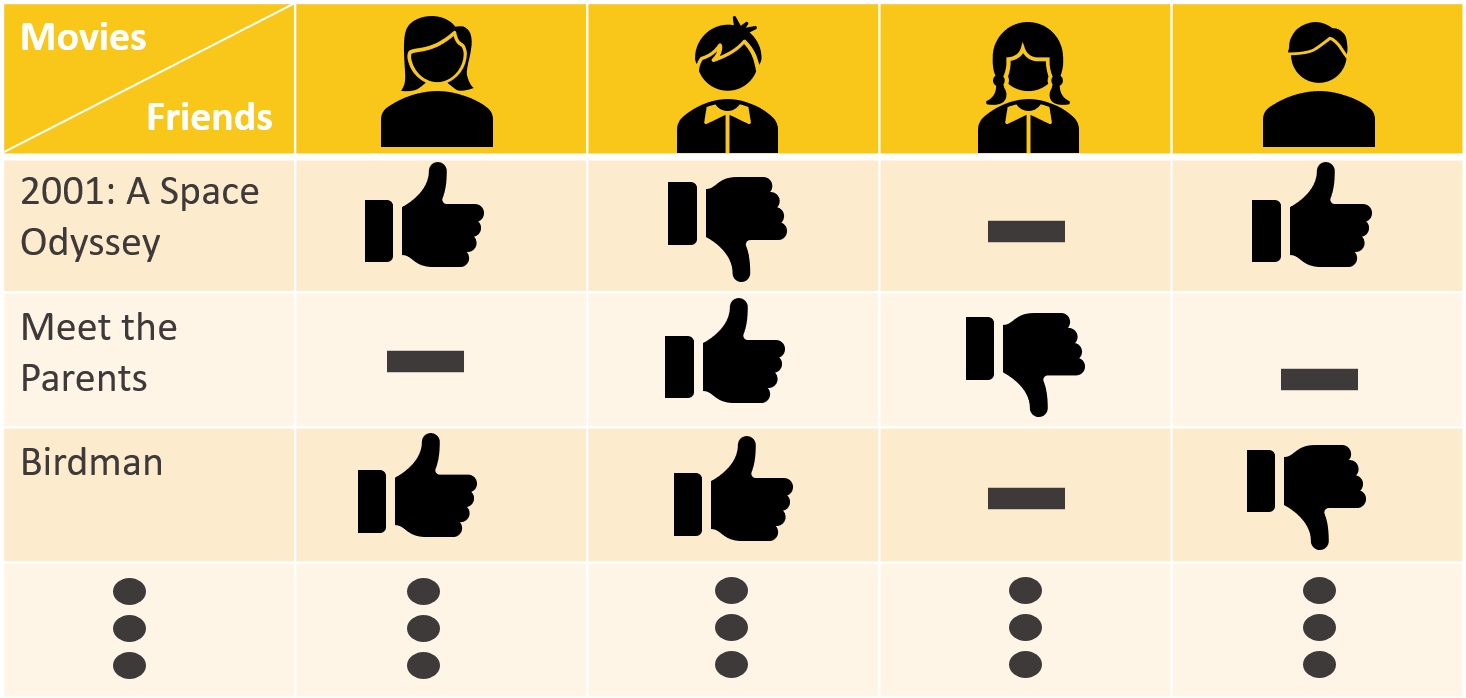
Figure 2 : Weak Label Sources Matrix Example: When collecting opinions on different movies from different friends you can build a matrix table where each column is related to a different friend and each row a different movie.
Weak supervision is able to estimate the accuracy of each of your friends’ opinions over all movies and output a probabilistic label for each of them. This probabilistic output is a probability distribution for the possible outcome - besides the “not seen movie” case. In our example it would be a probability vector (Y) for each movie your friends recommended:
Y : [ Probability “good movie” (p?),
Probability of “bad movie” (p?) ]
p?+ p? = 1
Such probabilistic output takes into account the accuracy of your friends’ opinion and it weights each of your friends accordingly. If each of your friends has the same accuracy the output would be again a simple majority vote.
How does weak supervision train such a model without knowing which movie is great or not? How does it find the accuracy for each friend? This point is actually the pivotal concept within the weak supervision approach.
Weak supervision is able to train a model called either the “label model” or “generative model” using a Bayesian approach (Fig. 3). It takes as input the opinions and, via a matrix completion algorithm, detects patterns of agreement and conflicts to correctly weight each “friend” based on the learned accuracy.
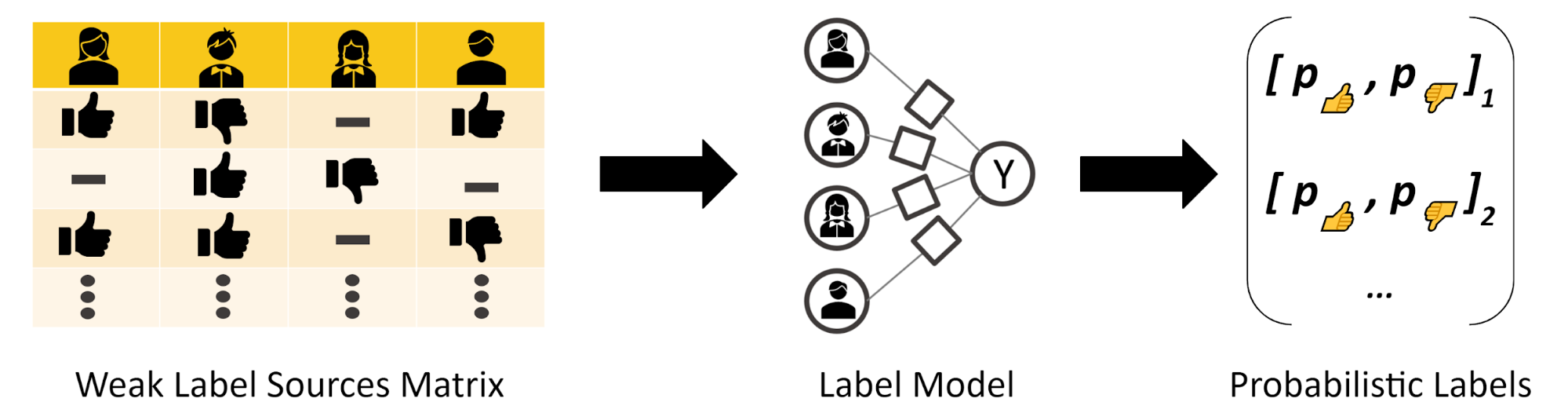
Figure 3 : Training the Weak Label Model: By feeding the Weak Label Sources Matrix into the Label Model you are able to compute a Probabilistic Output which weights each source based on its estimated accuracy. The matrix-completion algorithm can do this by detecting the overall patterns of conflicts and matching between the different independent sources via a Bayesian approach.
Generalizing the Weak Label Sources with Features Data
Using this approach you have an automated prediction to know which movie is worth watching. By blending knowledge from all your friends' opinions in a more reliable way than a simple majority vote, you can decide based on the highest probability at the output (Fig. 4). Of course, the more opinions, the more reliable the label model will be.
The label model however only works if you have opinions on a movie. If you had to use this model on a movie for which your friends did not share any opinion it simply would not work. Furthermore, we are not using a lot of other information we could have had about the movie (movie genre, main actor, movie budget,...).
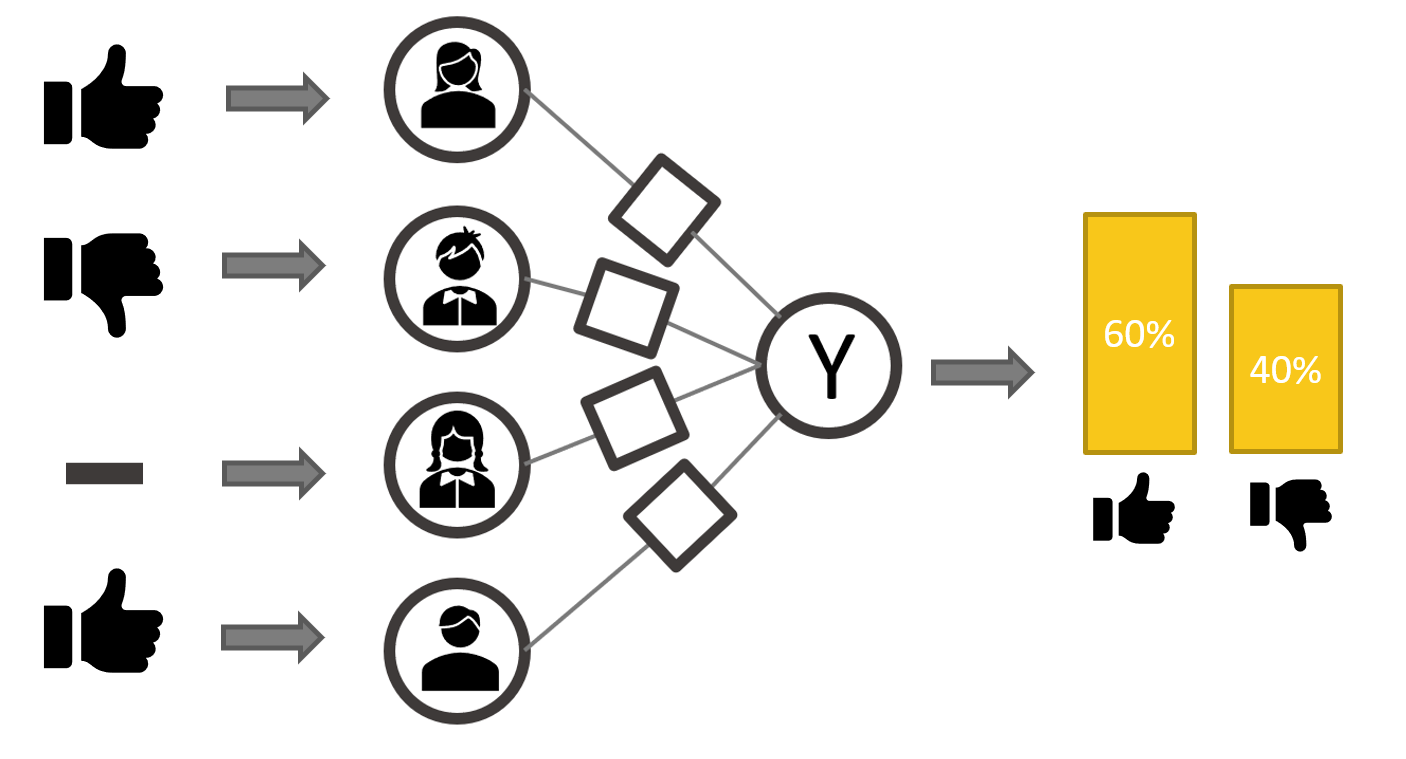
Figure 4 : Scoring with the Label Model works only if you have weak label sources available for that particular data point and it totally ignores any other associated feature data.
For predicting whether a movie is good or not when no opinion is available, we could use additional movie information and the output of the label model. This way we can generalize what the label models produced to new movies via a second model. All we need is a machine learning model able to learn a classification task from probabilistic labels instead of pure labels. It turns out that neural networks, logistic regression, and - with a few adaptations - many others are also suitable. This second model is known in weak supervision as the “discriminative model” (Fig. 5).
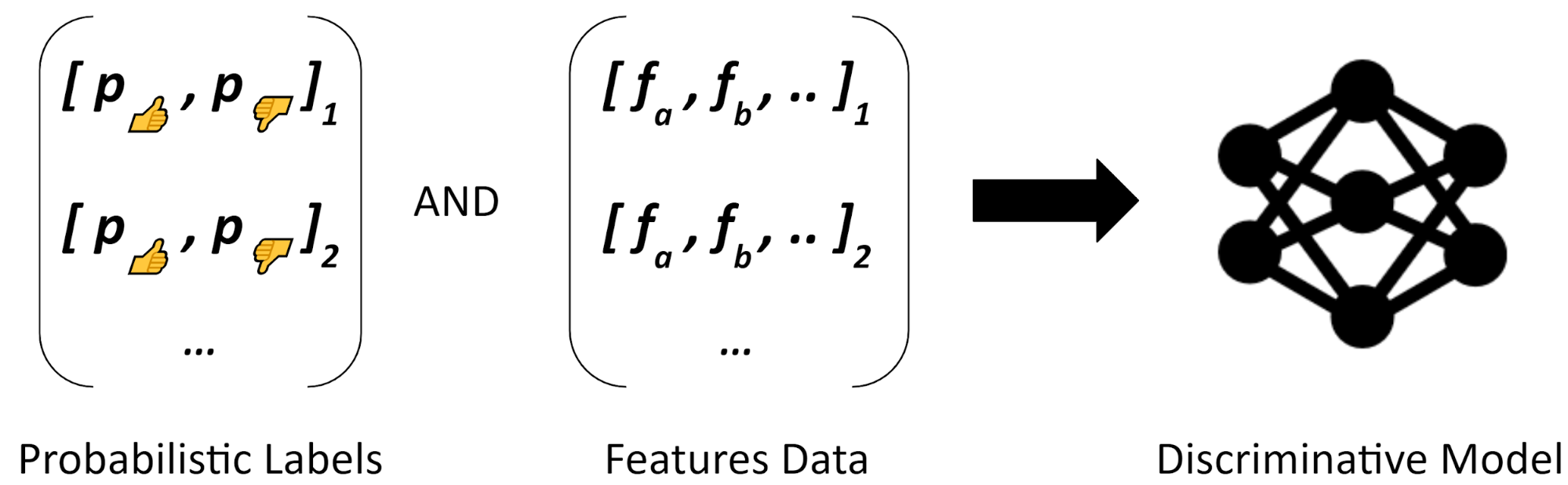
Figure 5 : Training with the Discriminative Model requires the output of the Label Model and the associated feature data. Neural networks (deep learning) alongside many other ML algorithms can be trained via probabilistic labels instead of standard labels for learning a classification task.
Once you train a discriminative model you will be able to score a prediction on any movie for which you have available features (Fig. 6). The discriminative model is what you need to deploy, no need to carry the label model along.
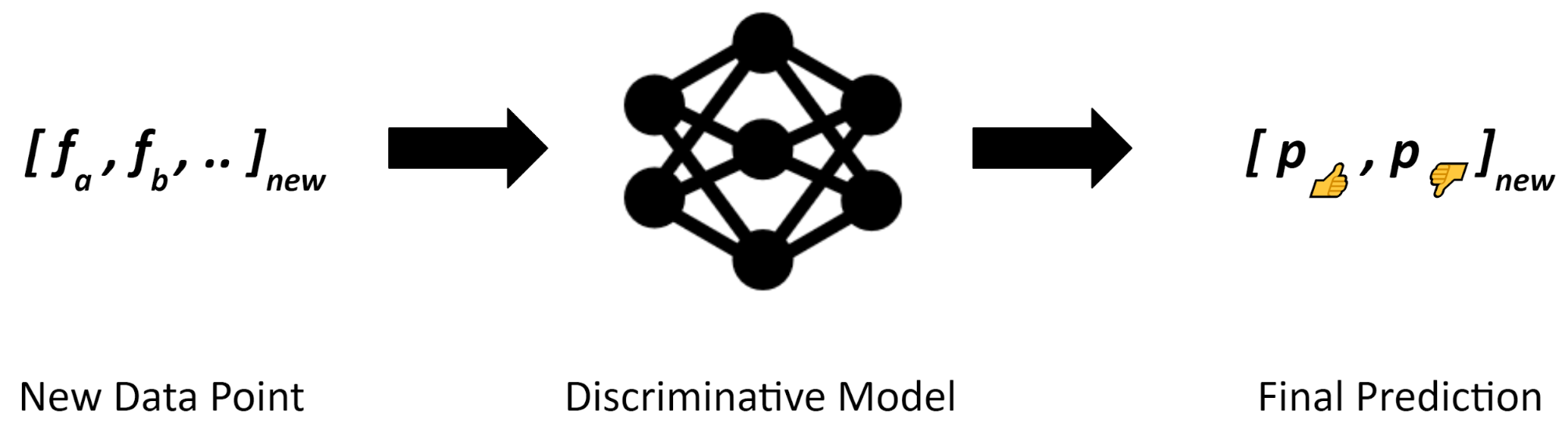
Figure 6 : Scoring with the Discriminative Model is possible via simply providing features of the new data point just like in the deployment of any machine learning model.
You might be thinking now, great so now I can blend my friends' opinions on movies with features about those movies in a single model, but how is this useful if I don't have any labels to train a generic supervised model? How can weak supervision become an alternative to active learning in a generic classification task? How can this analogy with many “friends” labeling “movies” work better than a single human expert like in active learning?
In the next Guided Labeling Blog Post episode, we will generalize the weak supervision approach to train any machine learning classifier on a generic unlabeled dataset and compare this strategy with active learning. Stay tuned!
And take part in discussions around the Guided Labeling topic on this KNIME Forum thread!
The Guided Labeling KNIME Blog Series
By Paolo Tamagnini and Adrian Nembach (KNIME)
- Episode 1: An Introduction to Active Learning
- Episode 2: Label Density
- Episode 3: Model Uncertainty
- Episode 4: From Exploration to Exploitation
- Episode 5: Blending Knowledge with Weak Supervision
- Episode 6: Comparing Active Learning with Weak Supervision
- Episode 7: Weak Supervision Deployed via Guided Analytics