
Most data science ideas die at deployment.
The reasons vary from technical (no way to store or access large amounts of data), to political (no way to get IT to prioritize your projects), to financial (no way to get budget for the infrastructure you might need).
At KNIME, we’re dedicated to building an end-to-end platform that addresses each deployment hurdle:
- Our open approach ensures that the platform is compatible with every analytics tool in your toolbox.
- Our intuitive visual platform helps cross-discipline collaboration, so that Python scripters, SQL coders, and front and backend engineers in IT have a common language.
- Our platform supports both the creation and operationalization of data science, so that models don’t have to be re-coded or reworked.
All of these efforts remove friction from the work of data experts, but also, importantly, provide choice. Data experts can store data where and how they want, access it how they want, and deploy their models as REST APIs, data apps, or simple static reports. So when we heard that customers were running into issues of scale or wanted to move computation to local devices, we decided to build KNIME Edge.
Today, we’re announcing the fruits of that labor: data science inference services. KNIME Edge offers data and IT teams a cost efficient approach to deploying internet-scale apps, serving hundreds, thousands, or millions of end users with the models they’ve built.
Who is KNIME Edge for?
Data and IT teams can now provide inference workflows as a service. Applying models at the edge is a technical solution for a number of requirements, typically saving IT teams on costs, minimizing latency, increasing reliability, and enabling deployment of inference services in multiple geographic regions.
More specifically, here are a few use cases in which you’d consider moving model applications to the edge.
Allow for low-internet connectivity where data is being generated. Teams who are building solutions in the sustainable energy industry, for instance, might be looking to use data science to optimize output of limited renewable energy sources, such as solar and wind power. With KNIME Edge, teams can apply models on-site that can optimize supply levels at extremely low latency, so the teams can make sure that the product is meeting demands.
Apply the same models to a wide geographic distribution. Teams who are building predictive maintenance solutions for factories across dozens or hundreds of locations, for instance, need a way to deploy that model to all locations globally. With KNIME Edge, models can be applied locally within factories, using KNIME Server as the central point of model operations.
Operationalize your models for internet-scale numbers of end users. Teams who are applying models for real-time product recommendations on an e-commerce site need the model to be able to handle thousands of concurrent requests. With KNIME Edge, even complex models that handle a large amount of data can be applied instantly.
Get low and consistent latency despite spikes in demand. Teams who are building services for, say, fraud detection, need results instantly and reliably to ensure remediation happens quickly. With models being applied on the edge, these teams can avoid downtime and minimize fraud-related costs.
To hear how the new feature is being used in the real world, watch TODO1’s Edgar Osuna present how he used KNIME to deploy a real-time fraud detection service.
Create, Deploy, and Manage, all with KNIME
If you’re already using KNIME Software, you can use the same platform to both build and deploy data services.
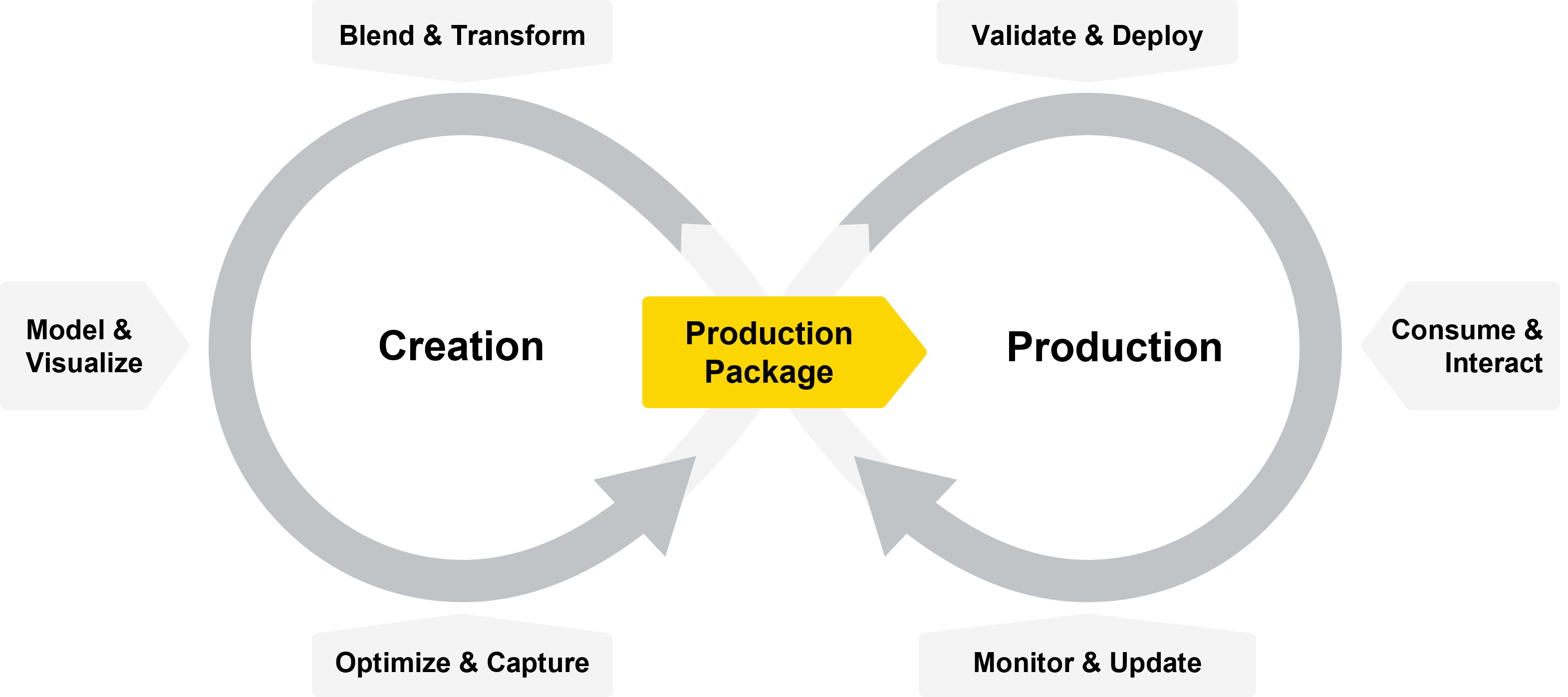
KNIME Software enables business, data, and IT teams to work collaboratively, using the same environment through each step of the data science life cycle:
- Blend & transform: After defining the business problem, the data team gets data into shape and explores different solutions.
- Model & Visualize: The data team builds and trains their models.
- Optimize & Capture: Using KNIME’s Integrated Deployment feature, the data team defines what part of the data flow needs to be captured for deployment—typically including pre-processing steps and model application.
- Validate & Deploy: Together with IT, the data team can choose how they’d like to deploy their models—via a data app or via an API.
- Consume & Interact: The data & IT team can choose to have the models applied in a centralized place (if they’re serving a small team), or on the edge, so they can handle a high number of requests.
- Monitor & Update: IT, data and MLOps teams can make sure that the models are still working as expected in production. Using KNIME, quality checks can be put in place using KNIME workflows. In the cases of model drift, data science teams can work on and roll out updated versions of their models without starting from scratch each time.
Data science is a collaborative discipline that requires cross-functional participation to get a single project from an idea to a fully functioning REST service. For efficient and meaningful work across disciplines, KNIME provides a single environment for the building and deploying of enterprise-grade data science.
KNIME Edge is Now Available
To learn whether KNIME Edge is appropriate for your team, get in touch with our Customer Care team.