As first published on ClearPeaks.
In this article we are presenting an enhancement that we recently implemented in KNIME – Per-User Distributed KNIME Executors – which you might find interesting if you are architecting KNIME deployments in an enterprise environment that has strong security requirements.
KNIME is an enterprise-grade software platform that we have already discussed in a previous article, Predicting Employee Attrition with Machine Learning. KNIME Software is comprised of two components: the open source KNIME Analytics Platform, a desktop application for creating and running data science workflows; the second component is the commercial KNIME Server used for productionizing data science.
There are a bunch of possible KNIME platform architectures; while this article does not intend to provide a KNIME reference architecture nor to cover in detail the use of each component (we may do that in a later blog post), what we will mention though is that common characteristics found in KNIME enterprise deployments include the use of Distributed KNIME Executors and User Authentication using an identity provider (LDAP).
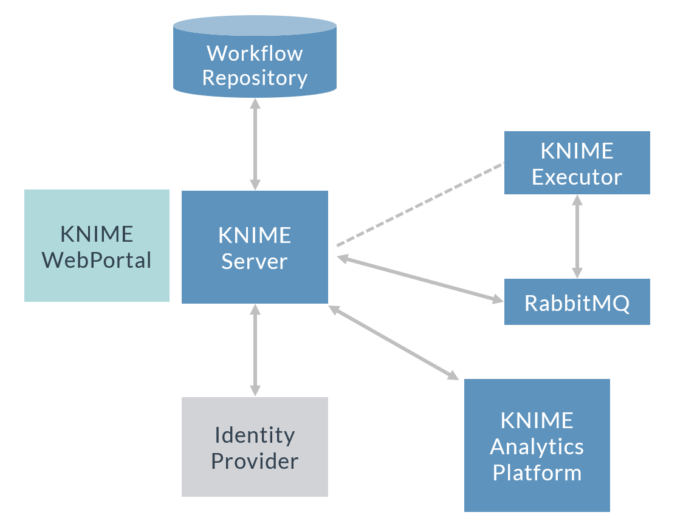
Figure 1: KNIME with Distributed Executor (only one in the image) and authentication by an identity provider (LDAP).
It is also quite common to add high availability to all the components by having multiple KNIME Servers (that need to share the workflow repository, so this has to be in a shared drive), multiple KNIME Executors and a RabbitMQ cluster with mirrored queues, all running in different machines.
When KNIME is running with Distributed Executors, i.e. KNIME Executors are running in hardware (physical or virtual) different from the KNIME Server, one would normally use a service account (for example a “knime” user) to run the Executor processes on the machines running KNIME Executors. This could be the same service account (“knime” user) as was used to do the KNIME Server installation, or it could be a dedicated service account used only to run the Executors (example “knimeexe” user).
1. Per-User Distributed KNIME Executors: Use case
Whilst using service accounts to run all the KNIME processes may suffice in many cases, there may be situations in which we need to run Per-User Distributed KNIME Executors. In this scenario, when a user submits a job, that job will be executed in a KNIME Executor that is running with the same OS user as the user that submitted the job, and not with a service account. Situations where this may be helpful are:
- You need to access data sources for which there are no KNIME nodes that enable access, but for which there is an OS method to do it. An example is to access network drives such as Samba or NFS with Kerberos. Currently KNIME does not have connectors for them, though it is possible to access Samba 1 without Kerberos using the nodes in the Erlwood extension; a way to provide access is to mount the network drives at OS level and then have the per-user Executor access them. In this way it is possible to use the user-based authorization rules that may have been set up for the network drives.
- You need direct auditing capabilities and need to know which user did what. When Executors all run with service accounts, in order to find out which user did what, you have to cross-match the job identifier on the KNIME Executor log (knime.log) with the information on the server logs. When KNIME Executors run for each user, each user has their own log file so there is no need to check the server logs to find out who did what.
- You need complete environment isolation for each user, the jobs running on the KNIME Executor machines for each user must be sealed and their intermediate data inaccessible by other users.
2. Per-User Distributed KNIME Executors: Our solution
We have developed a solution to achieve Per-User Distributed KNIME Executors. At the core of the solution is a Python script: when a user submits a job via KNIME Web Portal or via KNIME Analytics Platform (AP), the Python script running on the machine (virtual or physical) in which the KNIME Executors run will read the job (from RabbitMQ) and start a KNIME Executor process using the same OS user as the one who submitted the job.
Find the Python script and other auxiliary files in this Github repository. Check the README for the installation steps. Note that a plugin needs to be added to the KNIME Executor installation (in the dropins folder) to auto-terminate KNIME Executors that have been unused for a while. The auto-termination plugin is currently not included in the GitHub repository; to get it contact KNIME.
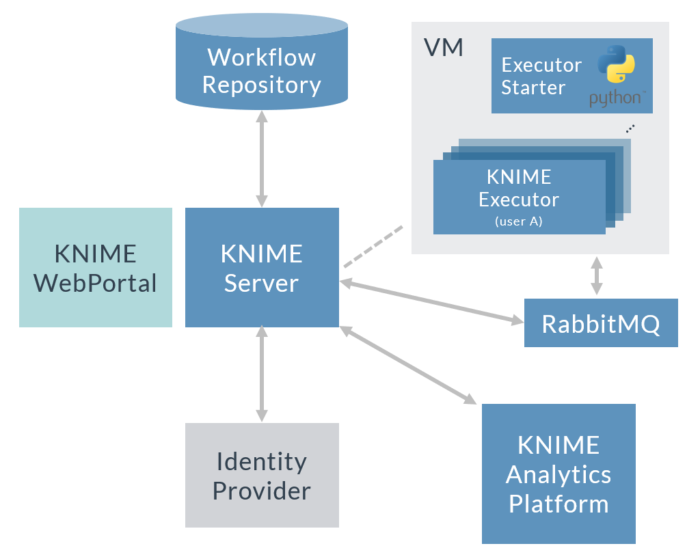
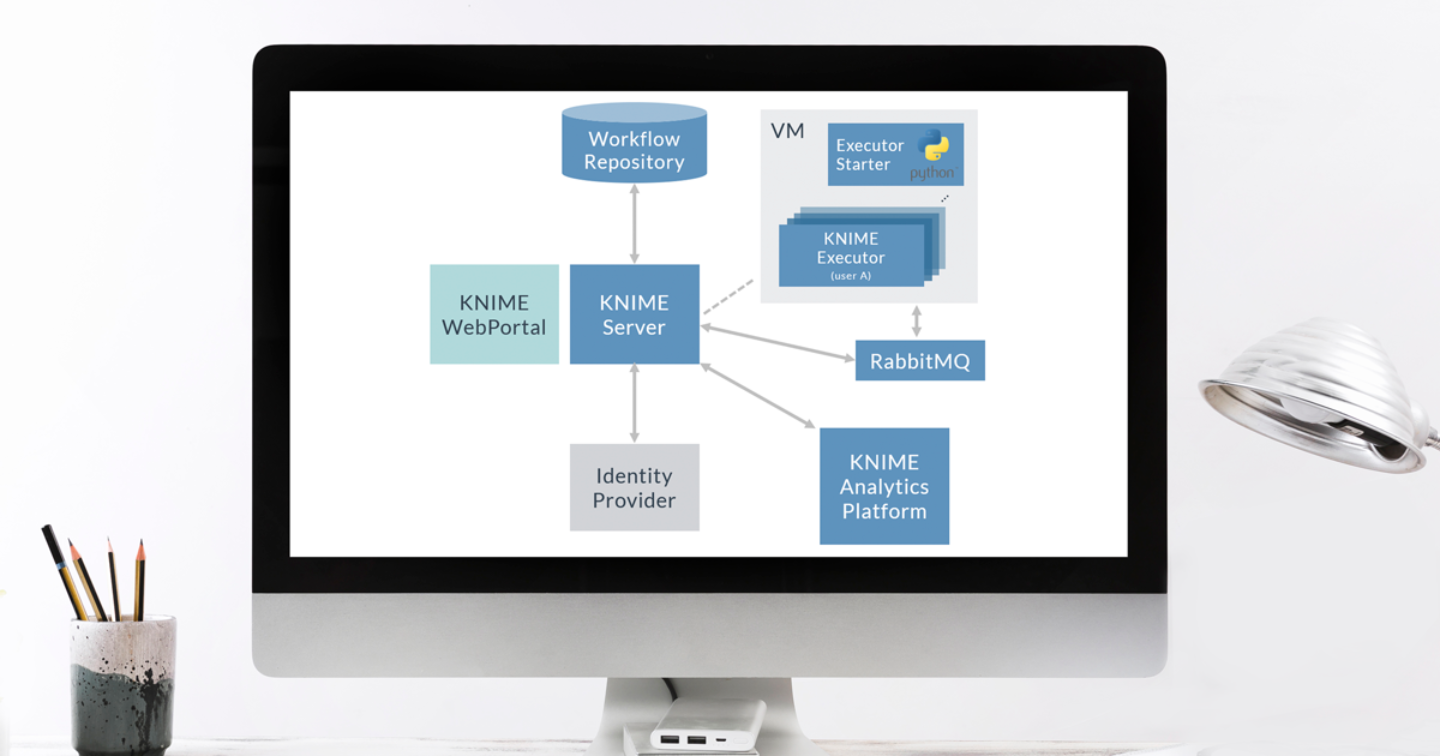
Figure 2 shows a KNIME architecture with Per-User Distributed Executors. Note that in highly available (HA) environments there will be more than one machine running KNIME Executors. In this case, each machine would run the Python script and spawn a KNIME Executor for the user, providing HA at KNIME Executor level, as each user would always have more than one KNIME Executor ready to get their jobs.
The requirements to use our solution are:
- A KNIME enterprise deployment (with RabbitMQ and Distributed KNIME Executors). Our solution has been tested with KNIME Executors version 4.2.2 and KNIME Server 4.11.
- KNIME Server users must be synchronized with LDAP, and OS users in the Executor machines are also synchronized with the same LDAP – this can be achieved using SSSD, for example.
- Root privileges on the KNIME Executor machines. Note that because the Python script needs to start processes under different OS users this solution needs root. Also note that a user who submits a job may never have logged in to the KNIME Executor machines. A KNIME Executor process will write some Java and Eclipse preference files in the home folder of the user running the process. When the user has not logged in to the machine (which is actually what we want since we do not want users able to log in to these machines), the home folder needs to be created prior to running the KNIME Executor with that user, otherwise the KNIME process will fail – this is taken care of by the Python script.
- A file system that supports ACLs in the KNIME Executor machines. Each user will have its own workspace and temporal directory; and these will be isolated so that no other user can access them. This is achieved by using ACLs (this is managed by the Python script)
- A ready-to-use Python 3 environment with pika and psutil on the Executor machines.
- Download the repository which includes knime_executor_per_user_starter.py, the Python script to start Per-User KNIME Executors on-demand; the configuration file for the Python script (knime_executor_per_user_starter.config); a bash script template to execute the Python script (knime_executor_per_user_starter.sh); and a file (knime-executor-per-user.service) to add the Python script as a service so it starts automatically on boot.
- A plugin (JAR file) to auto-terminate idle Executors. The file is called com.knime.enterprise.executor.autoshutdown_[version].jar. Contact KNIME to get this plugin.
- Proper licensing schema – note each KNIME Executor process will acquire core tokens from the KNIME Server, so you need to configure the Executors accordingly (via knime.ini) to avoid asking too many cores per process, depending on the number of users you have; otherwise, starting processes will fail since all tokens will be used. Similarly, you may want to limit the RAM (also via knime.ini) each KNIME Executor process will use. Taking into account the number of expected simultaneous users and their compute requirements, the Executor machines need to be properly dimensioned and the cores and RAM settings on knime.ini properly scaled.
Conclusion
At ClearPeaks we are experts on Big Data and Advanced Analytics technologies and we often need to create innovative solutions for our customers to meet their demanding requirements. On this occasion, we have been able to share one of these developments which we hope can help others in similar situations. If you require assistance with the solution described in this blog, with KNIME, or with other Big Data and Advanced Analytics technologies, do not hesitate to contact us. We are here to help you!