
Businesses are successfully using natural language processing for tasks like content moderation – monitoring social media for hate speech, designing neural machine translation tools – translating websites or tourism brochures in multiple languages, and developing question-answering services – online chatbots that provide customers with immediate responses.
Natural languages are articulated and interdependent “organisms” which poses a number of challenges for automatically understanding and processing them. From phrasing ambiguities to misspellings, words with multiple meanings, phrases with multiple intentions, and more, designing a sophisticated language model that accounts for context, variations in meaning, and the full complexity of a message is an arduous task.
Today we’ll show how you can use BERT, an innovative transformer-based language model, without having to learn to code.
Note. BERT stands for Bidirectional Encoder Representations from Transformers. It is a deep neural network architecture built on the latest advances in deep learning for NLP. It was released in 2018 by Google, and achieved State-Of-The-Art (SOTA) performance in multiple natural language understanding (NLU) benchmarks. Today, other transformer-based models, such as GPT-3 (read more about GPT-3 in KNIME) or PaLM, have outperformed BERT. Nevertheless, BERT represents a fundamental breakthrough in the adoption and consolidation of transformer-based models in advanced NLP applications.
Use BERT with KNIME
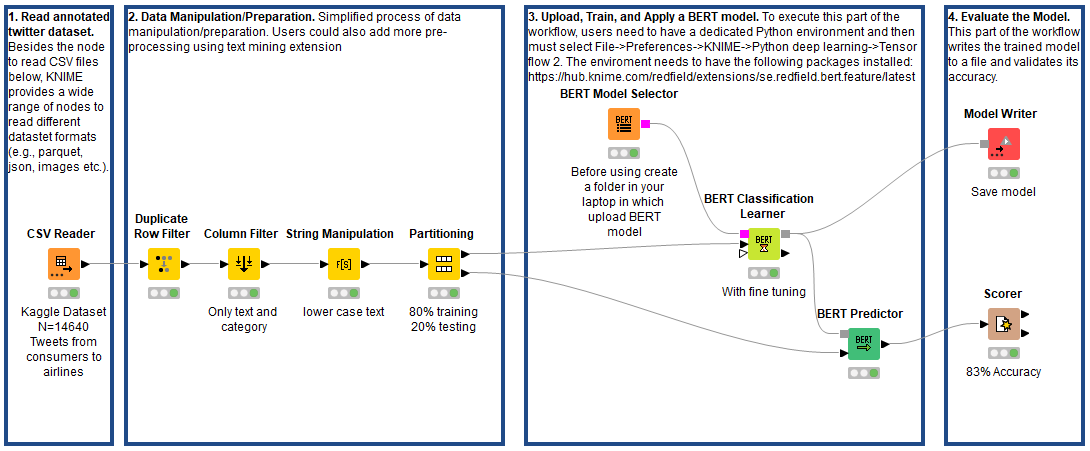
Harnessing the power of the BERT language model for multi-class classification tasks in KNIME Analytics Platform is extremely simple. This is possible thanks to the Redfield BERT Nodes extension, which bundles up the complexity of this transformer-based model in easy-to-configure nodes that you can drag and drop from the KNIME Hub (Fig. 1).

Similarly to other deep learning implementations with KNIME, the BERT nodes require the set up of the KNIME Python Integration and the installation of all necessary dependencies in a defined Python Deep Learning environment.
Note. It is good practice to create a separate Conda environment for each project and install the necessary dependencies. Read more about How to Set Up the Python Extension and Manage Your Python Environments with Conda and KNIME.
Train a sentiment predictor of US airline reviews
We want to build and train a sentiment predictor of US airline reviews, capitalizing on the sophistication of language representation provided by BERT. For this supervised task, we used an annotated Twitter US Airline Sentiment dataset with 14,640 entries available for free on Kaggle. Among other things, the dataset contains information about the tweetID, the name of the airline, the text of the tweet, the username, and the sentiment annotation – positive, negative, or neutral.
To build our classifier, we ingested the data, performed minimal preprocessing operations (i.e. duplicate removal and lowcasing), and partitioned our dataset in trainset (80%) and testset (20%). Next we rely on the BERT nodes to train and apply our classifier.
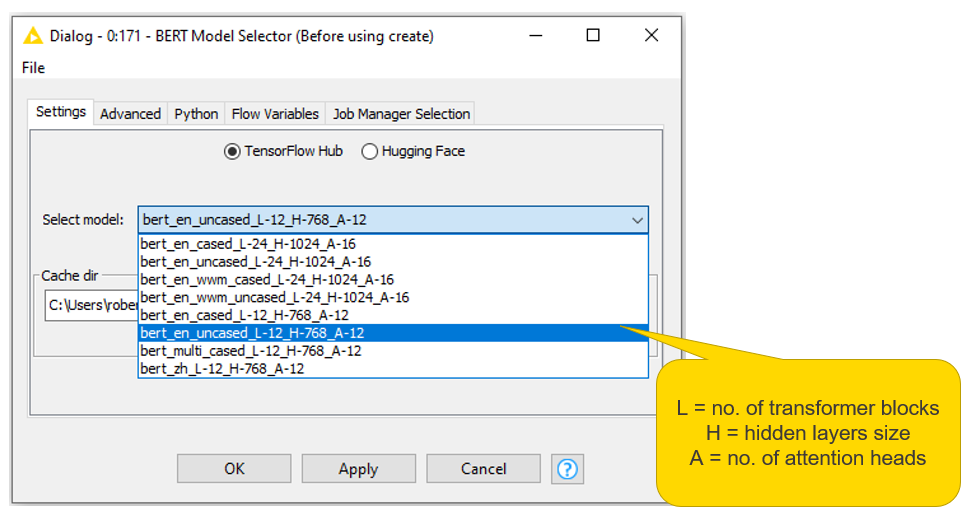
The BERT Model Selector node allows you to download the pretrained BERT models available on TensorFlow Hub and HuggingFace, then store them in a local directory. We can choose among several model options, taking into account the size of the transformer architecture, the language the model was trained on (“eng” for English, “zh” for Chinese, or “multi” for the 100 languages with the largest Wikipedia pages), or whether the model is sensitive to cased text. A detailed list of all available models is provided here. For our predictor, we selected the uncased English BERT with a base transformer architecture (Fig. 2).
The BERT Classification Learner node: This node uses the BERT model and adds three predefined neural network layers: a GlobalAveragePooling, a Dropout, and a Dense layer. Adding these layers adapts the selected model to a multiclass classification task.
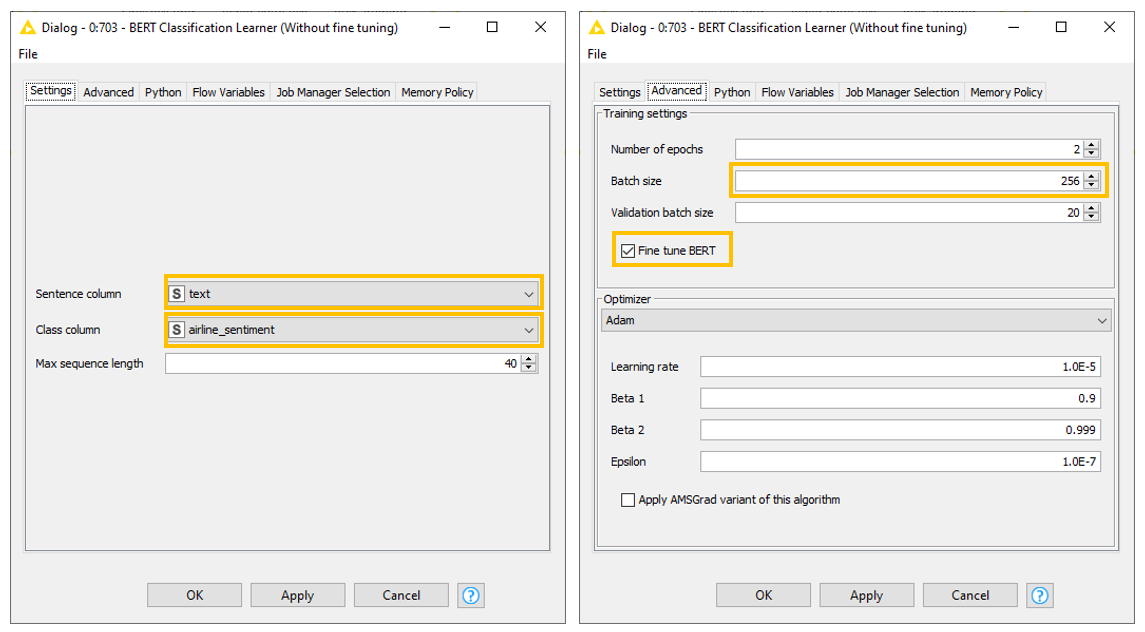
The configurations of this node are very simple. All we need to do is select the column containing the tweet texts, the class column with the sentiment annotation, and the maximum length of a sequence after tokenization. In the “Advanced” tab, we can then decide to adjust the number of epochs, the training and validation batch size, and the choice of the network optimizer.
Notice the box “Fine tune BERT.” If checked, the pretrained BERT model will be trained along with the additional classifier stacked on top. As a result, fine-tuning BERT takes longer, but we can expect better performance (Fig. 3).
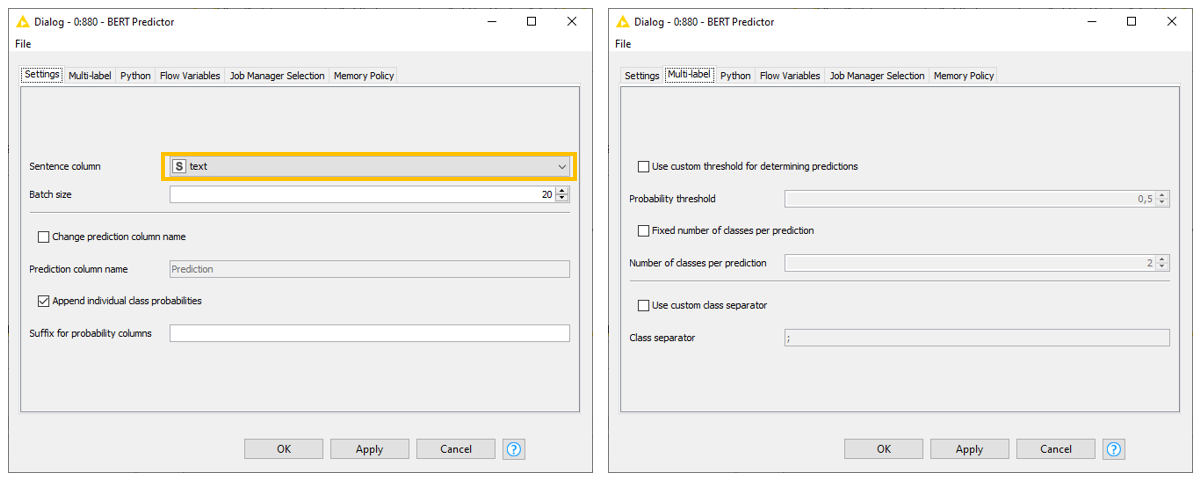
The BERT Predictor node: This node applies the trained model to unseen tweets in the testset. Configuring this node follows the paradigm of many predictor nodes in KNIME Analytics Platform. It’s sufficient to select the column for which we want the model to generate a prediction. Additionally, we can decide to append individual class probabilities, or set a custom probability threshold for determining predictions in the “Multi-label” tab (Fig. 4).
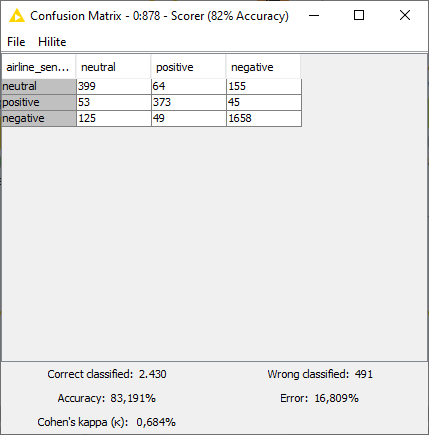
Upon full execution of the BERT Predictor node, we evaluated the performance of the model using the Scorer node, then saved it for deployment. Fig. 5 shows that the multiclass sentiment classifier powered by BERT obtained 83% accuracy. Increasing the number of epochs during training is likely to result in even higher performance.
Note. The workflow Building Sentiment Predictor - BERT (Fig. 6) is publicly available to download from the KNIME Hub.
Deploy the sentiment predictor on new tweets
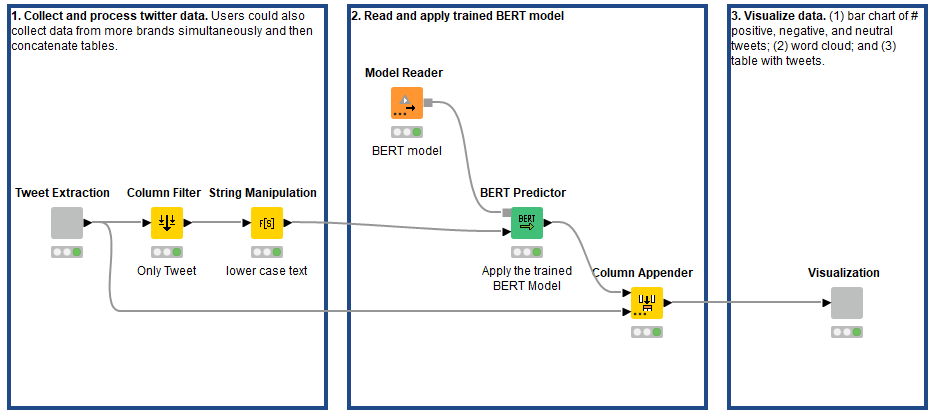
After assessing the performance of our predictor, we implemented a second workflow to show how our predictive model could be deployed on unlabeled data. The mechanics of both workflows are very similar.
We collected new tweets around @AmericanAir for a week using the KNIME Twitter Connectors nodes, then wrapped them in the “Tweet Extraction” component.
Afterwards, we replicated the minimal text preprocessing steps in the training workflow, imported the trained BERT model, and applied it to the new unlabeled tweet data using the BERT Predictor node (Fig. 7).
Given the lack of sentiment labels in the newly collected tweets, we can only assess the performance of the BERT-based predictor subjectively, relying on our own judgment.
Note. The workflow Deploying Sentiment Predictor - BERT is publicly available to download from the KNIME Hub.
Create a Dashboard to Visualize and Assess Performance
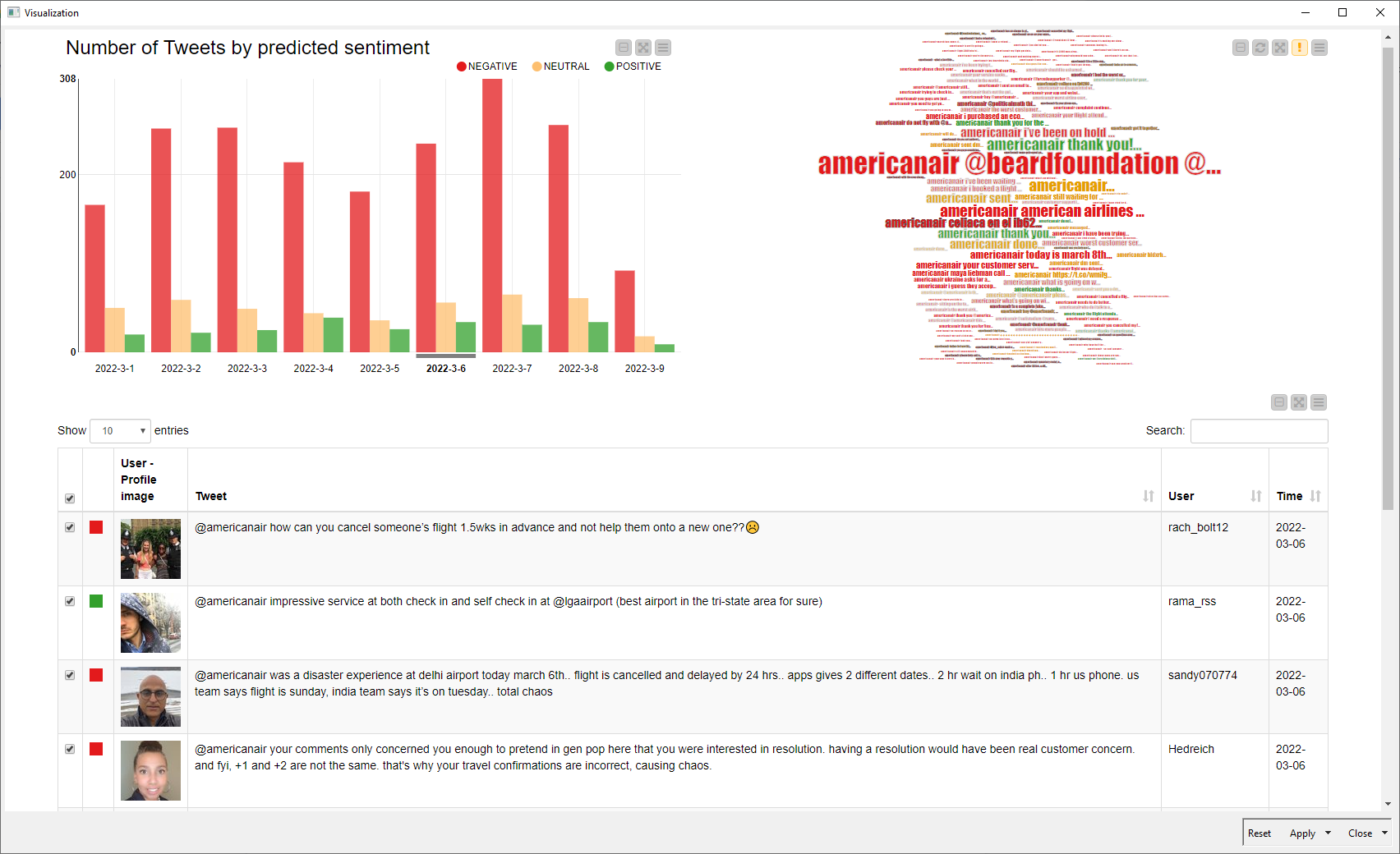
To help us assess the performance, we created a dynamic and interactive dashboard that combines (1) the tweets, (2) a word cloud with color-coded tweets whose size depends on their usage frequency, and (3) a bar chart with the number of tweets per sentiment per date. Users can click different bars in the bar chart or tweets in the word cloud to modify the content selection.
Taking a look at Fig. 8, the chart indicates that the number of tweets with negative sentiments is considerably larger than those with neutral and positive sentiments over the week. Similarly, the word cloud is mostly colored red. If we examine the actual tweets, we can see that we’ve confirmed the high performance of the BERT-based predictor as assessed during training. It is worth noticing that BERT is able to correctly model dependencies and context information for fairly long tweets, leading to accurate sentiment predictions.
Higher Complexity for Better Language Modeling
BERT-based sentiment analysis is a formidable way to gain valuable insights and accurate predictions. The BERT nodes in KNIME remove the technical complexity of implementing this architecture, and let everyone harness its power with just a few clicks.
While BERT’s underlying transformer architecture, with over 110 million parameters, makes it fairly obscure to interpret and computationally expensive to train, its ability to effectively model the complexity of natural languages ensures consistently superior performance on a number of NLP applications compared to other deep learning architectures for sequential data or traditional machine learning algorithms. The tradeoff between complexity and accuracy is here to stay.
Tip. Read more about how KNIME supports marketing analytics for enterprises.