
It's 11:30 am, you’ve got 14,000 customer reviews of US airlines and you have to figure out how people feel about them before lunch.
The main goal of sentiment analysis is to automatically determine whether a text leaves a positive, negative, or neutral impression. It’s often used to analyze customer feedback on brands, products, and services found in online reviews or on social media platforms.
Lexicon-based sentiment analysis is a quick way to get an idea of how people feel about something based on the words they use. It's not perfect because sometimes words can have different meanings depending on the context, but it's a simple method to automate the analysis of vast amounts of text and get fast insight on the fly.
There are different methods to conduct sentiment analysis, from lexicon-based, to traditional machine learning, to deep learning, to natural language processing (NLP), and more.
In this article, learn about lexicon-based sentiment analysis and find out how we built this predictive model, which automatically analyzes the sentiment of 14,000 customer tweets about six US airlines (in time for your lunch-break).
What is lexicon-based sentiment analysis
Lexicon-based sentiment analysis is a technique used in natural language processing to detect the sentiment of a piece of text. It uses lists of words and phrases (lexicons or dictionaries) that are linked to different emotions to label the words (e.g. positive, negative, or neutral) and detect sentiment.
In our example, the words are labeled with the help of a so-called valence dictionary. Each word in the text can have some type of emotional valence, such as “great” (positive valence) or “terrible” (negative valence), which gives us a positive or negative impression of the airline.
Take the phrase “Good airlines sometimes have bad days.”. A valence dictionary would label the word “Good” as positive; the word “bad” as negative; and possibly the other words as neutral.
Once each word in the text is labeled, we calculate an overall sentiment score by counting the numbers of positive and negative words, and then combining the values.
A popular formula to calculate the sentiment score (StSc) is:
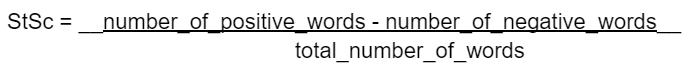
If the sentiment score is negative, the text is classified as negative. A positive score means a positive text, and a score of zero means the text is classified as neutral.
In the lexicon-based approach we can skip the whole process of building a machine learning model. Instead, we can analyze the overall sentiment on-the-fly, calculating sentiment scores based on our valence dictionary.
Tip: Valence dictionaries are language-dependent. You can usually source them from linguistic departments of national universities. For example, here are valence dictionaries for Chinese and Thai.
Conduct lexicon-based sentiment analysis with low-code
In our example, we’ll walk through how we built a lexicon-based predictor for sentiment analysis. We used the low-code KNIME Analytics Platform, which is open source and free to download. The intuitive low-code environment means you don’t have to know how to code to conduct the analysis.
- You can download the example workflows for this project from the KNIME Hub.
- Our data comes from a Kaggle dataset that contains over 14K customer reviews of six US airlines.
- Each review is a tweet that’s been labeled as positive, negative, or neutral by contributors. One of our goals is to verify how closely our sentiment scores match the sentiment determined by these contributors.This will give us an idea of how promising and efficient this approach is.
Let’s get started.
Preprocess the data
The first step is to clean up the data to make it workable. If it contains duplicate information, for example, this could skew the results of our analysis.
Start by removing any duplicate tweets from the dataset with the Duplicate Row Filter.
Next, to analyze the tweets, convert their content and the contributor-annotated overall sentiment of the tweets into documents using the Strings To Document node.
Tip: Document is the required type format for most text mining tasks in KNIME, and the best way to inspect Document type data is with the Document Viewer node.
These documents now contain all the information we need for our lexicon-based analyzer. That means we can exclude all the other columns from the processed dataset. Do this with the Column Filter.
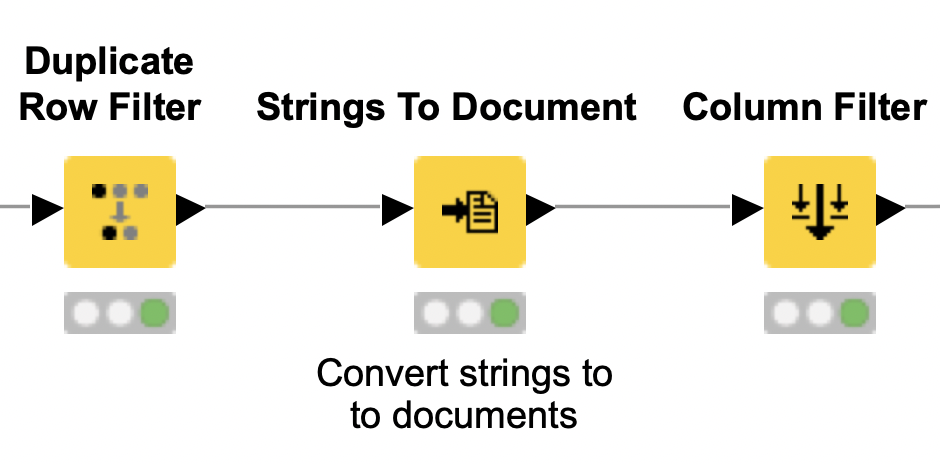
Tag positive/negative words
Now use a valence dictionary to label all the words in the documents we created from each tweet.
In the example workflow, we used the English dictionary from MPQA Opinion Corpus. It contains two lists: one for positive words and one for negative words.
Tip: Alternative formulas for sentiment scores calculate the frequencies of neutral words, either using a specific neutral list or by tagging any word that is neither positive nor negative as neutral.
Next, give each word in each document a sentiment tag by comparing them against the two lists. You can do this with two Dictionary Tagger nodes (one for positive, one for negative). The goal here is to ensure that sentiment-laden words are marked as such. Then, you process the documents again, and use the Tag Filter to keep only those words that were tagged.
Note that since we’re not tagging neutral words here, all words that are not marked as either positive or negative are removed in this step.
Now, the total number of words per tweet, which we need to calculate the sentiment scores (with the above formula), is equivalent to the sum of positive and negative words.
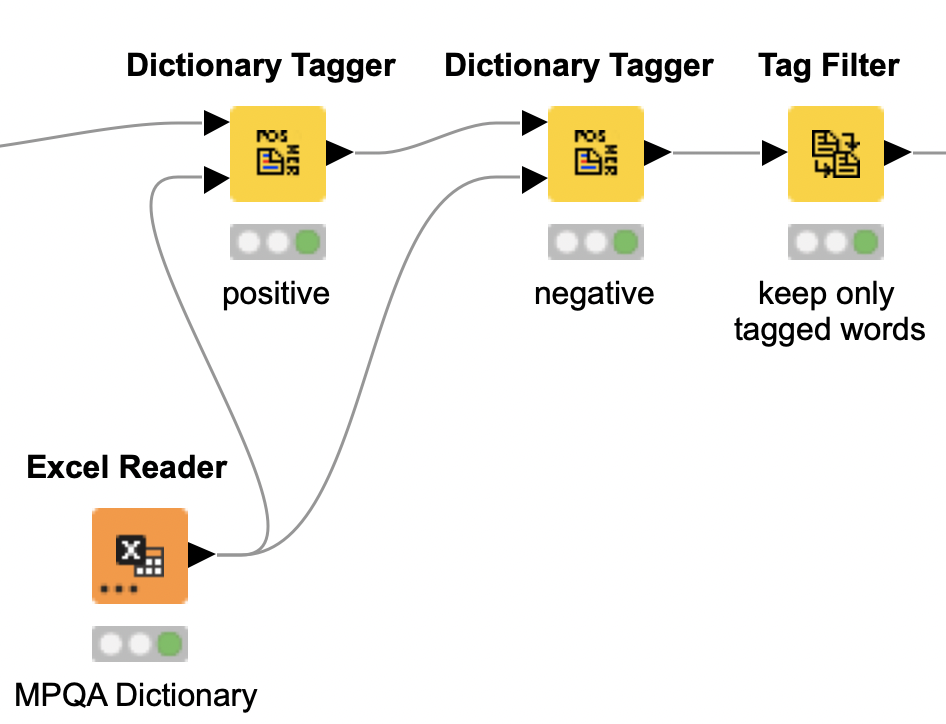
Count numbers of positive/negative words
Now it’s time to generate a sentiment score for each tweet. Use the filtered lists of tagged words to determine how many positive and negative words are present in each tweet.
Start this process by creating bags of words for each tweet with the Bag Of Words Creator. It creates a table that contains all the words from our preprocessed documents, placing each one into a single row.
Next, count the frequency of each tagged word in each tweet with the TF node. You can configure it to use integers or weighted values, relative to the total number of words in each document.
Since tweets are very short, using relative frequencies (weighted values) is not likely to offer any additional normalization advantage for the frequency calculation. For this reason, we use integers to represent the words’ absolute frequencies.
Now extract the sentiment of the words in each tweet (positive or negative) with the Tags to String node, and finally calculate the overall numbers of positive and negative words per document by summing their frequencies with the Pivoting node.
For consistency, if a tweet does not have any negative or positive words at all, we set the corresponding number to zero with the Missing Value node. To keep the workflow clean and easy to follow, we’ve wrapped this part into a single metanode.
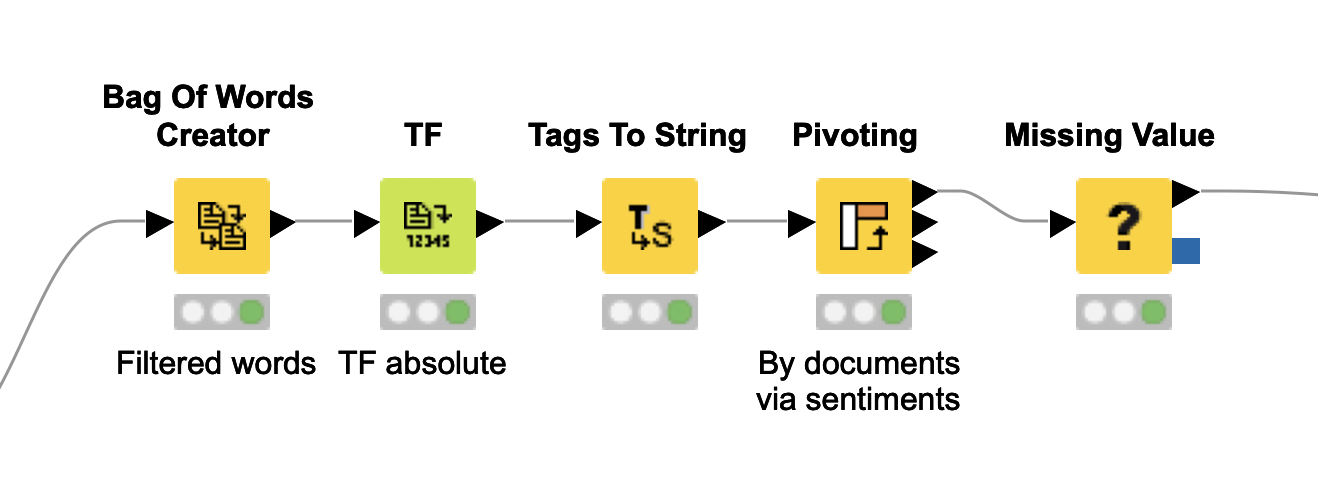
Calculate sentiment scores
Now you’re ready to start the fun part and calculate the sentiment score (StSc) for each tweet.
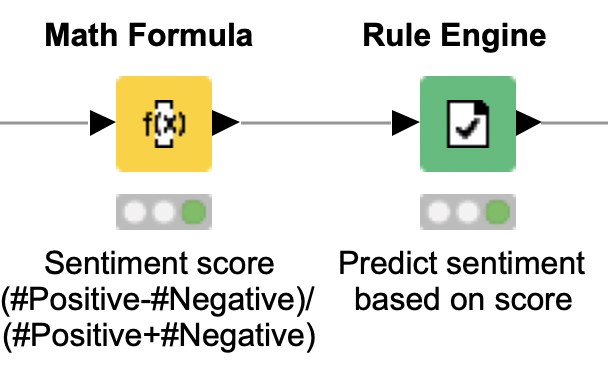
Use the Math Formula node to get the sentiment score by calculating the difference between the numbers of positive and negative words, divided by their sum (see formula for StSc above).
The Rule Engine node now uses this value to decide whether the tweet has a positive or negative sentiment.
Evaluate lexicon-based predictor performance
The tweets were annotated by the contributors as positive, negative, or neutral. This gives us gold data that we can use to compare the results of our lexicon-based predictions.
Remember that a sentiment score > 0 corresponds to a positive sentiment; if the sentiment score = 0, it’s neutral; while a sentiment score < 0 means a negative sentiment. These three categories can be seen as classes, so we can easily frame our prediction task as a classification problem.
To perform this comparison, start by setting the column containing the contributors’ annotations as the target column for classification, using the Category to Class node.
Next, use the Scorer node to compare the values in this column against the lexicon-based predictions.
It turns out that the accuracy of our lexicon-based approach is rather low: Only 43% of the tweets were classified correctly. This approach performed especially badly for neutral tweets, probably because both the formula for sentiment scores and the dictionary we used do not handle neutral words directly. Most tweets, however, were annotated as negative or positive, and the lexicon-based predictor performed slightly better for the former category (F1-scores of 53% and 42%, respectively).
Lexicon-based sentiment analysis for insightful baseline analysis
Lexicon-based sentiment analysis is an easy approach to implement and can be customized without much effort. The formula for calculating sentiment scores could, for example, be adjusted to include frequencies of neutral words and then verified to see if this has a positive impact on performance. Results are also very easy to interpret, as tracking down the calculation of sentiment scores and classification is straightforward.
A lexicon-based sentiment predictor is insightful for preliminary, baseline analysis. It provides analysts with insights at a very low cost and saves them a lot of time otherwise spent analyzing data in spreadsheets manually.
Explore the workflow we have described here and try out the effect of adjusting how sentiment scores are calculated.