Here are some of the changes, new tools and integrations, and new views in both the open source KNIME Analytics Platform and commerical KNIME Server.
You can download KNIME Analytics Platform 4.0 here.
KNIME Hub
KNIME Analytics Platform
- Components
- Performance
- KNIME Database Extension
- Machine Learning
- AWS ML Services Integration
- Plotly Integration
- Duplicate Row Filter (per community request!)
- Simplified Kerberos Support
Big Data
KNIME Server
- Remote Workflow Editor
- Scheduling Improvements
- Workflow Pinning (Distributed Executors)
- Properties Editor
- Create User Directories on First Login
- Permissions for Individual Users
KNIME for AWS and Azure
General Release Notes
- Changes to Java Runtime and KNIME Analytics Platform Upgrade Procedure
- Community Extensions
- API Changes
See the full list of changes in the changelog.
KNIME Hub
You’ve probably seen the new KNIME Hub by now - the place for finding KNIME workflows, nodes, and components, as well as solutions to your data science challenges. With KNIME Analytics Platform 4.0, we’ve released a bunch of exciting new features!
- Share workflows and components publicly with the entire KNIME community yourself. Simply create an account or use your existing KNIME account and log in to the newly added My-KNIME-Hub Mountpoint from KNIME Analytics Platform 4.0.
- Browse KNIME extensions on the KNIME Hub and quickly learn about all nodes of an extension and explore related workflows to find examples on how to use this extension.
- Drag and drop nodes or install extensions from the KNIME Hub into your running KNIME Analytics Platform workbench. Nodes will show up in your workflow and missing extensions will automatically be discovered and installed.
- Search the KNIME Hub from within KNIME Analytics Platform. Simply type in any search query and hit enter. This opens a browser window and displays results in the KNIME Hub.
Learn more about the new features of KNIME Hub here.
KNIME Analytics Platform
Components
In this release, components replace and enhance wrapped metanodes as building blocks containing sub-workflows. Components encapsulate and abstract functionality and are really KNIME nodes that you create with a KNIME workflow. They can have their own dialog and their own sophisticated, interactive views. Components can be reused in your own workflows, shared with others via KNIME Server or the KNIME Hub, or represent web pages in an Analytical Application. This blog post provides more detail, and you can check out the EXAMPLES Mountpoint in KNIME Analytics Platform for a first set of components for you to use in your own workflows.
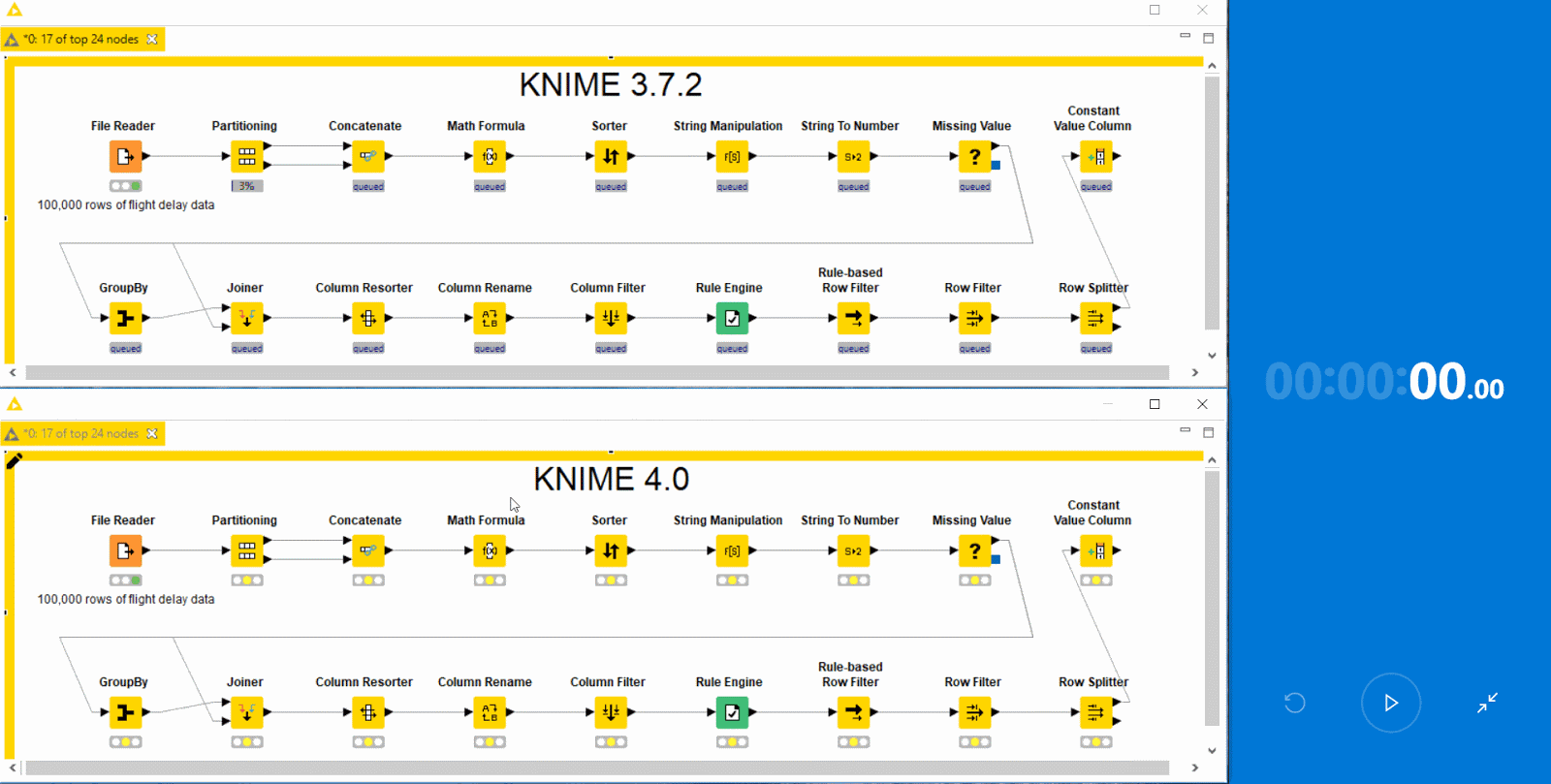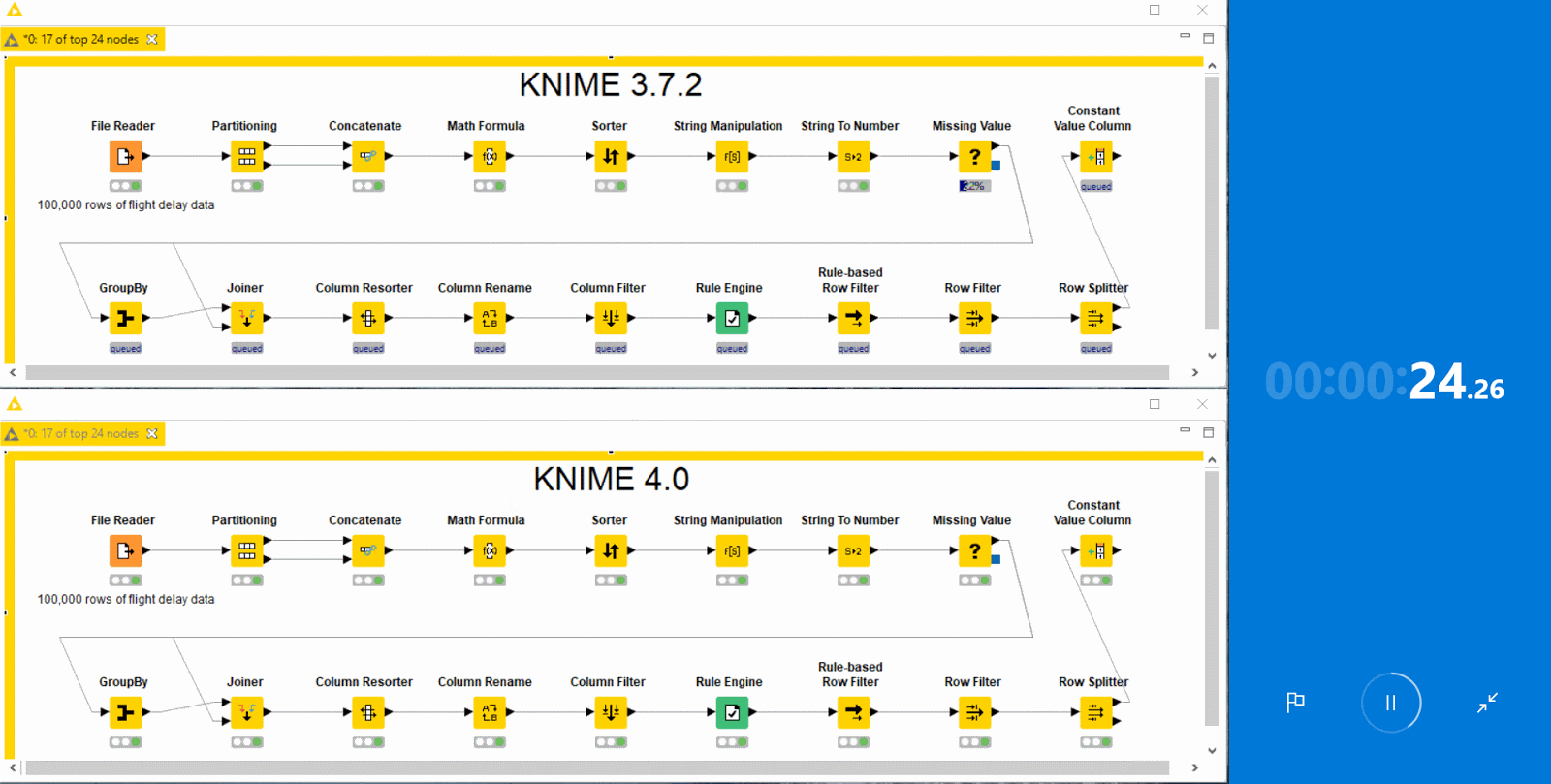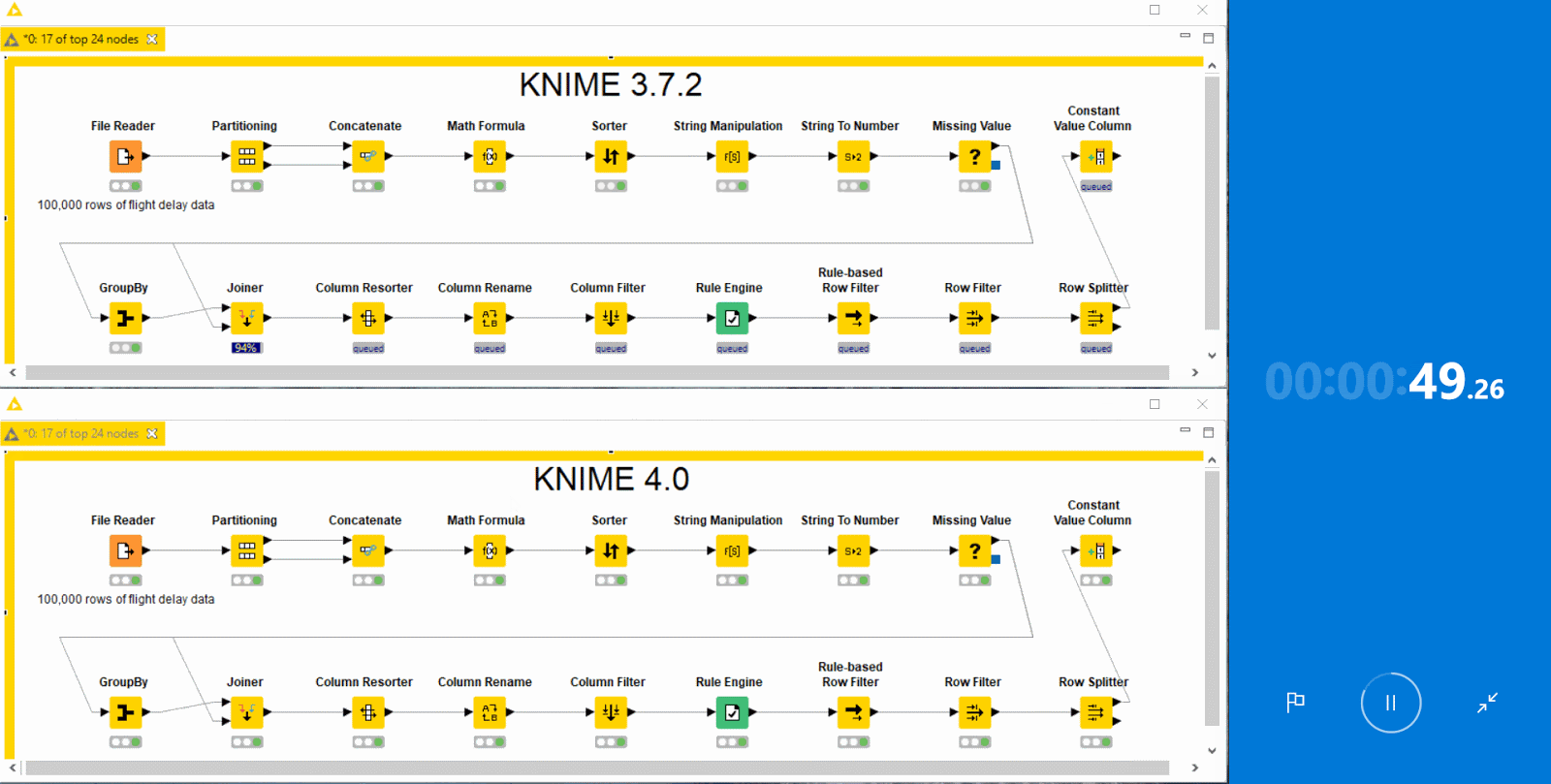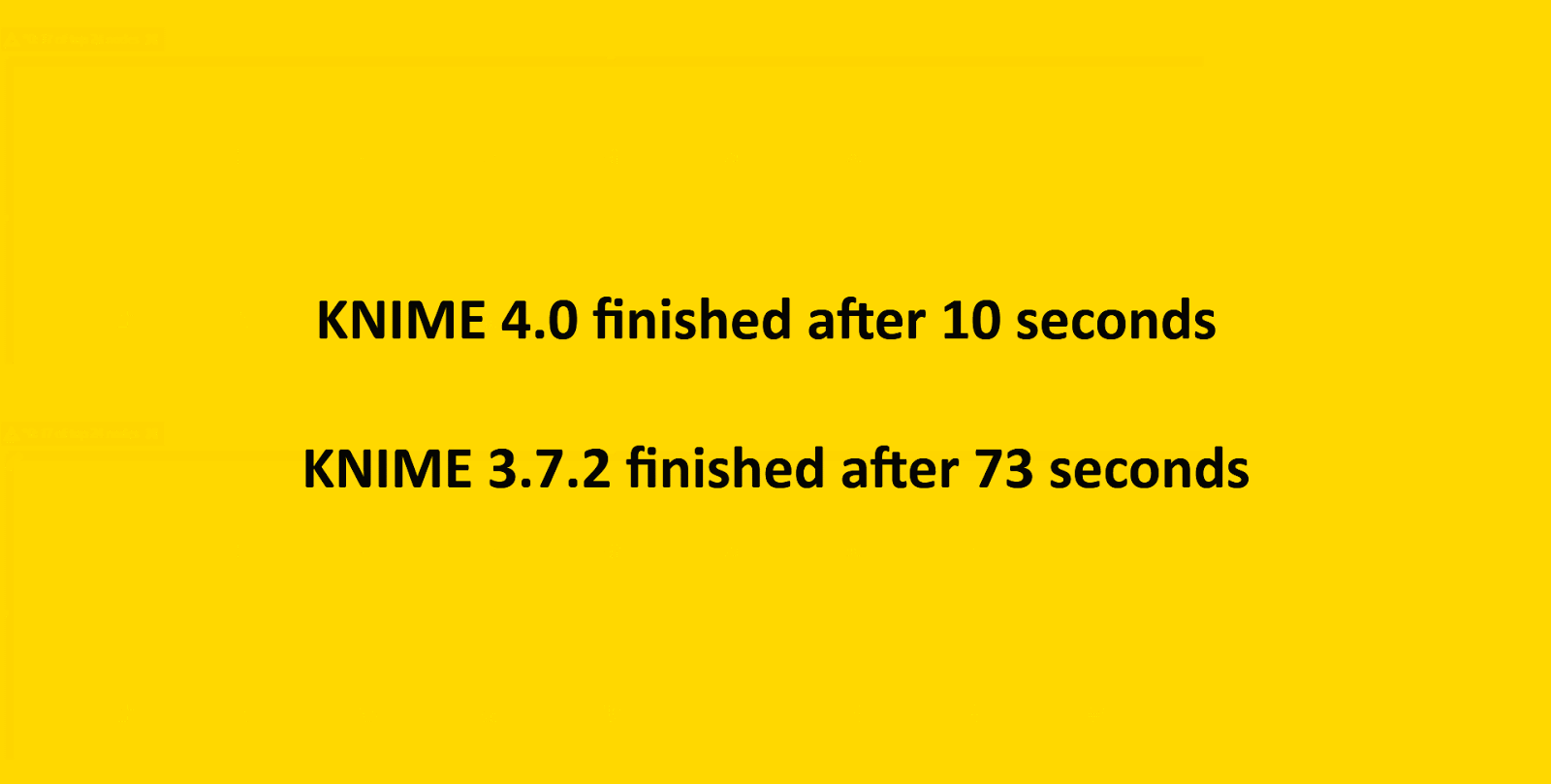
Performance
Performance has been a major focus of this release. KNIME Analytics Platform 4.0 and KNIME Server 4.9 use system resources in the form of memory, CPU cores, and disk space much more liberally and sensibly. Specifically, they:
- attempt to hold recently used tables in-memory when possible
- use advanced file compression algorithms for cases when tables can’t be held in-memory
- parallelize most of a node’s data handling workload
- use an updated garbage collection algorithm that operates concurrently and leads to fewer freezes
- utilize an updated version of the Parquet columnar table store that leverages nodes accessing only individual columns or rows
As a result, you should notice considerable speedups of factors two to ten in your day-to-day workflow execution when working with native KNIME nodes. To make the most of these performance gains, we recommend you provide KNIME with sufficient memory via your knime.ini file. See the FAQ for details on how to do this.
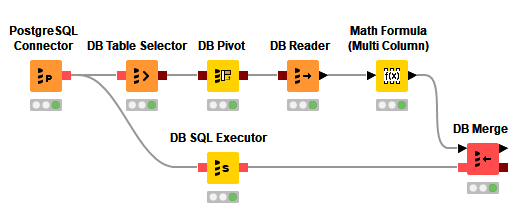
KNIME Database Extension
The new database extension has graduated from the KNIME Labs and is ready for use in production. We've tried hard to incorporate a lot of your feedback (thanks!), so if you liked the existing framework, then you will love the new one. Visually interacting with your favorite database from within KNIME Analytics Platform is now easier than ever. Some highlights include:
- Flexible type mapping framework
- Improved database schema handling
- Flexible driver management
- Improved connection management
- Streaming support of all reader and writer nodes
- Advanced SQL editor with syntax highlighting code completion and query preview
Machine Learning
We’ve added lots of neat features around new machine learning functionality for model interpretation, automation, and a number of new algorithms.
Machine Learning Interpretability
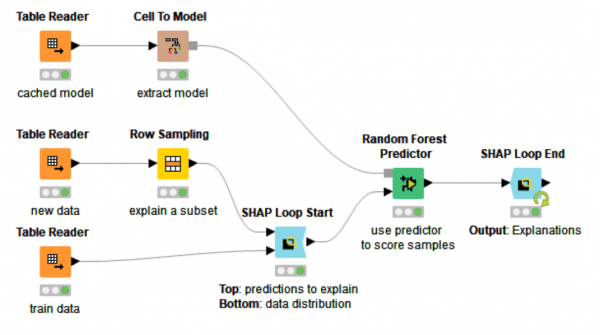
The new LIME, SHAP, and Shapley Values nodes give you explanations for how your model behaves on a per row basis and helps you better understand how your model predicts individual rows. Whether you use them for debugging or trust building, these techniques can help you to get a grasp on otherwise complex models.
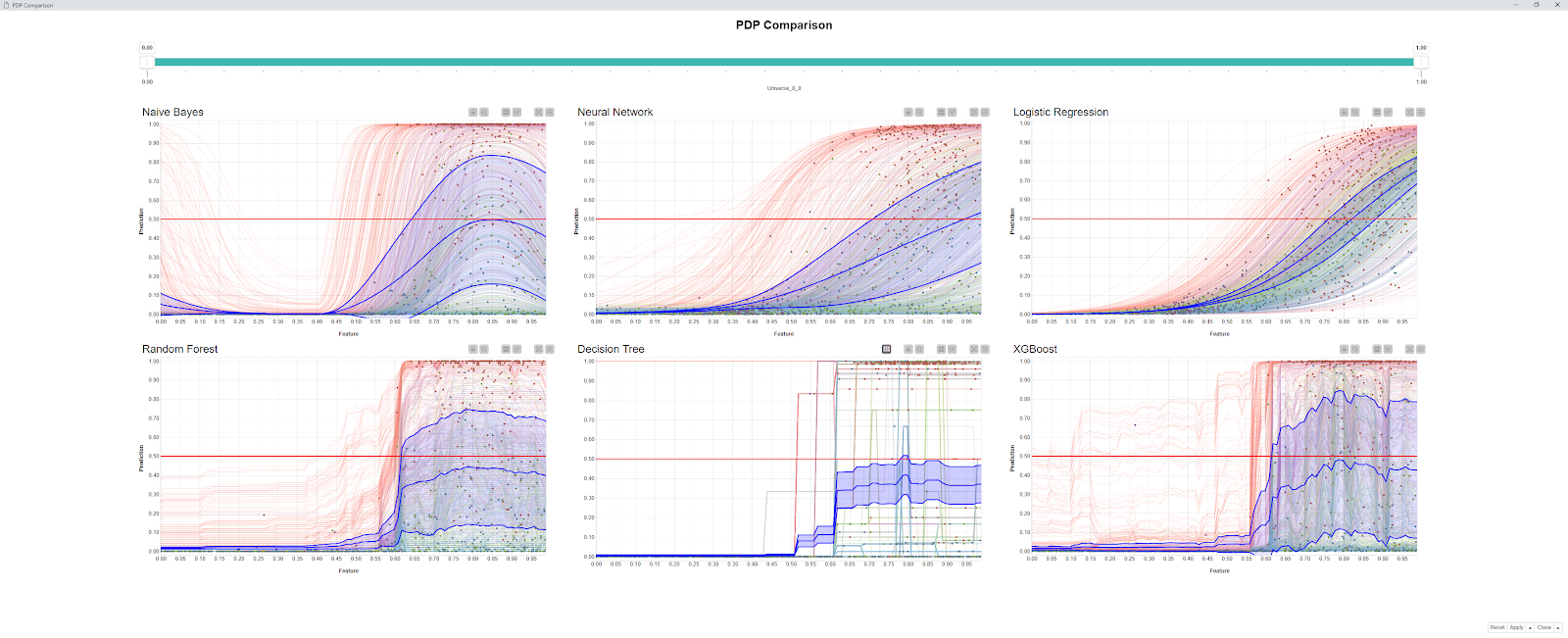
The new Partial Dependence/ICE Plot (JavaScript) node can create an interactive view with which you can inspect how the model prediction reacts to a variation of a single column. This can help you see how a single column is affecting the predictions of your models.
Machine Learning Algorithms
You can now use the H2O Isolation Forest Learner and H2O Isolation Forest Predictor nodes to train and test a tree-based model designed for outlier detection. t-SNE, a popular dimensionality reduction technique has been added in this release and allows you to easily visualize meaningful clusters in high dimensional data. Lastly, it’s now possible to read deep learning models stored in the ONNX format into KNIME Analytics Platform and convert them to TensorFlow models for prediction with the KNIME TensorFlow Integration.
Machine Learning Automation
We have added random search as well as genetic algorithms as additional strategies to the feature selection nodes. This will make it easier to pick the right set of features for your model - especially in settings with hundreds of features. We have also extended our Parameter Optimization loop with a Bayesian Optimization strategy that uses Tree-structured Parzen Estimators to learn which configurations are likely to improve your model’s performance and accuracy of machine learning algorithms.
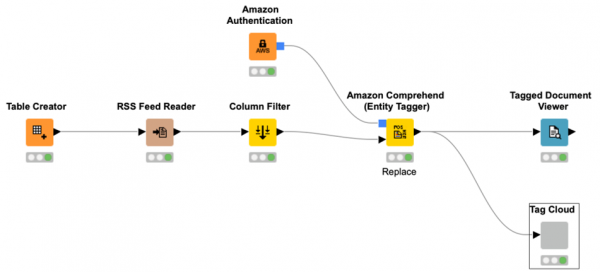
AWS ML Services Integration
This release also features an integration with Amazon Web Services (AWS), specifically Amazon Comprehend and Amazon Translate. The new nodes are part of the KNIME Textprocessing Extension. The Comprehend Entity Recognition and Syntax Analysis functions are implemented as text taggers. The nodes support input columns of either the Document type or String type for analysis. Note this is a paid service and will therefore require Amazon services credentials.
Plotly Integration
This integration pairs KNIME interactivity with the popular Plotly visualization library to bring several new visualizations to KNIME Analytics Platform. All nodes in this integration can interact with the existing views within KNIME and bring along many new features such as 3D charts and time series compatibility. Additionally, the Plotly.js library is now available as a default import in the “Generic JavaScript View” so you can build upon your existing Plotly code within KNIME.
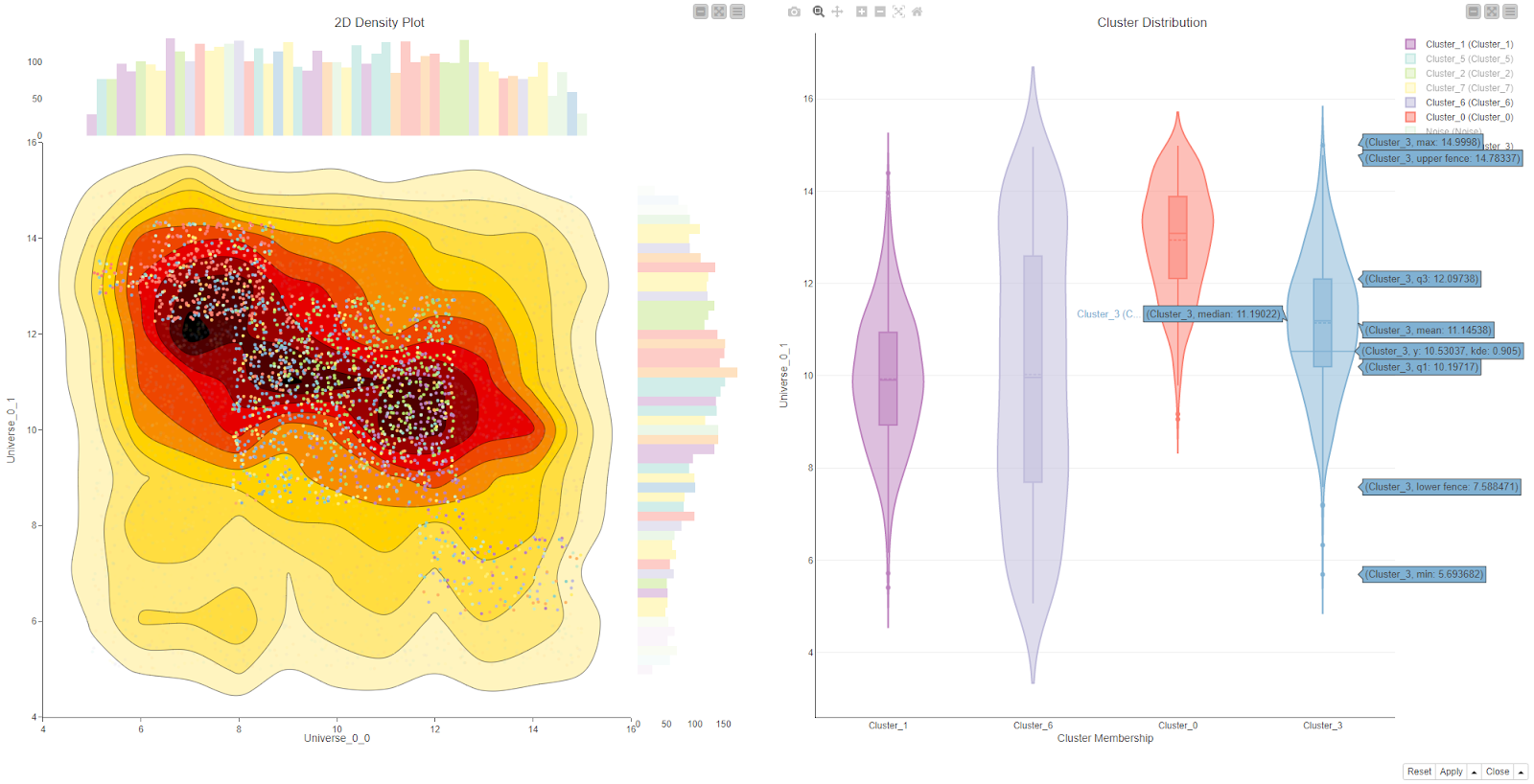
Duplicate Row Filter (per community request!)
Earlier this year, as a “thank you” for taking part in a survey, we asked the community to suggest a node that they would love to see made. We promised that we’d pick one and add it to the upcoming release. A feature that many of you requested, was a convenient way to clean data from duplicates so we added the Duplicate Row Filter node! You simply select the columns identifying the duplicates and the node also supports various tie-breaking strategies and ways to just mark up the original table instead of outright filtering.
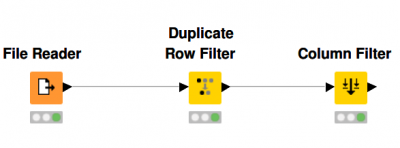
Simplified Kerberos Support
Enterprise setups of KNIME Analytics Platform, where nodes need to be authenticated against Kerberos or Active Directory, are now easier with the new Kerberos preference page and login controls in the main window of KNIME Analytics Platform. There’s no longer the need to install a separate Kerberos client software because you can perform the Kerberos login directly inside KNIME Analytics Platform.
Big Data
Spark Repartition
With the new Spark Repartition node, you can change the number of partitions of a Spark DataFrame, which is useful for tuning the performance of Spark workflows. Each Spark data output port now displays the number of partitions of the respective DataFrame.

Revised Spark Model Learner Nodes
This release brings the first batch of revised Spark model learner nodes that leverage Spark pipelines and the current spark.ml algorithms. The Spark Decision Tree, Random Forest, and Gradient Boosted Tree Learner nodes have been rewritten and there are now separate learner and predictor nodes for classification and regression. All new nodes automatically handle categorical columns and the new Spark Predictor (Classification) node provides conditional class probabilities whenever the model allows it.

Migration to the new KNIME Database Extension
All database-related nodes from the KNIME Big Data Integration have been migrated to the new database framework - including Create Local Big Data Environment, Spark to Hive, Hive to Spark, and several others.
KNIME Server
Remote Workflow Editor
The Remote Workflow Editor has moved out of preview, meaning it has all the functionality required to make editing workflows directly on KNIME Server work smoothly. Editing a workflow directly on KNIME Server has several advantages. You don’t need to download and upload a workflow when you make a small change, you can directly inspect a running workflow to view progress and debug, and you can control a workflow that connects to secured resources like big data clusters directly via KNIME Server. Two key improvements for this release are being able to directly browse the KNIME Server repository from File Reader/Writer nodes and views on database output ports. We didn’t implement 100% of the functionality that KNIME Analytics Platform allows when editing workflows locally, so if you are missing that tiny bit of functionality we’d love for you to get in touch and let us know!
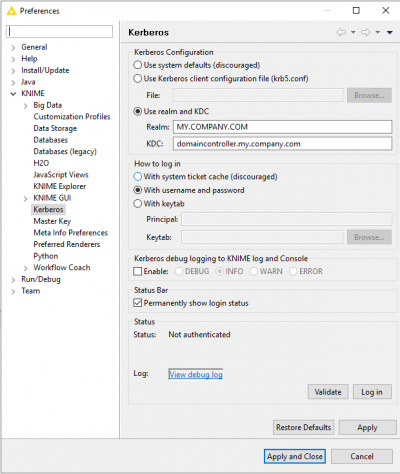
Scheduling Improvements
It’s now possible to send notification emails - including with attached reports if needed - when a workflow executes successfully. This is useful if there is a problem because the appropriate people can be notified of an issue that needs fixing. In addition, it’s now possible to use report actions to save reports to a specific location on KNIME Server. You can now also organize workflows to run on a schedule within a certain timeframe (e.g. outside of office hours). We have also made some adjustments to better support working with daylight savings time changes.
Workflow Pinning (Distributed Executors)
One of the major advantages of using the distributed executors functionality of KNIME Server Large, is that you can set up a heterogeneous set of executors which are specialized for certain purposes, e.g. an executor with access to a GPU for faster training of deep learning models, large memory executors for large datasets, executors with licenses for third party software, different Python and R environments, and more. By defining resources when launching the executors, it’s possible to choose which executor type a specific workflow should be executed on.
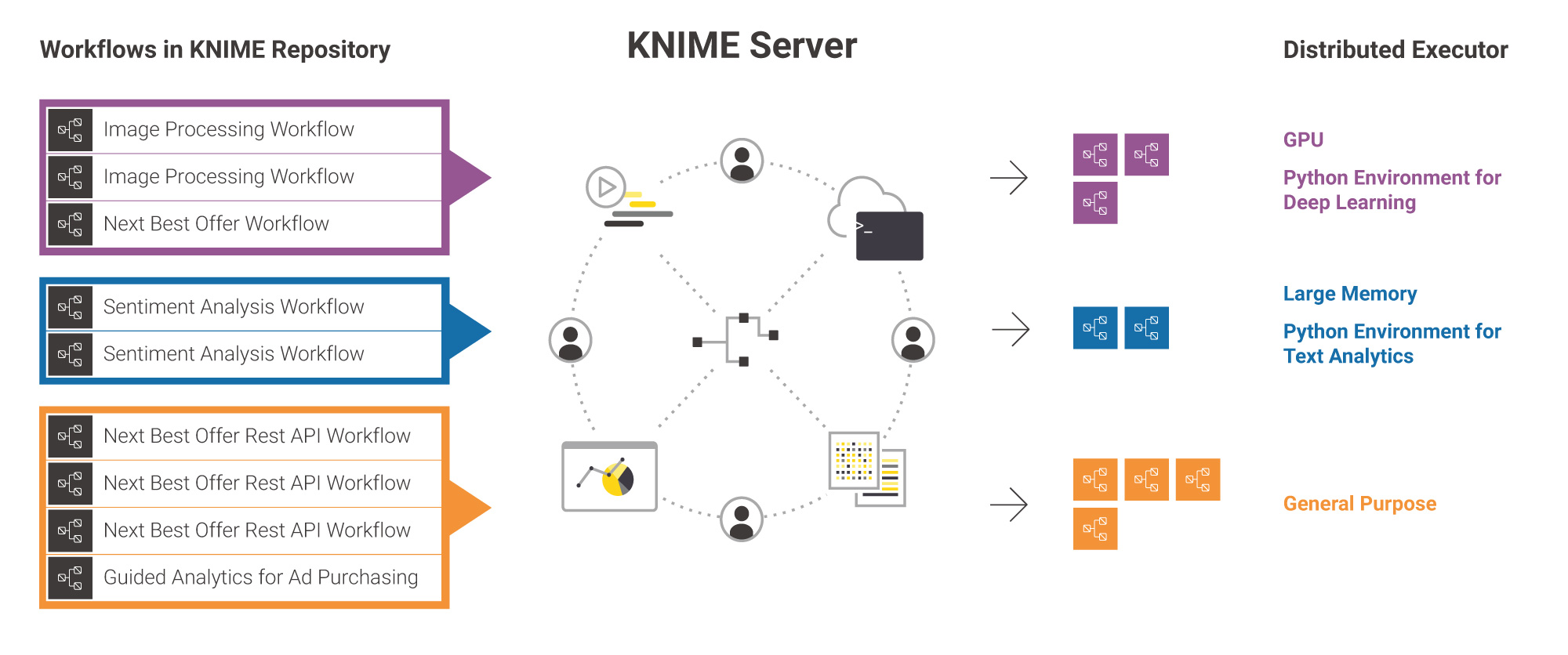
Properties Editor
The properties editor provides a convenient way to set properties on workflows. Properties can be used to control the behavior of workflows on KNIME Server. It’s currently possible to set the size of a job pool that can be used when running a workflow via REST API - for example as a high performance scoring endpoint. It’s also possible to set executor requirements for distributed executors.
Create User Directories on First Login
It’s now possible to automatically create new user directories when a user first logs in to KNIME Server. Default permissions can be applied to the directories, making it easy to encourage best practices for storing workflows in individual workspaces before sharing finished workflows in communal spaces for reuse.
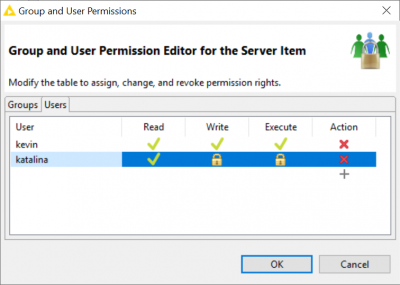
Permissions for Individual Users
There is a benefit to centrally managing group membership of users via Active Directory but sometimes it’s more convenient to be able to apply permissions to individual users. This is now possible via a new tab in the permissions dialog.
KNIME for AWS and Azure
KNIME Server Large for AWS
With this release comes KNIME Server Large for AWS. One of the advantages of KNIME Server Large is the distributed executors functionality. When deployed on AWS as a solution template from the AWS Marketplace, KNIME Server Large enables running auto-scaling groups with executors that can scale up and down as the workflow execution demand changes. This results in a smooth end user experience, while keeping hardware and software costs in check.
KNIME Server Small for Azure
KNIME Server Small is now available on the Microsoft Azure Marketplace - and there is a one month free trial to test the features and performance. It joins the already available KNIME Server Medium and KNIME Server (BYOL) offerings, as well as KNIME Analytics Platform. All offerings have been customized to give the best performance on Azure. Full documentation for running KNIME Server on Azure is available on our website, on the Azure Marketplace, or in the KNIME documentation.
General Release Notes
Changes to Java Runtime and KNIME Analytics Platform Upgrade Procedure
KNIME Analytics Platform 4.0 is distributed with AdoptOpenJDK, which is an open source version of the Java Runtime Environment. Previous releases were based on Oracle Java. For details on what version of Java is used, see this FAQ.
Community Extensions
The community contributions underwent some changes that may affect you. Specifically, some contributions moved between update sites, we created some new categories, and all contributions needed changes that mean that older versions (e.g. those compatible with KNIME Analytics Platform 3.7) will not work with KNIME Analytics Platform 4.0. In short the changes mean that contributions in the Community Extensions (Trusted) and Community Extensions (Experimental) (previously named Stable Community Contributions) use the same copy of one of the four following license files:
- GPLv2 (http://www.gnu.org/licenses/
gpl-2.0.html ) - GPLv3 (http://www.gnu.org/licenses/
gpl-3.0.html ) - BSD (https://opensource.org/
licenses/BSD-3-Clause ) - Apache Ver 2.0 (http://www.apache.org/
licenses/LICENSE-2.0.html )
Due to those changes, some contributions have moved between update sites. Also note that not all community contributions have been migrated to the new version. If you have community extensions installed currently, you should first check that they are available in KNIME Analytics Platform 4.0.
API Changes
Despite KNIME Analytics Platform being a major new version, we tried hard to keep the programming API stable. There have been a few changes that you should know about in case you have developed custom nodes:
- Dependencies to KNIME plugins need to be updated in your plugin's Manifest file. See here for an example.
- Classes and interfaces that changed and that are potentially relevant are:
- org.knime.core.data.DataCellFactory
- KNIMEResourceNavigator (removed)
- RSyntaxTextArea classes (moved to separate plugin)
We hope you like the new release features and provide us with lots of feedback!