One of the key challenges of utilizing supervised machine learning for real world use cases is that most algorithms and models require lots of data with quite a few specific requirements.
First of all you need to have a sample of data that is large enough to represent the actual reality your model needs to learn. Nowadays there are lots of thoughts regarding the harm generated by biased models. Such models are often trained with biased data. Usually, a rough rule of thumb is that the more data you have, the less biased your data might be. The size of the sample not only impacts the righteousness of your model, but of course its performance, too. This is especially significant if you are dealing with deep learning which requires more data than other machine learning algorithms.
Assuming you have access to all of these data, you now need to make sure they are labeled. These labels, also called the ground truth class, will be used as the target variable in the training of your predictive model.
There are a couple of strategies for labeling your data. If you get lucky you can join your organization data with a publicly available online dataset. For example by using platforms like kaggle.com, connecting to a domain specific database via a free API service or accessing one of the many government open data portals, you can add the missing label you need to your dataset. Good luck with that!
While there are tons of publicly available datasets, there are also many potential users out there ready to go through your data and label it for you. This is where it starts to get expensive. Crowdsourcing is only useful for simple labeling tasks where generic users can complete the task. One of the most common platforms for crowdsourcing labeling tasks is MTurk, where for each row of your dataset you can pay a fee for some random person to label it. Labeling images of cars, buses, and traffic lights are a true classic in the crowdsource domain. CAPTCHA and reCAPTCHA are all about cheating people into labeling huge datasets (and of course also to prove the user is a real person surfing the web).
Even if you have access to such technologies, your data might not be shareable outside your organization, or specific domain expertise is required and you need to make sure the user labeling your rows can be trusted. That is an expensive, irreplaceable, soon-to-be-bored domain expert labeling thousands and thousands of data points/rows on their own. Each row of the dataset could contain any kind of data and could be displayed to the expert in very different formats. For example as a chart, document or image, literally anything. A long, painful, and expensive process awaits a business that needs its data labeled. So how can we efficiently improve the labeling process to save money and time then? Well, with a technique called active learning!
Active Learning Sampling
In the active learning process, the human is brought back into the process - the human is brought back into the loop and helps guide the algorithm. The idea is simple: Not all examples are equally valuable for learning, so first, the process picks the examples it deems to be most valuable for learning and the human labels them, enabling the algorithm to learn from them. This cycle - or loop - continues until the learned model converges or the user decides to quit the application.
To initialize this iterative process we need a few starting labels, but as we have no labels at all, there is little we can use in order to select which rows should be labeled first. The system picks a few random rows and it shows them to our expert and gets the manually applied labels in return. Now, based on just a small number of labels, we can train a first model. This initial model is probably quite biased, as it is trained on so few samples. But this is only the first step. Now we are ready to improve the model iteration by iteration.
With our trained model we can score all the rows for which we still have missing labels and start the first iteration of the active learning cycle. The next step in this cycle is called active learning sampling. Active learning sampling is about selecting what the human-in-the-loop should be labeling next to best improve the model. It is carried out during each iteration of the human-in-the-loop cycle.
To select a subset of rows, we rank them using a metric and then show the top ranked rows to the expert. The expert can browse the rows in decreasing rank and either label them or skip them, one after the other. Once the end of the provided sample is reached, the expert can tell the application to retrain the model adding the new labels to the training set and then repeat the human-in-the-loop cycle again.
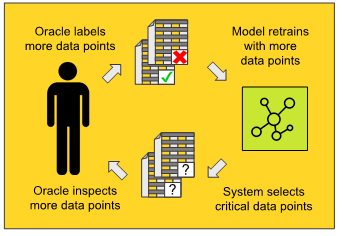
Fig. 1: A diagram depicting the human-in-the-loop cycle of active learning. The domain expert, referred to here as the "oracle" as is typical in active learning literature, labels data points at each iteration. The model retrains and active learning sampling re-ranks any rows where labels are still missing labels. In the next iteration of this cycle the user labels the top ranked rows and the model trains again. Using a good active learning sampling technique you can achieve good model performance with less labels than you would usually need.
All clear right? Of course not! We still need to see how to perform active learning sampling. In the next active learning articles in this series, we will show how the rows are ranked and selected for labeling in each iteration. This is what is at the real core of the active learning strategy. If such sampling is not effective, then it is simply better to label randomly as many rows as you can and then train your model - without having to go through this sophisticated human-in-the-loop process. So how do we intelligently select what to label after each model retraining?
The two strategies we'll look at in the upcoming active learning blog articles to perform our active sampling are label density, based on the distribution of the columns of the entire dataset in comparison with one of the already labeled rows and model uncertainty, based on the prediction probabilities of the model on the still unlabeled rows.
In future articles, we show how all of this can be implemented in a single KNIME workflow, i.e. both strategies are used in the same workflow. The result is a web-based application where a sequence of iterating interactive views guides the expert through the active learning process of training a model.
The Guided Labeling KNIME Blog Series
By Paolo Tamagnini and Adrian Nembach (KNIME)
- Episode 1: An Introduction to Active Learning
- Episode 2: Label Density
- Episode 3: Model Uncertainty
- Episode 4: From Exploration to Exploitation
- Episode 5: Blending Knowledge with Weak Supervision
- Episode 6: Comparing Active Learning with Weak Supervision
- Episode 7: Weak Supervision Deployed via Guided Analytics