
The latest release of KNIME Analytics Platform 3.4 has produced many new features, nodes, integrations, and example workflows. This is all to give you a better all-round experience in data science, enterprise operations, usability, learning, and scalability.
Now, when we talk about scalability, the cloud often comes to mind. When we talk about the cloud, Microsoft Azure often comes to mind. That is the reason why KNIME has been integrating some of the Azure products and services.
The novelty of this latest release consists of the example material. If you currently access (or want to access in the future) some Microsoft products, on the cloud, in your KNIME workflow, you can start by having a look at the 11_Partners/01_Microsoft folder in the EXAMPLES server and at the following link on the KNIME Node Guide https://www.knime.com/nodeguide/partners/microsoft.
A little note for the neophytes among us. The KNIME EXAMPLES server is a public KNIME server hosting a constantly growing number of example workflows (see YouTube video “KNIME EXAMPLES Server”). If you are new to a topic, let’s say “churn prediction”, and you are looking for a quick starting point, then you could access the EXAMPLES server in the top left corner inside the KNIME workbench, download the example workflow in 50_Applications/18_Churn_Prediction (50_Applications/18_Churn_Prediction/01_Training_a_Churn_Predictor*), and update it to your data and specific business problem. It is very easy and one of the most loved features in the KNIME Analytics Platform.
A special section (11_Partners/01_Microsoft) on the EXAMPLES server is dedicated to access and use Microsoft products. Let’s see now what we find in there!
Note. Find all these workflows on the KNIME Hub
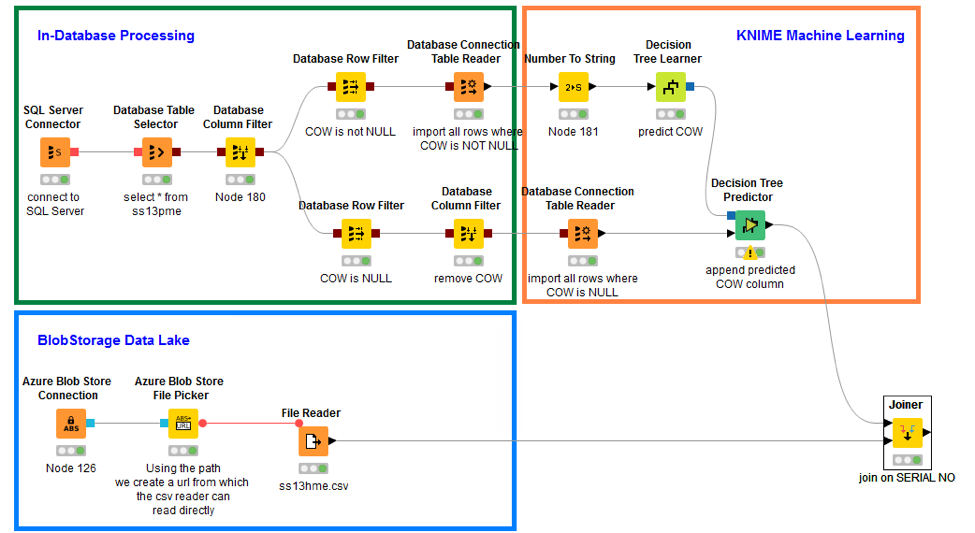
- MS SQL Server. The first example workflow in the folder (11_Partners/01_Microsoft/01_SQL_Server_InDB_Processing(Azure)11_Partners/01_Microsoft/01_SQL_Server_InDB_Processing(Azure)*) shows how to run a few in-database operations on a MS SQL Server. Connection to the database happens through a dedicated connector node, named SQL Server Connector. In-database processing operations are implemented via dedicated SQL nodes, using a GUI in their configuration window, or via a SQL Query node for free SQL code.
Note. The SQL Server Connector node would connect equally well to Microsoft DW as it does to MS SQL Server, provided that the right JDBC driver is installed. So this example workflow actually works for SQL Server and DW at the same time.
- BlobStorage. The second example workflow (11_Partners/01_Microsoft/02_SQLServer_BlobStorage_andKNIMEModels11_Partners/01_Microsoft/02_SQLServer_BlobStorage_andKNIMEModels*) offers a data blending example. It takes data from MS SQL Server, like in the first example workflow above, and data from BlobStorage. The Azure BlobStore Connection node connects to a BlobStorage installation on the Azure cloud, the Azure BlobStore File Picker node allows for exploration of the BlobStorage repository and for the selection of one file. The full file path is then passed via flow variable to a more classic File Reader node.
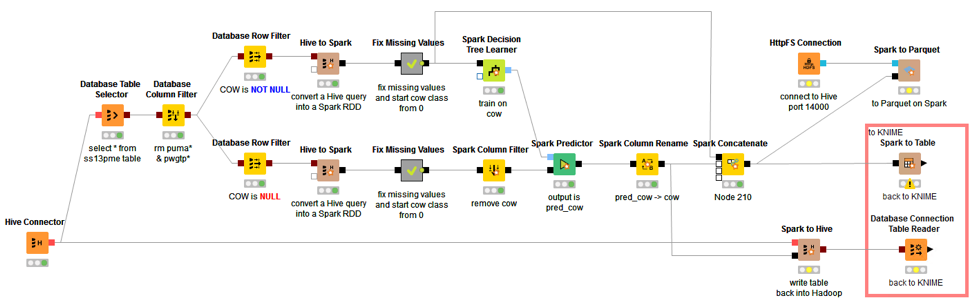
- HDInsight Hive. Example workflow 11_Partners/01_Microsoft/03_HDI_Hive_KNIME11_Partners/01_Microsoft/03_HDI_Hive_KNIME* accesses Hive in an Azure HDInsight installation. Similarly to the SQL Server example, here a Hive Connector, a dedicated connector, connects to the Hive database and a number of In-database processing nodes prepares the data to train a Decision Tree Learner node, which is a KNIME native node.
- HDInsight Spark. 11_Partners/01_Microsoft/04_HDI_Hive_Spark11_Partners/01_Microsoft/04_HDI_Hive_Spark* conceptually implements exactly the same workflow as in 03.HDI_Hive_KNIME, but here the mix and match effect is obtained by inserting Spark based model training nodes rather than KNIME native nodes. Data transfer from Hive to Spark and RDD creation happen through the Hive To Spark nodes. Transfer data operations and RDD creation can also happen through a variety of other nodes available, like Database to Spark, JSON To Spark, and Parquet To Spark. In this example, we also train a Spark Decision Tree. Many more data mining algorithms are available from the Spark Machine Learning library. Just type “Spark” in the search box above the Node Repository to fully explore the KNIME Spark integration.
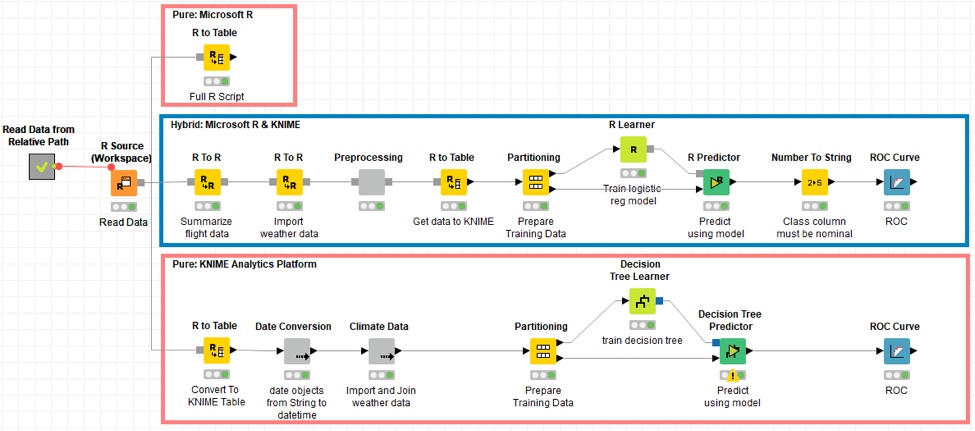
- Microsoft R. We have reached the last example workflow (11_Partners/01_Microsoft/05_Predict_DepartureDelays_with_MicrosoftR11_Partners/01_Microsoft/05_Predict_DepartureDelays_with_MicrosoftR*) of the batch produced with the latest release of KNIME Analytics Platform 3.4. The KNIME R integration fully supports Microsoft R. It provides a full set of nodes to write R scripts, train and/or apply R models, and produce R graphs. It is sufficient to set the pointer of the R executable to a Microsoft R installation in the KNIME Preferences page. The following video explains step by step how to configure and use the Microsoft R integration within KNIME Analytics Platform.
The 05.Predict_DepartureDelays_with_MicrosoftR workflow trains a model to predict whether a flight will be delayed at departure when leaving from ORD airport. It shows this same operation 3 times.
- “Pure Microsoft R” uses only R code written in the R Snippet node.
- “Hybrid Microsoft R & KNIME” mixes R code based nodes with KNIME GUI based nodes
- “Pure KNIME Analytics Platform” runs the whole procedure again using only KNIME nodes
Indeed, not all data scientists are created equally R experts. For the R coding wizards, the standalone implementation using the R Snippet node as R editor is probably what they prefer. However, for the other less R experts, the other two implementations might be more suitable. Indeed, breaking up R code in smaller easier pieces and mixing and matching with KNIME nodes, might make the whole R coding experience more pleasant for most of us.
With the ease of use and the extensive coverage of data science algorithms of KNIME Analytics Platform, with the collaboration and production features of the KNIME Server, with the versatility of the Azure platform, with the completeness of the Microsoft data repository offer, the work of a data scientist can become quicker, more efficient, and ultimately more productive.
A touch of Azure in your workflow might just be a welcome addition!
More information is available at the following links:
* The link will open the workflow directly in KNIME Analytics Platform (requirements: Windows; KNIME Analytics Platform must be installed with the Installer version 3.2.0 or higher)