FAQ
Below are answers to some of our most commonly asked questions. If you can't find what you need here, please have a look at our forums as well; we have a vibrant and helpful user community!
Note that the following FAQs concentrate on KNIME usage. If you are developing your own node, please refer to the Developer FAQs.
- What is KNIME, what does KNIME stand for and who has developed KNIME?
- How do I cite KNIME?
- Can I modify, publish, transmit, transfer or sell, reproduce, create derivative works from, distribute, perform, display, or in any way exploit any of the content, in whole or in part?
- Can I use screenshots of KNIME in my work?
- How much data can I process with KNIME?
- How can I increase the Java Heap Space for KNIME?
- I cannot start KNIME on Windows, I do not even see a splash screen? How do I make it work?
- I extracted the UpdateSite.zip (or parts of it) into the KNIME installation folder, but the new nodes do not appear in the Node repository.
- The Node Description window doesn’t work on Linux, it shows the error "System browser cannot be initialized. No node description will be displayed."
- The Layout Editor window doesn't show up, but only a warning message is displayed: "The Layout Editor/ Configuration Editor has experienced a problem. The following FAQ might help. You can still use the advanced tab to set the layout."
- Is there any way to run KNIME in batch mode, i.e. only on command line and without graphical user interface?
- The workspace is empty how do I create a new project?
- The Node Repository shows only a few nodes (or none at all)
- What kind of data is transmitted when I agree to send anonymous usage data?
- I am running Fedora 10 using the Gnome window manager. The KNIME main application works as expected but as soon as I open a view or a dialog, this panel does not get repainted. Why?
- How can I force KNIME to cache any intermediate data to disk in order to reduce memory usage?
- I am getting an OutOfMemoryError when reading from a database using the Database Reader or Database Connection Reader node. What can I do?
- I'd like to change KNIME's default configuration on the Mac but can't see the knime.ini. Where is it located?
- How do I connect to my Microsoft Access database?
- Menu doesn't appear on Ubuntu with Unity desktop
- Menu icons are not visible on Linux
- I cannot update/install additional extension or access the example workflow server because I am behind a firewall.
- The new interactive R integration does not recognize JRI library: org.rosuda.REngine.REngineException: Cannot load JRI native library.
- Some R nodes run infinitely with R 3.1.0.
- KNIME crashes after the splash screen on Linux with the error message a fatal error has been detected in libsoup-2.4.so in the hs_err_pid.log.
- I'm using the (C)Python extension and want to start python via a wrapper script as opposed to just "/usr/bin/python". How does such a script look like?
- KNIME got stuck and doesn't respond any more.
- Microsoft Word does not work after installing KNIME 3.0.0
- Problems connecting to public example server
- Using recent Linux versions the KNIME main application is not responsive and shows screen artifacts
- "Open With" always uses the same KNIME installation although I specified a different location
- Shared installations of KNIME Analytics Platform
- Issue displaying non-Latin (e.g. Korean) characters in Windows 10
- I get an error message when I want to execute or open a view on nodes with a JavaScript view on Linux
- Which version of Java does KNIME Analytics Platform rely on?
- Backwards-compatibility issues with Extract Date&Time Fields (deprecated)
- My KNIME Analytics Platform takes forever to start up. How can I make it faster?
- Since updating to KNIME Analytics Platform 4.0, I am running out of system resources more frequently. What can I do?
- Legacy Swing‑based dialogs don’t work on Linux when using Wayland and Equo Chromium v128
- Starting with KNIME Analytics Platform 5.1 HTTP connections (e.g. via "GET Request" node) no longer work with authentication behind a proxy. Is there a workaround?
- KNIME crashes or shows UI issues on Linux with errors mentioning "libswt-pi3-gtk" and "libgdk-3"
What is KNIME, what does KNIME stand for, and where does it come from?
KNIME stands for KoNstanz Information MinEr and is pronounced: [naim] (that is, with a silent "k", just as in "knife"). It is developed by KNIME AG located in Zurich and the group of Michael Berthold at the University of Konstanz, Chair for Bioinformatics and Information Mining. Why is it called "KNIME"? Well, "Konstanz Information Miner" used to be called "Hades" (as the pub some of its creators ended up going to often). But that raised lots of not so nice questions ("so this is where your data ends up when it's not useful anymore?") so we looked for another name. "KIM", the obvious choice was, of course, already taken. However, the Konstanz license plate symbol is "KN", so KNIM was our next choice. Adding a vowel at the end was suggested by a native speaker to "round it off", as he put it. And it appears in "Miner" so we felt ok about it. Plus URLs such as "knime.org", "knime.de", ... were still available at that time...
Learn more in the About section.
How do I cite KNIME?
The recommended way to cite KNIME is to cite the paper with the following BibTeX:
@INPROCEEDINGS{BCDG+07,
author = {Michael R. Berthold and Nicolas Cebron and Fabian Dill and Thomas R. Gabriel and Tobias K\"{o}tter and Thorsten Meinl and Peter Ohl and Christoph Sieb and Kilian Thiel and Bernd Wiswedel},
title = {{KNIME}: The {K}onstanz {I}nformation {M}iner},
booktitle = {Studies in Classification, Data Analysis, and Knowledge Organization (GfKL 2007)},
publisher = {Springer},
ISBN = {978-3-540-78239-1},
ISSN = {1431-8814},
year = {2007}
}
Can I modify, publish, transmit, transfer or sell, reproduce, create derivative works from, distribute, perform, display, or in any way exploit any of the content, in whole or in part?
You may do all this in accordance with the license only. KNIME is available under a dual licensing model. A version under an open source license is available for download from this website. If you need other license terms, please contact us. Refer to the license for more information about the terms of the open source license.
Can I use screenshots of KNIME in my work?
You shall not use any screenshot of a KNIME software version that has not officially been released to the public (e.g. nightly builds or beta versions). You may use screenshots in documentation (including educational material), in tutorials, in videos, or on websites given that (in addition to the previous constraints) you:
- Do not alter the screenshot apart from resizing or adding markers/labels,
- Do not include screenshots in your product's user interface,
- Do not use screenshots that contain third-party content, confidential information, or personal data,
- Do not imply KNIME's affiliation or endorsement.
How much data can I process with KNIME?
Basically, there are no limits, since the data is buffered in an intelligent way. Nevertheless, some algorithms may require too much time and memory for very huge datasets.
How can I increase the Java Heap Space for KNIME?
- In the KNIME installation directory there is a file called knime.ini (under Linux it might be .knime.ini; for MacOS: right click on KNIME.app, select "Show package contents", go to "/Contents/Eclipse/" and you should find a Knime.ini). Open the file,
- Find the entry -Xmx1024m and change it to -Xmx4g or higher (for example).
- (Re)start KNIME.
I cannot start KNIME on Windows, I do not even see a splash screen? How do I make it work?
If you do not even see the KNIME splash screen the system fails to create the Java VM. It seems that the anti-virus software Kaspersky may prohibit the Java VM from allocating enough memory. Thus, there are two workarounds:
- Try to uninstall the Kaspersky components Anti-Dialer and Anti-Spam as proposed in this forum thread.
- Open the knime.ini file in the installation directory and enter smaller values for -Xmx and the -XX:MaxPermSize options.
I extracted the UpdateSite.zip into the KNIME installation folder, but the new nodes do not appear in the node repository.
With Eclipse 3.4 the mechanism how features/plugins are managed has drastically changed (the magic keyword is "p2"). One of the major implication for users is, that they cannot install new features/plugins (i.e. nodes) by just copying the plugins and/or features into the corresponding directories of the Eclipse/KNIME installation. Instead, they must be installed via the Update Manager. One workaround for plugins for which there exists no feature is the dropins folder that Eclipse scans upon each startup. But please use this only if anything else fails! The recommended way is using the Update Manager with the KNIME Update Site or the zipped version of it.
The Node Description window doesn’t work on Linux; it displays the error "System browser cannot be initialized. No node description will be displayed."
KNIME uses the SWT browser widget to display HTML content. This widget requires a proper web browser to be installed. Under Linux usually WebKit is used. However, most recent Linux distributions (e.g. Ubuntu 14.04) ship with an incompatible version of WebKit. If KNIME detects an incompatible version it will disable it altogether because otherwise KNIME may crash.
There are several solutions to this problem
- For KNIME 3.x when using GTK3 (see FAQ) you need to install WebKit for GTK3:
- Under Ubuntu install libwebkitgtk-3.0-0 (sudo apt-get install libwebkitgtk-3.0-0)
- Under Fedora/CentOS/RHEL install webkitgtk (yum install webkitgtk)
- Under openSUSE install webkitgtk3 (zypper install webkitgtk3)
- For KNIME 3.x with GTK3 disabled (see FAQ), and KNIME 2.10 to 2.12: Some distributions offer a package with an older version that can be installed by hand:
- Under Ubuntu install libwebkitgtk-1.0-0 (sudo apt-get install libwebkitgtk-1.0-0)
- Under Fedora/CentOS/RHEL install webkitgtk (yum install webkitgtk)
- Under openSUSE install libwebkitgtk-1_0-0 (zypper install libwebkitgtk-1_0-0)
- For KNIME 2.9 and below or if the above solution does not work: The KNIME Update Site contains a feature called KNIME XULRunner binaries for Linux. If installed, KNIME will use this local XULRunner instead of WebKit. In order to install this feature you must disable the "Group items by category" option in the installation dialog and search for the feature.
For more details on web browser requirements, see the SWT FAQ.
The Layout Editor window doesn't show up, but only a warning message is displayed: "The Layout Editor/ Configuration Editor has experienced a problem. The following FAQ might help. You can still use the advanced tab to set the layout."
KNIME uses the SWT browser widget to display content. The error is probably caused by an upgrade of the WebKit packages from version 2.30.6 to version 2.32.0 and is already reported in the Eclipse bug tracker. They are working on a permanent fix.
A temporary workaround is to downgrade the following packages of your system to version 2.28.1:
- libjavascriptcoregtk-4.0-18
- libwebkit2gtk-4.0-37
- gir1.2-webkit2-4.0
- gir1.2-javascriptcoregtk-4.0
To do so you can use the following command:
sudo apt install libjavascriptcoregtk-4.0-18=2.28.1-1 libwebkit2gtk-4.0-37=2.28.1-1 gir1.2-webkit2-4.0=2.28.1-1 gir1.2-javascriptcoregtk-4.0=2.28.1-1
Is there any way to run KNIME in batch mode, i.e. only on command line and without the graphical user interface?
There is a command line option allowing the user to run KNIME in batch mode. To see a list of possible arguments execute the following line on a command prompt (for Linux):
knime -nosplash -application org.knime.product.KNIME_BATCH_APPLICATION
On Mac the executable is not directly located in the KNIME application directory but in a sub folder of the application bundle:
knime.app/Contents/MacOS/knime -nosplash -application org.knime.product.KNIME_BATCH_APPLICATION
On a Windows system, you need to add two more options to enable system messages (by default any message to System.out is suppressed):
knime.exe -consoleLog -noexit -nosplash -application org.knime.product.KNIME_BATCH_APPLICATION
The option:
-consoleLog
Causes a new window to be opened containing the log messages and will keep the window open after the execution has finished. You will need to close the window manually and an error message is produced from the Java process which you can safely ignore. (If you happen to find out how this procedure can be avoided or simplified, please let us know.)
--launcher.suppressErrors
If this is specified, then the launcher will not display a message box with errors if a problem was encountered. This allows the launcher to be used in unattended tests or builds without blocking on an error.
-nosave
If this is specified, the workflow is not saved after execution has finished.
-preferences=file.epf
Path to the file containing eclipse/knime preferences.
-reset
Reset workflow prior to execution.
If you pass no options, all available options will be listed.
In order to run a workflow, named "Knime_project" contained in the workspace directory, execute in one line:
knime -nosplash -application org.knime.product.KNIME_BATCH_APPLICATION -workflowDir="workspace/Knime_project"
In order to run a workflow, name "Knime_project.zip" exported as an .zip file, execute in one line:
knime -nosplash -application org.knime.product.KNIME_BATCH_APPLICATION -workflowFile="PATH_TO_FILE/Knime_project.zip"
It's also possible to change the configuration of the workflow through workflow variables. If a variable is defined for a workflow, you can use it in batch mode by referring to it using a comma separated triplet to specify the name, value and type like this:
-workflow.variable=my_integer,5,int
The workspace is empty how do I create a new project?
In the Navigator view (left top window) right-click and select "New", then "New KNIME Project". Provide a name for this new project and click the OK button.
The Node Repository shows only a few nodes (or none at all)
Check to see if you have something entered in the search field of the Node Repository view. Click into the edit field at the top of that view and delete any search term that might be present there. Also check for blank characters or spaces. This should return all nodes included in the installation. If this doesn't help, your installation might be damaged.
What kind of data is transmitted when I agree to send anonymous usage data?
Thank you for agreeing to help improve KNIME. The anonymous usage data will help our understanding of how the platform is actually used and aid future development. We want to make this process as transparent to you as possible with this list of items telling you what is sent to KNIME and what isn't. For this reason, when you start up KNIME you are asked if you would like to send these files. If you don't want to do this, you can deactivate it at any time.
What is being transmitted:
- Version of KNIME Analytics Platform used.
- An anonymized installation ID that allows us to ensure we don't double count statistics.
- How long KNIME Analytics Platform is running.
- How many times KNIME was launched.
- How many times KNIME exited successfully.
- How many workflows were opened locally and remotely.
- How often workflows were imported and exported successfully.
- Which nodes have been used and for each node
(this data is used for the Workflow Coach - the "what are good next nodes?" recommendation system):- How many times the node was created.
- How many times the node was executed.
- How much time was spent in execution.
- How often the node did fail.
- To most likely successor of this node
What is not being transmitted:
- Any settings or configuration of nodes.
- Any data used in workflows.
- Any other personal data.
I am running Fedora 10 using the Gnome window manager. The KNIME main application works as expected but as soon as I open a view or a dialog, this panel does not get repainted. Why?
That seems to be a java swing / swt problem. It seems as if the libgxim package causes this problem, i.e. if you uninstall that package (and all its dependencies) the panel will get properly painted.
How can I force KNIME to cache any intermediate data to disk in order to reduce memory usage?
The framework has no absolute control on memory usage of individual nodes, though it can control the amount of data in each node's output that is to be kept in main memory. This memory policy can be controlled in a node's dialog in the tab "General Node Settings". There are three different policies available: The first one ("Keep all in memory") enforces KNIME to leave all data that is generated by the respective node in main memory, the second option ("Write tables to disc") writes all data to disk immediately, the third one ("Keep only small tables in memory") is a heuristic to automatically switch between the first two items depending on the data size. Each of these options has pros and cons, e.g. keeping all data in memory allows for fast iterations on this data but increases memory usage.
The "Keep only small tables in memory" option is the default and of special interest. It uses a threshold value for the number of cells contained in a table (i.e. row count multiplied by column count) to decide whether to keep data in memory or on disk. This threshold defaults to 100 000 cells. If that is inappropriate in your setup (for instance because your cells tend to be large strings), you can change the default. This can be done using a java property that is passed either as command line argument or as part of the knime.ini file that is located in the installation directory. (Note: changing the configuration file is preferred over the additional command line argument since any command line argument instructs knime (more precisely the underlying eclipse) to ignore all entries in the configuration file).
Add the following line after the -vmargs line in the knime.ini file to keep at most 1000 cells in memory (you can choose a different value, even 0 in which case it always swaps to disk):
-Dorg.knime.container.cellsinmemory=1000
You can verify if this setting has been picked up by either looking at the log file or inspecting the tooltip that is shown when hovering over the "Keep only small tables in memory" option in any node.
I am getting an OutOfMemoryError when reading from a database using the Database Reader or Database Connection Reader node. What can I do?
For some databases KNIME fails to read huge amounts of data from them. Increasing the heap space inside the knime.ini (Xmx) sometimes solves the problem, but does not really solve the memory issues which is caused by a parameter called database "fetch size". Generally different databases use different fetch sizes, see for details. This parameter can be changed for KNIME by appending the following option to the knime.ini file:
-Dknime.database.fetchsize=1000
With this option, the database nodes only fetch the given number of rows into the database result set. We also recommend using the Database Connector together with the Database Row or Column Filter nodes or Database Query node to make the filtering inside the database and only read the desired data into KNIME at the end using the Database Connection Reader node.
I'd like to change KNIME's default configuration on the Mac but can't see the knime.ini. Where is it located?
The Mac version of KNIME has a different directory structure than the other versions. On the Mac the contents of an application are hidden from the user by default. To edit the knime.ini you have to navigate to your KNIME installation directory, right click on "knime.app" and choose "Show Package Contents". This will open another finder window where you will find the knime.ini under "Contents" -> "MacOS". By the way this is also the location where the knime executable is located if you want to launch KNIME from the terminal.
How do I connect to my Microsoft Access database?
Two setups without registering additional JDBC-driver are possible:
- Directly connect to the MS Access database using KNIME (enter the database URL as jdbc:odbc:DRIVER={Microsoft Access Driver (*.mdb, *.accdb)};DBQ=C:\\database.accdb)
- Register a database source in the system configuration. In the first case, one needs to within the Database Reader/Connector node dialog. The database needs to be registered with the system properties under adminstration (JDBC/ODBC sources). In KNIME, the identifier can diretly be used to connect to the specified database, for example jdbc:odbc:DATABASE_ID.
The main menu doesn't appear on Ubuntu with Unity desktop.
This is a bug in Ubuntu:
https://bugs.launchpad.net/ubuntu/+source/eclipse/+bug/1208019
To solve this the global menu has to be disabled by setting the environment variable UBUNTU_MENUPROXY=0 before launching KNIME.
Menu icons are not visible on Linux
This is a global setting of the desktop environment. The following steps re-enable the menu icons:
- Open dconf-editor
- Go to org.gnome.settings-daemon.plugins.xsettings
- Change overrides from {} to {'Gtk/ButtonImages': <1>, 'Gtk/MenuImages': <1>}
I cannot update/install additional extension or access the example workflow server because I am behind a firewall.
In both cases you need to configure a proxy in Eclipse. For updating or installing new extensions from an update site you need to configure an HTTP proxy, for accessing the example workflow server you must have a SOCKS proxy (ask your system administration for details on how to access the proxies). Both can be configured via File → Preferences → General → Network Connections. As Active Provider select Manual and then edit the entries for HTTP and/or SOCKS in the table below. You need to enter the proxy's name or IP address as well as the port number. If your proxy requires authentication also provide the login credentials.
In case you do not have a proxy, you can also download the complete update site as a ZIP file and use this as an archived update site. The example workflows can alternatively be downloaded as a single KNIME Archive (.knar) and subsequently be imported via File → Import KNIME workflow.
The new interactive R integration does not recognize JRI library: org.rosuda.REngine.REngineException: Cannot load JRI native library.
If you are using the new interactive R integration (released with KNIME 2.8), you must have the rJava library installed. This is, by default, already included with the Windows extensions. For all others (or if you want to use R3.0 or higher under Windows) you need to make sure you:
- Execute: 'install.packages("rJava")' in your R installation
- Point to the R home directory in KNIME under Preferences > KNIME > R (labs)
- Add a system property to your knime.ini:
-Djava.library.path=C:\...library\3.0\rJava\jri\x64
pointing to the jri.dll (make sure you point to x64 when using 64bit) - Remove the feature org.knime.features.rengine.r2.feature.group from the installation Help > About KNIME > Installation Details
- Restart KNIME.
Some R nodes run infinitely with R 3.1.0.
R 3.1.0 (only this version) has a bug concerning numerical precision handling. This causes some functions, e.g. rpart (for building decision trees), to run infinitely. You can cancel the node but the R process still keeps on running in the background. You have to kill the R process manually and use a different R version instead.
KNIME crashes after the splash screen on Linux with the error message a fatal error has been detected in libsoup-2.4.so in the hs_err_pid.log.
This may be related a to recent version of webkit that is not supported by Eclipse 3.7. This can be fixed by using the mozila web renderer instead.
Add the Java Option:
-Dorg.eclipse.swt.browser.DefaultType=mozilla
to your knime.ini file and try again. Note that the mozilla renderer needs Xulrunner to work.
I'm using the (C)Python extension and want to start python via a wrapper script as opposed to just "/usr/bin/python". How does such a script look like?
If you want to start Python via a script instead of using the executable directly the script has to meet the following requirements:
- It has to start Python with the arguments given to the script (please make sure that spaces are properly escaped)
- It has to output standard and error out of the started Python instance
- It must not output anything else.
Example script:
#!/bin/bash
# setup environment variables
/usr/bin/python "\$@" 1>&1 2>&2
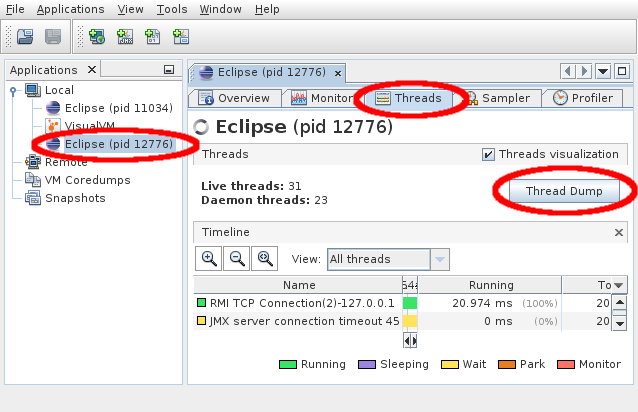
KNIME got stuck and doesn't respond any more
This misbehaviour unfortunately is hard to diagnose. If you report such a problem in the forum, please prepare a so-called thread dump which helps with debugging. You can create thread dumps with VisualVM. Download it from the linked page and follow the "First Steps" on the download page. After it has started you see a list of running Java application at the left top (see screenshot below). Select the KNIME process (it's usually called "Eclipse") and double click on it. After a few second a new tab at the right opens. Go to the "Threads" tab and click on "Thread dump". Copy the contents of the sub-tab that will open and send them to us.
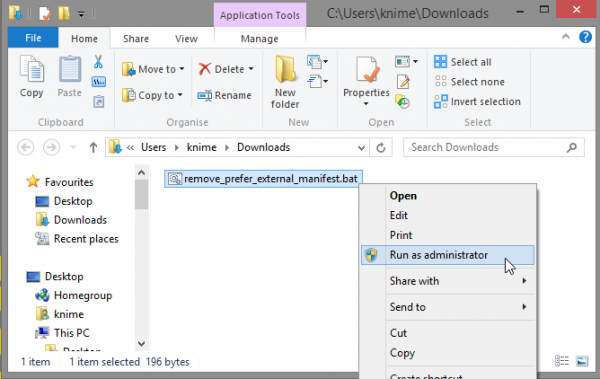
Microsoft Word does not work after installing KNIME 3.0.0
Some Windows users might have problems with Microsoft Word not functioning after installing KNIME 3.0.0. To fix the problem:
If you have 64-bit KNIME on 64-bit Windows or 32-bit KNIME on 32-bit Windows:
- Download and run this .bat file as administrator. If Microsoft SmartScreen filter shows a warning, click "More info" and then "Run anyway".
- Restart your computer.
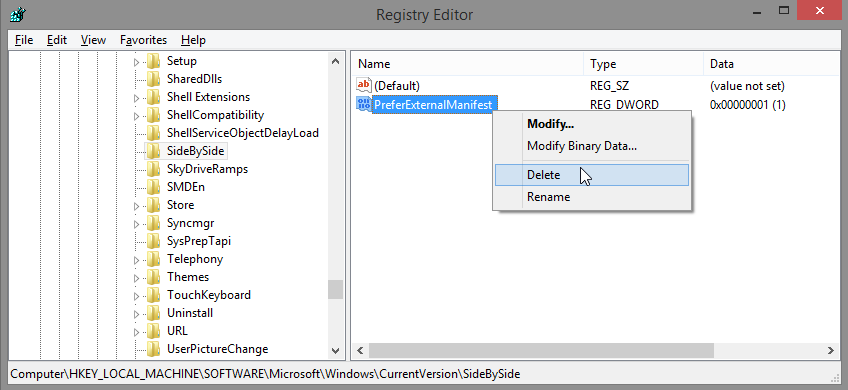
If you have 32-bit KNIME on 64-bit Windows:
- Execute this command: %systemroot%\syswow64\regedit.exe (see this link for more details).
- Go to the registry folder HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\SideBySide
- Delete the entry PreferExternalManifest
- Restart your computer.
Please contact us, if it does not help you. We are working on fixing the issue.
Problems connecting to public example server
If you cannot connect to KNIME's public example server, please check the following items:
- Make sure that your firewall (if you have any) allows connection to publicserver.knime.org. Until KNIME 2.12 the example server uses port 47037 since KNIME 3.0 port 80 is used.
- If your network forces you to use a proxy you can only use the example server with KNIME 3.0 and above. Configure the HTTP proxy in the preferences (File ⇒ Preferences ⇒ General ⇒ Network connections).
- If you are on Windows and get errors similar to "java.net.SocketException: Address family not supported by protocol family: connect" add the following line at the end of knime.ini located in the root of the installtion folder and restart: -Djava.net.preferIPv4Stack=true
Using recent Linux versions the KNIME main application is not responsive and shows screen artifacts
The problem is present on KNIME versions 3.x, which run on Linux systems that are coming with recent GTK versions (3.18 and above), for instance Ubuntu 16.04. The application starts normally but eventually reacts slow and sometimes also hangs. The behavior is caused by an issue in Eclipse 4.5, which is the framework underlying the KNIME Analytics Platform. (Newer versions of Eclipse don't have that problem but are not available as of the date of this FAQ).
You can run the KNIME application using older GTK 2 libraries by either exporting an environment variable before starting KNIME:
$ export SWT_GTK3=0 \$ /opt/knime/knime
Alternatively, you can add a parameter to the knime.ini file that is located in the KNIME installation folder, such as (new lines in bold):
... --launcher.library plugins/org.eclipse.equinox.launcher.gtk.linux.x86_64_1.1.300.v20150602-1417 --launcher.GTK_version 2 -vmargs ...
In some rare cases this may require additional compatibility libraries to be installed on your system ('libwebkitgtk-1.0-0').
Starting version KNIME 3.2 the application will also show a message dialog with each KNIME start in case this problem is detected. You can suppress this warning message by either following the steps above or by adding a new line to the bottom of the knime.ini, reading "-Dknime.linux.gtk3.check.disable=true" (without quotes).
"Open With" always uses the same KNIME installation although I specified a different location
Windows uses the name of the executable to determine which installation of the KNIME Analytics Platform is used to open a file (which in both cases is just 'knime.exe'). The first use of Open With works as expected on Windows. If you want to open a knwf file with, for instance an installation of the KNIME Analytics Platform extracted from a self-extracting archive, you have to rename the knime.exe in the extracted folder. For instance, rename knime.exe to knime-zip.exe and the knime.ini file to knime-zip.ini. Then use the normal Open With dialog to select this executable.
Shared installations of KNIME Analytics Platform
It is possible to setup a shared installation of KNIME Analytics Platform. The considerations for when this is appropriate are discussed in the following document from Eclipse.
The directory containing the KNIME Analytics Platform executable should not have write-access for all users except for the installation owner. The installation owner should not run the KNIME Analytics Platform at the same time as other users. Consider installing the Analytics Platform using a service account.
KNIME Server users should not use a shared installation of KNIME Analytics Platform as the KNIME Server executor.
Issue displaying non-Latin (e.g. Korean) characters in Windows 10
In rare cases under Windows 10 some special characters appear as squares in the Table View. This is most likely caused by missing language packs in Windows. Installing these language packs fixes the display issue. To install the missing packages access "Region & language settings" from the Windows 10 control panel. There you can select "Add a language" to install the missing languages. After a restart of your computer the characters should appear correctly.
Sometimes it is necessary to also download additional resources. To do so you can select the language(s) you have installed from the "Region & language" window and download the additional resources.
I get an error message when I want to execute or open a view on nodes with a JavaScript view on Linux
Usually the error messages are related to Chromium not being able to start because of missing system libraries. To remedy the issue install the package that contains the missing library. E.g. “libXss.so.1 => not found” can be solved by running “yum install libXScrnSaver” (known Red Hat issue), or "apt install libgtk-3.0" (known Ubuntu issue).
Which version of Java does KNIME Analytics Platform rely on?
A Java Runtime Environment (JRE) is packaged with each installation of KNIME Analytics Platform - so there is no need for a separate Java installation. Starting with version 4.4 KNIME Analytics Platform now comes with a Java 11 runtime, which is a major new version. We distribute a Java JRE built and maintained by AdoptOpenJDK, which is an open-source implementation of the JRE.
Previously, version 3.7 and older versions of KNIME Analytics Platform were shipped with Oracle Java 8 JRE. However, we changed to AdoptOpenJDK, since Oracle, as the maintainer of Oracle Java 8, has announced changes to the distribution license for future versions of Oracle Java and discontinued public updates for Java 8.
Finally, KNIME Server customers also require a Java JDK, and the requirements and support information are covered in the KNIME Server Installation Guide.
Backwards-compatibility issues with Extract Date&Time Fields (deprecated)
With KNIME v4.4 we moved from Java 8 to Java 11. Besides other changes, a major difference between the two Java versions is the provider changed from COMPAT (fka JRE) to CLDR. As the Extract Date&Time Fields node accesses the (default) localization provider to derive fields such as Day of year or Month (name) and COMPAT behaves differently than CLDR the nodes results MIGHT DIFFER.
Am I affected by these changes?
Yes, if the node is configured using a Locale that only specifies a language, but not a region, and does not have a Locale counterpart with region. However, note that even though the node has been configured using a Locale specifying language and region the result might still differ, e.g., because of bug fixes concerning wrong month names.
What does a Locale with and without region look like?
An example for a Locale without a region is de or en, while a Locale with a region looks like this de_DE or en_US. Generally speaking, a Locale exhibits a region if it contains an underscore.
Which Locales without region have a counterpart with region?
The following Locales is, el, ja, et, es, ms, ko, nl, sr, pl, ru, th, sr-Latn, fi, ca, hu, fr, da, en, sv, hr, de, ar, zh, id, no, tr and it seem to have a one to one correspondence to Locales with a region, i.e., if the node is configured using any of these Locales the month names as well days of year etc. will, to the best of our knowledge, still be correct / as if the node was executed using KNIME uk, he, sl, cs, sk, ro, hi, lt and pt. Note that the automatic mapping behavior can be disabled by unchecking the Map locales without region option or setting COMPAT the default LocaleProvider (see the “I'm affected, what to do?” entry for information on how to do this).
I'm affected, what to do?
To ensure that the Extract Date&Time Fields node behaves exactly the same as with KNIME < v4.4 the following step is required. Open the knime.ini file and add the following line -Djava.locale.providers=COMPAT,CLDR,SPI right below -vmargs. This sets COMPAT as "default" provider and therefore ensures backward compatibility. However, as COMPAT is not being maintained, we discourage adopting this solution, especially as a long-term solution. We recommended instead to replace the deprecated node with its updated version and take action where required.
My KNIME Analytics Platform takes forever to start up. How can I make it faster?
When starting KNIME Analytics Platform, antivirus programs such as Windows Defender scan all installed plugins for potential threats. Since these plugins are compressed archives comprising many different files, scanning them takes a considerable amount of time. To speed up your startup of KNIME Analytics Platform, you can register KNIME Analytics Platform as a trusted application with your antivirus program at your own risk. To add an exception to Windows Defender on Windows 10 you’ll have to:
- enter "Virus & threat protection" in your Windows search,
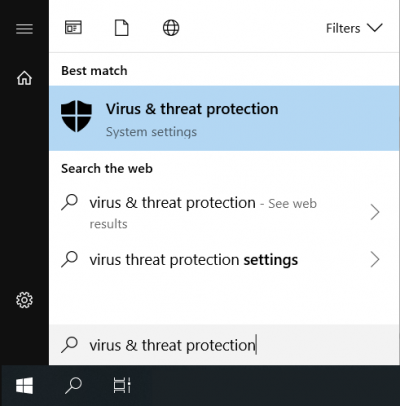
- navigate to "Virus & threat protection settings",
- navigate to "Add or remove exclusions",
- click “Add an exclusion",
- select "Process" and enter "knime.exe" as process name
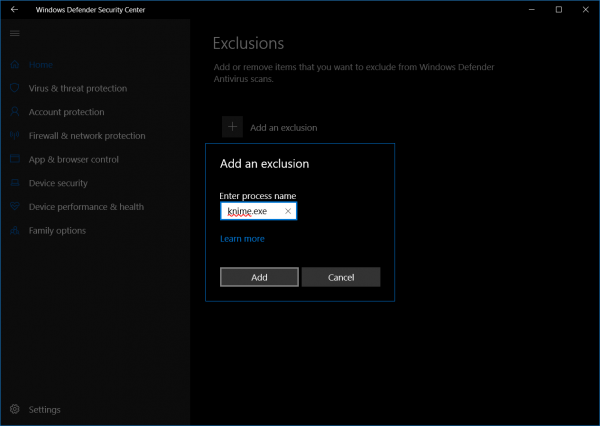
For installations with many plugins, adding an exception to your antivirus program can make the difference between five minutes and twenty seconds of waiting for KNIME Analytics Platform to start up.
Since updating to KNIME Analytics Platform 4.0, I am running out of system resources more frequently. What can I do?
KNIME Analytics Platform 4.0 uses system resources in the form of memory, CPU cores, and disk space more liberally and sensibly than earlier versions (for details, see What's New in KNIME Analytics Platform 4.0). Should you run into any problems that appear related to these changes, consider providing KNIME with additional heap space. Alternatively, you can individually revert the changes via the knime.ini.
- To revert to a less memory-consuming table caching strategy, put the lines -Dknime.table.cache=SMALL and
-Dorg.knime.container.cellsinmemory=100000 into your knime.ini. - To revert to an older garbage collector, remove the line -XX:+UseG1GC from the knime.ini.
- To prevent KNIME from using multithreading for domain updates and data validation, put the line
-Dknime.synchronous.io=true into your knime.ini. - To revert to the old compression format for writing tables to disk, put the line -Dknime.compress.io=GZIP into your knime.ini.
Note that all of these reverts come with a high cost in terms of performance. For more information on how to set up the knime.ini, refer to the documentation.
Legacy Swing‑based dialogs don’t work on Linux when using Wayland and Equo Chromium v128
Because KNIME uses AWT/Swing for some legacy node dialogs, these dialogs are not supported by the Wayland compositor—even though CEF v128 provides reliable Wayland support on its own. This limitation stems from the underlying SWT/Eclipse rendering stack not supporting AWT/Swing under Wayland (otherwise these popup dialogs appear blank or don’t render at all).
Workaround: Force X11 backend before launching KNIME
To restore functionality on Linux systems using Wayland, launch KNIME with the GDK_BACKEND=x11 environment variable:
GDK_BACKEND=x11 ./knime
This forces GTK (and thus embedded CEF and Swing dialogs) to run over X11, bypassing Wayland compatibility issues.
Starting with KNIME Analytics Platform 5.1 HTTP connections (e.g. via "GET Request" node) no longer work with authentication behind a proxy. Is there a workaround?
This change is due to security considerations made by Java, documented in their Release Notes. In order to enable authentication behind proxies a system property needs to be set by adding this line to the end of the knime.ini:
-Djdk.http.auth.tunneling.disabledSchemes=""
KNIME crashes or shows UI issues on Linux with errors mentioning "libswt-pi3-gtk" and "libgdk-3"
KNIME uses the SWT toolkit (from Eclipse) to display its user interface. The issue is caused by SWT assuming that the ibus input method framework is available on all Linux systems. If ibus is not installed, the KNIME Analytics Platform may crash or show UI issues. This problem has been reported upstream in the Eclipse bug tracker.
A workaround is to install the following package on your system:
ibus
To do so you can use the following command (on Ubuntu/Debian-based distros):
sudo apt install ibus