
As first published in Dataversity
Sometimes when you talk to data scientists, you get this vibe as if you’re talking to priests of an ancient religion. Obscure formulas, complex algorithms, a slang for the initiated, and on top of that, some new required script. If you get these vibes for all projects, you are probably talking to the wrong data scientists.
Classic data science projects
A relatively large number (I would say around 80%) of Data Science projects are actually quite standard, following the CRISP-DM process closely, step by step. Those are what I call classic projects.
Churn prediction
Training a machine learning model to predict customer churn is one of the oldest tasks in data analytics. It has been implemented many times on many different types of data, and it is relatively straightforward.
We start by reading the data (as always), which is followed by some data transformation operations, handled by the yellow nodes in Fig. 1. After extracting a subset of data for training, we then train a machine learning model to associate a churn probability with each customer description. In Fig. 1, we used a decision tree, but of course, it could be any machine learning model that can deal with classification problems. The model is then tested on a different subset of data, and if the accuracy metrics are satisfactory, it is stored in a file. The same model is then applied to the production data in the deployment workflow (Fig. 2).

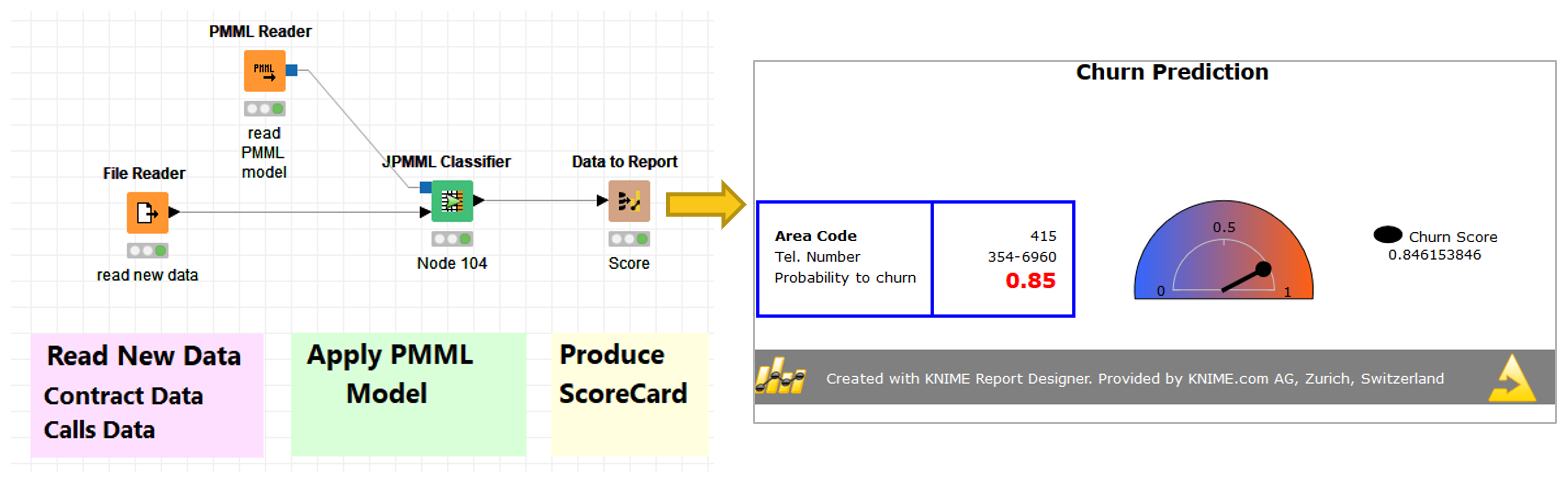
Demand prediction
Demand prediction is another classic task, this time involving time series analysis techniques. Whether we’re talking about customers, taxis or kilowatts, predicting the required amount for some point in time is a frequently required task. There are many classic standard solutions for this.
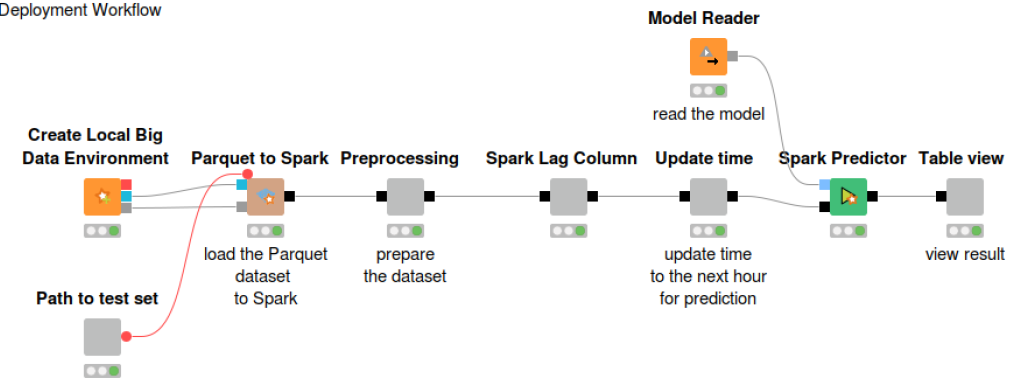
In a solution for a demand prediction problem, after reading and preprocessing the data, a vector of past N values is created for each data sample. Using the past N values as the input vector, a machine learning model is trained to predict the current numerical value from the past N numerical values. The error of the machine learning model on the numerical prediction is calculated on a test set, and if acceptable, the model is saved in a file.
An example of such a solution is shown in Fig. 3. Here, a random forest of regression trees is trained on a taxi demand prediction problem. It follows pretty much the same steps as the workflow used to train a model for churn prediction (Fig. 1). The only differences are the vector of past samples, the numerical prediction, and the full execution on a Spark platform. In the deployment workflow, the model is read and applied to the number of taxis used in the past N hours in New York City to predict the number of taxis needed at a particular time (Fig. 4).

Most of the classic Data Science projects follow a similar process, either using supervised algorithms for classification problems or time series analysis techniques for numerical predictive problems. Depending on the field of application, these classic projects make up a big slice of a data scientist’s work.
Automating model training for classic data science projects
Now, if a good part of the projects I work on are so classic and standard, do I really need to reimplement them from scratch? I should not. Whenever I can, I should rely on available examples or, even better, blueprint workflows to jump-start my new data analytics project. The KNIME Hub, for example, is a great source.
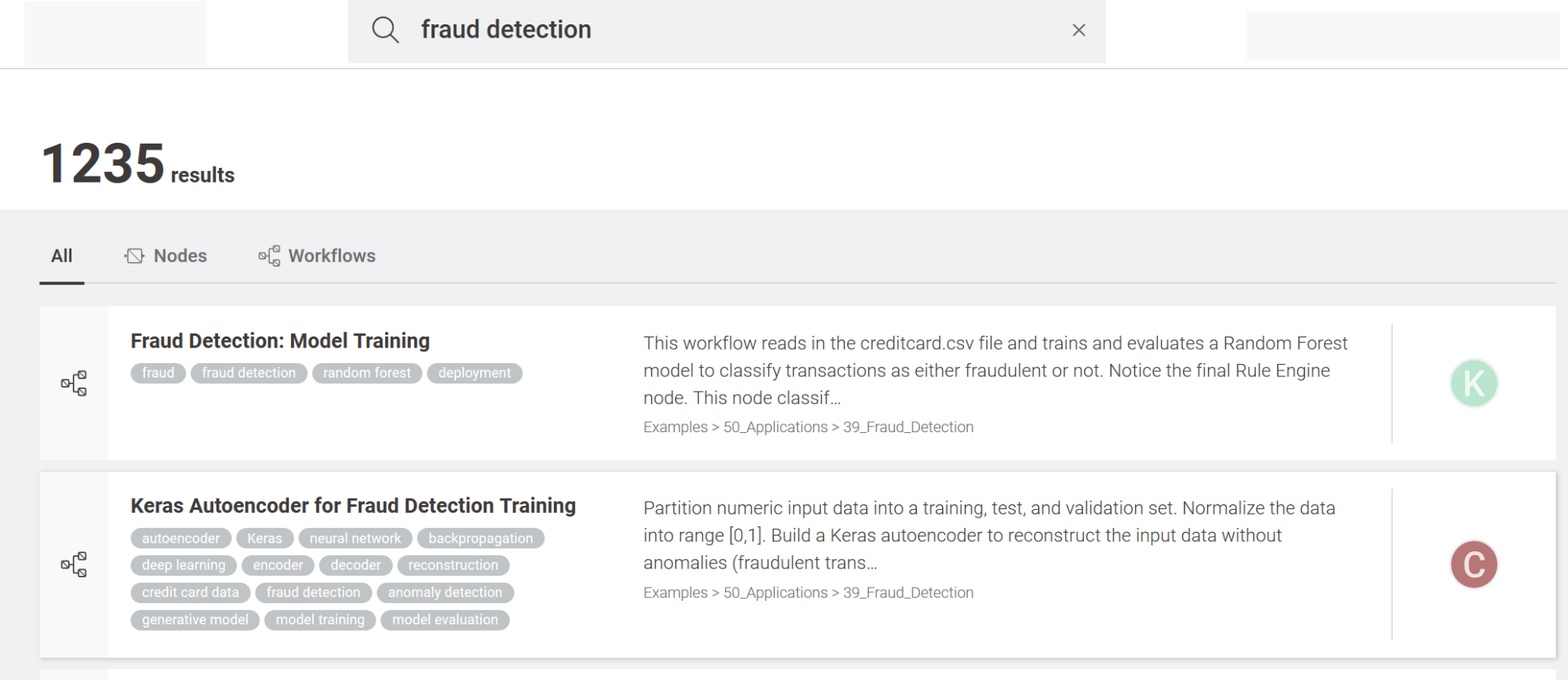
Let’s suppose we’ve been assigned a project on fraud detection. The first thing to do, then, is to go to the Workflow Hub and search for an example on “fraud detection.” The top two results of the search show two different approaches to the problem. The first solution operates on a labeled dataset covering the two classes: legitimate transactions and fraudulent transactions. The second solution trains a neural autoencoder on a dataset of legitimate transactions only and subsequently applies a threshold on a distance measure to identify cases of possible fraud.
According to the data we have, one of the two examples would be the most suitable one. So, we can download it and customize it to our particular data and business case. This is much easier than starting a new workflow from scratch.
Again, if these applications are so classic and the steps always the same, couldn’t I use a framework (always the same) to run them automatically? This is possible! And especially so for the simplest data analysis solutions. There are a number of tools out there for guided automation. Let’s search the Workflow Hub again. We find a workflow called “Guided Automation,” which seems to be a blueprint for a web-based automated application to train machine learning models for simple data analysis problems.
Actually, this “Guided Automation” blueprint workflow also includes a small degree of human interaction. While for simple, standard problems a fully automated solution might be possible, for more complex problems, some human interaction is needed to steer the solution in the right direction.

More innovative data science projects
Now for the remaining part of a data scientist’s projects — which in my experience amount to approximately 20% of the projects I work on. While most of the data analytics projects are somewhat standard, there is a relatively large amount of new, more innovative projects. Those are usually special projects, neither classic nor standard, covering the investigation of a new task, the exploration of a new type of data, or the implementation of a new technique. For this kind of project, you often need to be open in defining the task, knowledgeable in the latest techniques, and creative in the proposed solutions. With so much new material, it is unlikely that examples or blueprints can be found on some repository. There is really not enough history to back them up.
Machine learning for creativity
One of the most recent projects I worked on was aimed at the generation of free text in some particular style and language. The idea is to use machine learning for a more creative task than the usual classification or prediction problem. In this case, the goal was to create new names for a new line of outdoor clothing products. This is traditionally a marketing task, which requires a number of long brainstorming meetings to come up with a list of 10, maybe 20, possible candidates. Since we are talking about outdoor clothing, it was decided that the names should be reminiscent of mountains. At the time, we were not aware of any targeted solution. The closest one seemed to be a free text generation neural network based on LSTM units.
We collected the names of all the mountains around the world. We used the names to train an LSTM-based neural network to generate a sequence of characters, where the next character was predicted based on the current character. The result is a list of artificial names, vaguely reminiscent of real mountains and copyright-free. Indeed, the artificial generation guarantees against copyright infringement, and the vague reminiscence of real mountain names appeals to fans of outdoor life. In addition, with this neural network, we could generate hundreds of such names in only a few minutes. We just needed one initial arbitrary character to trigger the sequence generation.
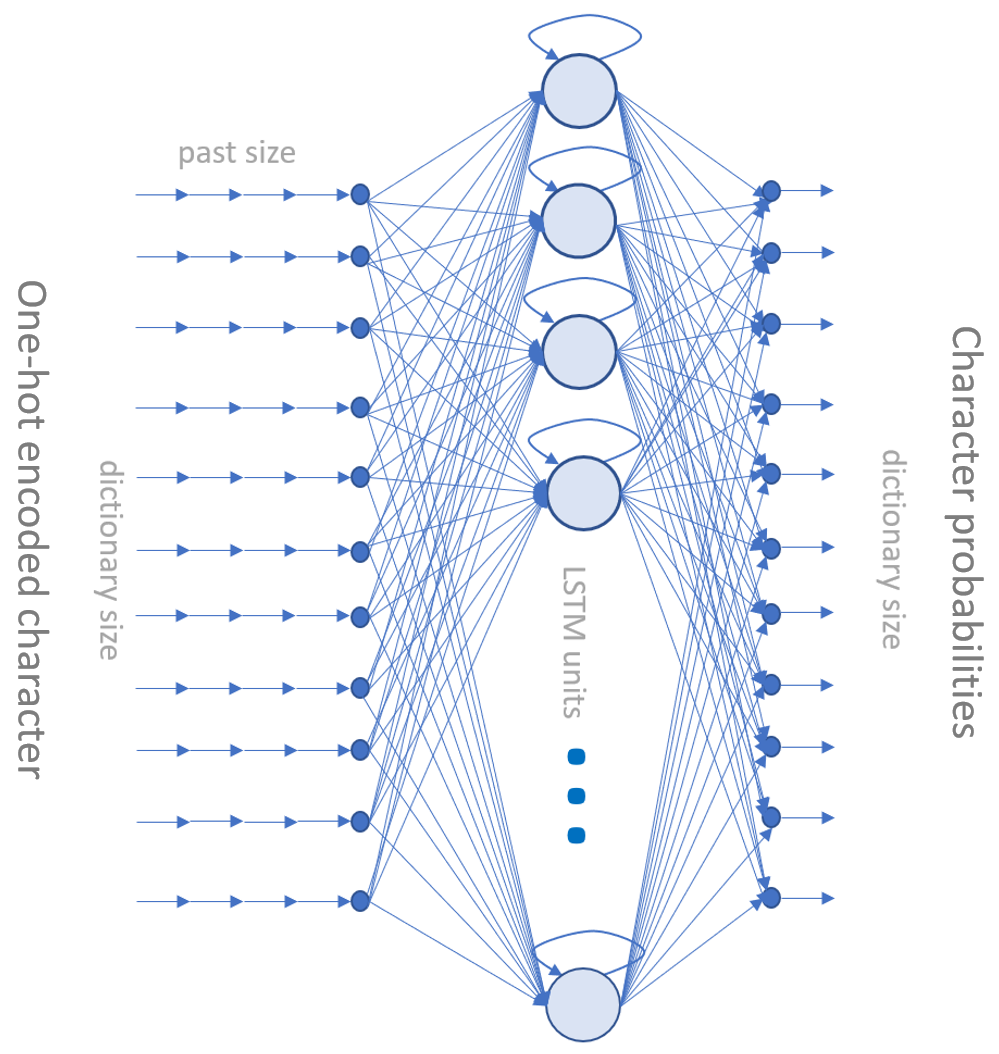
This network can be easily extended. If we expand the sequence of input vectors from one past character to many past characters, we can generate more complex texts than just names. If we change the training set from mountain names to let’s say rap songs, Shakespeare’s tragedies, or foreign language texts, the network will produce free texts in the form of rap songs, Shakespearean poetry, or texts in the selected foreign language, respectively.
Classic and innovative data science projects
When you talk to data scientists, keep in mind that not all Data Science projects have been created equally.
Some Data Science projects require a standard and classic solution. Examples and blueprints for this kind of solution can be found in a number of free repositories, e.g., the Workflow Hub. Easy solutions can even be fully automated, while more complex solutions can be partially automated with just a few human touches added where needed.
A smaller but important part of a data scientist’s work, however, consists of implementing more innovative solutions and requires a good dose of creativity and up-to-date knowledge on the latest algorithms. These solutions cannot really be fully or maybe even partially automated since the problem is new and requires a few trial runs before reaching the final state. Due to their novelty, there might not be a few previously developed solutions that could be used as blueprints. Thus, the best way forward here is to readapt a similar solution from another application field.