
We all know that just building a model is not the end of the line. However, deploying the model to put it into production is often also not the end of the story, although a complex one in itself (see our previous Blog Post on “The 7 Ways of Deployment”). Data scientists are increasingly often also tasked with the challenge to regularly monitor, fine tune, update, retrain, replace, and jump-start models - and sometimes even hundreds or thousands of models together.
In the following, we describe, in increasing complexity, different flavors of model management starting with the management of single models through to building an entire model factory.
Step 1. Models in Action: Deployment
We need to start with actually putting the model into production, e.g. how do we use the result of our training procedure to score new incoming data. We will not dive into this issue here, as it was covered in a separate blog post already. To briefly recap: we have many options such as scoring within the same system that was used for training, exporting models in standardized formats, such as PMML, or pushing models into other systems, such as scoring models converted to SQL within a database or compiling models for processing in an entirely different runtime environment. From the model management perspective, we just need to be able to support all required options.
It is important to point out that in reality very often the model alone is not very helpful unless at least part of the data processing (transformation/integration) is a part of the “model” in production. This is where many deployment options show surprising weaknesses in that they only support deployment of the predictive model alone.
To get a visual analogy started that we will use throughout this post, let us depict what this simple standard process looks like:

Step 2. Models under Observation: Monitoring
Next up is a topic that is critical for any type of model management: continuously making sure our model keeps performing as it should. We can do this on statically collected data from the past but that only allows us to ensure the model does not suddenly change. More often, we will monitor recently collected data, which allows us to measure whether the model is starting to become outdated because of reality changes (this is often referred to as the model drift, which is ironic since it is reality that drifts, not the model). Sometimes it is also advisable to include manually annotated data in this monitoring data set to test border cases or simply make sure the model is not making gross mistakes.
In the end, this model evaluation step results in a score for our model, measuring some form of accuracy. What we do with that score is another story: we can simply alert the user that something is off, of course. Real model management will automatically update the model, which we will discuss in the next section.
Step 3. Models Revisited: Updating and Retraining
Now it is getting more interesting and much more like actually managing something: how do we regularly perform model updates to ensure that we incorporate the new reality when our monitoring stage reports increasing errors? We have a few options here. We can trigger automatic model updating, retraining, or complete replacement. Usually we will allow for a certain tolerance before doing something, as illustrated below:
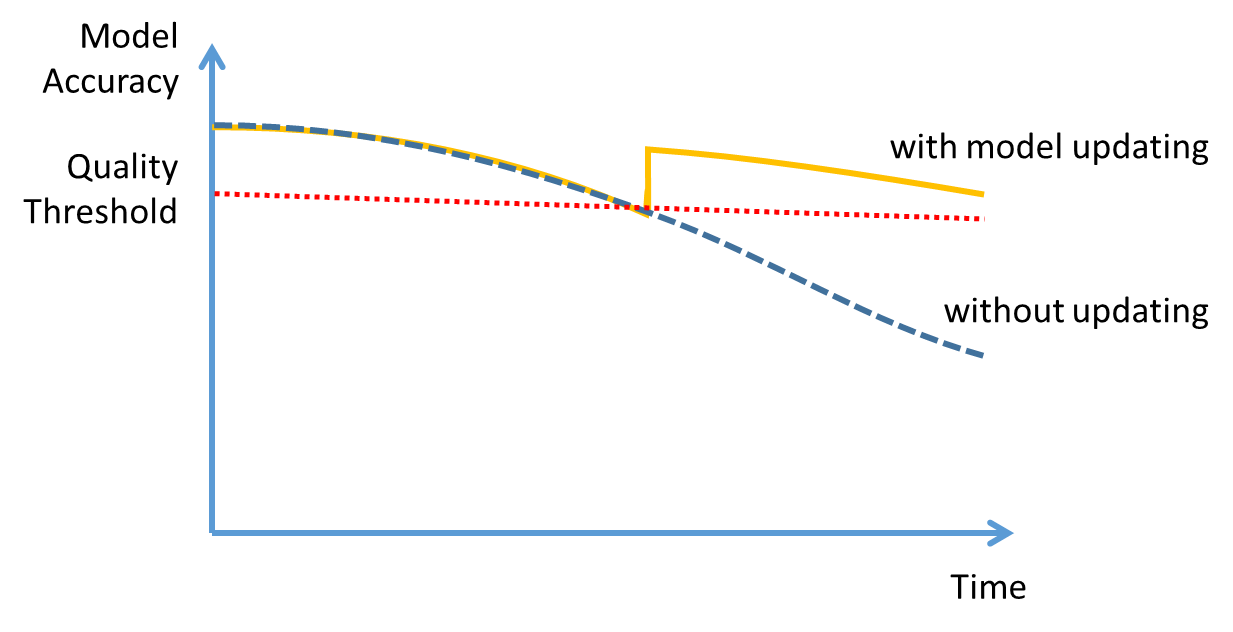
Some model management setups simply train a new model and then deploy it. However, since training can take significant resources and time, the more sensible approach is to make this switch dependent on performance and ensure that it is worth replacing the existing model. In that case an evaluation procedure will take the previous model (often called the champion) and the newly (re)trained model (the challenger), score them and decide whether the new model should be deployed or the old one be kept in place. In some cases, we may only want to go through the hassle of model deployment when the new model significantly outperforms the old one, too!
Note that all of the options described above will struggle with seasonality if we do not take precautions elsewhere in our management system. If we are predicting sales quotes of clothing, seasons will affect those predictions most dramatically. But if we then monitor and retrain on, say, a monthly basis we will, year after year, train our models to adjust to the current season. In a scenario such as this, the user could manually set up a mix of seasonal models that are weighted differently, depending on the season. We can attempt to automatically detect seasonality but usually these are known effects and therefore can be injected manually.
Another note on preexisting knowledge: sometimes models need to guarantee specific behavior for certain cases (border cases or just making sure that standard procedures are in place). Injecting expert knowledge into model learning is one aspect but in most cases, simply having a separate rule model in place that can override the output of the trained model is the more transparent solution.
Some models can be updated, e.g. we can feed in new data points and adjust the model to also incorporate them into the overall model structure. A word of warning, though: many of these algorithms tend to be forgetful, that is, data from a long time ago will play less and less of a role for the model parameters. This is sometimes desirable but even then, it is hard to properly adjust the rate of forgetting.
It is less complex to simply retrain a model, that is, build a new model from scratch. Then we can use an appropriate data sampling (and scoring) strategy to make sure the new model is trained on the right mix of past and more recent data.
To continue our little visualization exercise, let us summarize those steps of the model management process in a diagram as well:

Step 4. More Models: From a Bunch…
Now we are reaching the point where it gets interesting: we want to continuously monitor and update/retrain an entire set of models.
Obviously, we can simply handle this as the case before, just with more than one model. Note: now issues arise that are connected to interface and actual management. How do we communicate the status of many models to the user and let her interact with them (for instance forcing a retraining to take place even though the performance threshold was not passed) and also who controls the execution of all those processes?
Let us start with the latter – most tools allow their internals to be exposed as services, so we can envision a separate program making sure our individual model management process is being called properly. Here at KNIME we use a management workflow to do that work – it simply calls out to the individual process workflows and make sure they execute in order.
For the controller dashboard we can either build a separate application or again, use KNIME software. With KNIME’s WebPortal and the built-in reporting capabilities, we can not only orchestrate the modeling workflows but also supervise and summarize their outputs.
In most setups there will be some sort of configuration file to make sure some process workflows are called daily, others weekly and maybe even control from the outside what re-training and evaluation strategies are being used – but we are getting ahead of ourselves…
Step 5. …to Families
Handling bunches of models gets even more interesting when we can group them into different model families. We can then handle those models similarly that are predicting very similar behavior (say, they are all supposed to predict future prices for used cars). There is one issue, in particular, that is interesting to cover in this context: if models are fairly similar we can initialize the new model from the other models rather than starting from scratch or only training the new model on isolated past data. We can use either the most similar model (determined by some measure of similarity of the objects (used cars…) under observation or a mix of models for initialization.
Again, let us visualize this setup:
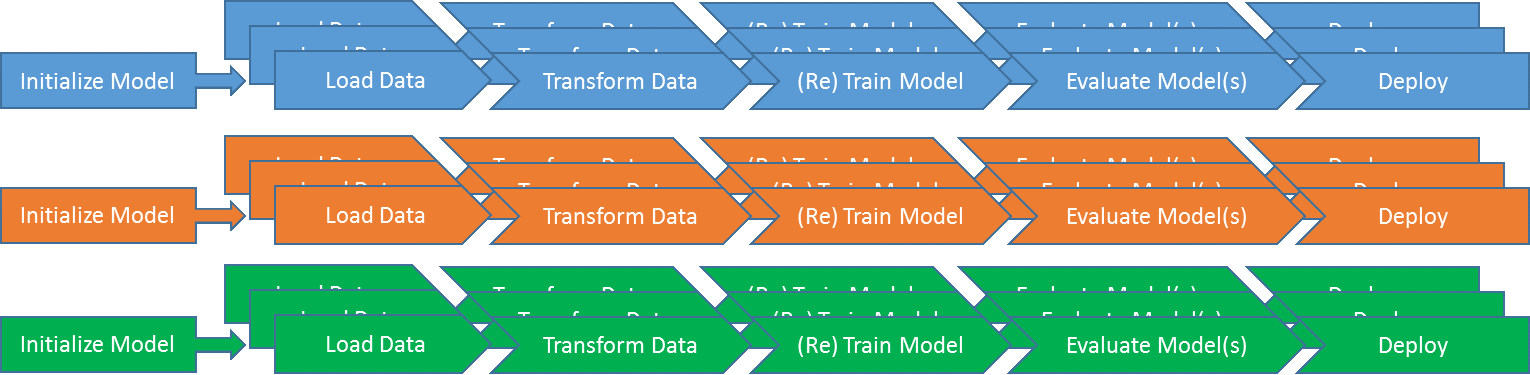
As you can see, we cluster our models into groups, or model families, and can use a shared initialization strategy for new models added to a specific family. In all probability, some of the overall management (frequency of running those model processes, for instance) can also be shared across families.
Step 6. Dynasties: Model Factories
Now we are only one step away from generalizing this setup to a generic Model Factory. If we look at the diagram above, we see that the steps are rather similar – if we abstract the interfaces between those sufficiently, we should be able to mix and match at will. This will allow new models that we add to reuse load, transformation, (re)training, evaluation, and deployment strategies and combine them in arbitrary ways. Therefore, for each model we simply need to define which specific process steps are used in each stage of this generic model management pipeline. The following diagram shows how this works:
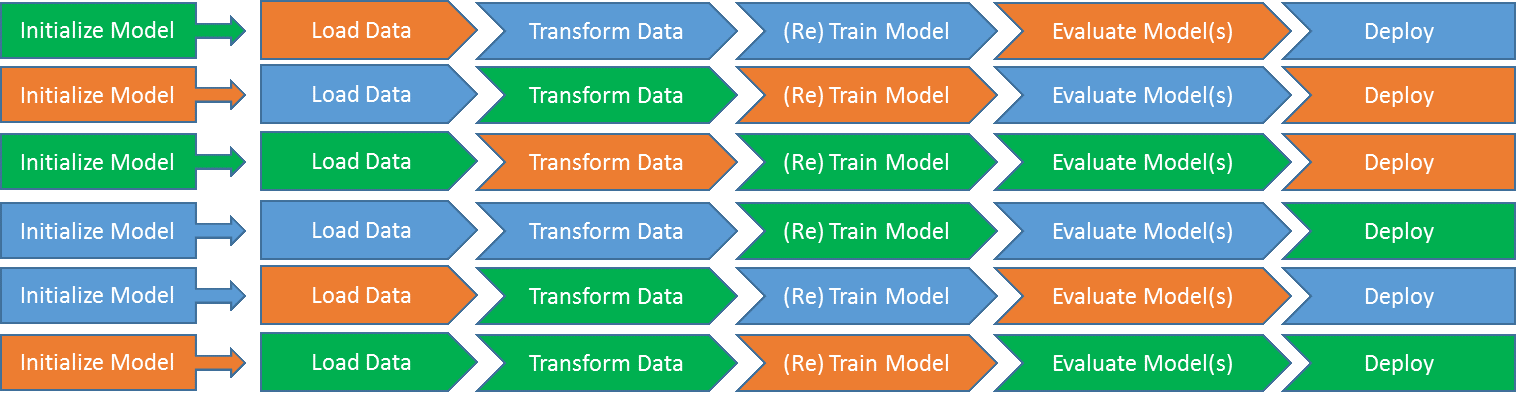
We may have only two different ways to deploy a model, e.g. as a PMML document and as a webservice. But we have a dozen different ways to access data that we want to combine with five different ways of training a model. If we had to split this into different families of model processes, we would end up with over a hundred variations. Using Model Factories, we need to define only the individual pieces (“process steps”) and combine them in flexible ways defined in a configuration file, for example. If somebody afterwards wanted to alter the data access or the preferred model deployment, we would only need to adjust that particular process step rather than having to fix all processes that use it.
Note that it often makes sense to split the evaluate-step into two: the part that computes the score of a model and the part that makes a decision on what to do with that score. The latter can include different strategies to handle champion/challenger scenarios and is independent to how we compute the actual score. In our KNIME implementation, described in the next step, we choose to follow this split as well.
Step 7. Putting Things to Work: The KNIME Model Factory
Using KNIME workflows as an orchestration vehicle, putting a Model Factory to work is actually straight forward: Configuration setups define which incarnation of each process step is used for each model pipeline. For each model, we can automatically compare past and current performance and trigger retraining/updating, depending on its configuration
Our recent white paper (“The KNIME Model Factory”) describes this in detail. KNIME Workflows represent process steps, the process pipeline, and also define the UI for the data scientists, allowing model processes to be edited, added, and modified using the KNIME WebPortal. You can download the workflow orchestrating all of this as well as an example setup of workflows modeling process steps from our EXAMPLES Server under 50_