
When manufacturing processes are no longer effective, what do you do?
The upheaval suffered by manufacturers since the COVID-19 pandemic has forced companies to rethink their processes. It’s not surprising that Six Sigma thinkers, as process improvement experts, are high on the go-to list for help.
But for Six Sigma experts it’s also time to rethink.
To see why, let’s take an example: Back In 2012, the process improvement team completed a DMAIC project to improve process performance of a plant’s production line. Their recommendations were operationalized and they concluded the project by installing a control system.
The purpose of the control system was to ensure continued performance of the new process at the plant. Any dip would be caught and rectified. This sounds good, but move forward now to 2022: The control system still validates performance based on the data that was collected ten years ago.
It’s highly likely that the data used in 2012 upon which the process was set up is no longer relevant. So why is new data never used by the control system?
In short, because DMAIC does not iterate between phases.
The DMAIC control phase is isolated from the analysis phase. In our DMAIC project, we collect the data, define the problem, run our analysis, operationalize our recommendation, and define a control system to ensure process performance. But the control phase never revisits the analysis. And our analysis is never re-run based on new data.
We need to merge the analysis and control phases to enable a continuous loop: Analyze → Operationalize → Control → Analyze → Operationalize → Control.
Over in the data science world, data scientists take an iterative approach, known as the data science life cycle. They are collecting the data (in real time) and learning from the data to then improve, describe and predict an outcome/produce an analysis. This outcome is what the data scientists call their model. To ensure that the model continues to perform well when operationalized, it is continually monitored and, whenever necessary, updated. Should there be a dip in performance they go back to retrain (update) their model on new data i.e. re-analyze - and re-operationalize.
Manufacturers are spending a lot of time, money, and effort to improve their processes. In DMAIC we also need to see how we can improve our process. To be truly sustainable, we need to merge the analysis and control phases and create an iterative cycle. We need to add data science.
Integrate a data science tool into our DMAIC projects
Collect data easily
As we monitor performance of our production line process, new data is flowing into our database on a daily basis from the sensors fitted to the machines. Typical statistical packages are unable to handle today’s high volume of data at high frequency; the effort to collect data – also from multiple sources – is huge.
Using a data science tool, we have the means to not only easily process huge volumes of data but also in real time. We can easily read in the 5 million datasets produced by our production line. Our data science solution literally “learns” from the data, evaluates the data, and produces a model. But it doesn’t stop there.
Reuse analysis
Our data science tool lets us go back to the beginning of the cycle and optimize our process based on the new data.
Now when new people come into the process e.g., a new supplier is needed for a certain part and new lines are developed, we can feed this new data into our analysis. We can reuse our model: It learns from the new data and produces an optimized result.
Respond to changing data
A single workflow for example, enables us to read in the 5 million datasets produced by the machine each day, evaluate this data, show us a visual prescan, and then run the data through three different models before providing us with a comparison to tell us which model is performing best. It only takes seconds to run.
The process is now immediately responsive to any changing circumstances reflected in the data. With our DMAIC tool we would have needed to start an entirely new project to solve the issue.
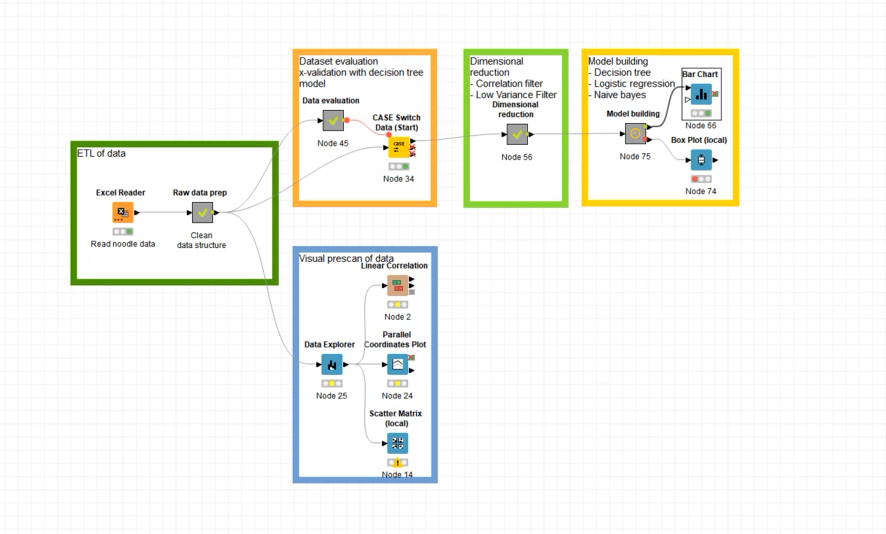
Interact and rerun any stage of the project
At any stage in the project, we can go into our analysis and check the output of different stages. We can inject our knowledge, as process experts, for example examine the correlation and numeric outliers to get a sense of the quality of the data and tweak as needed. We can use the prescan to interactively zoom in to inspect a group of figures in more detail.
If we see that something is wrong we can immediately go back a step, make an adjustment, and rerun the workflow.
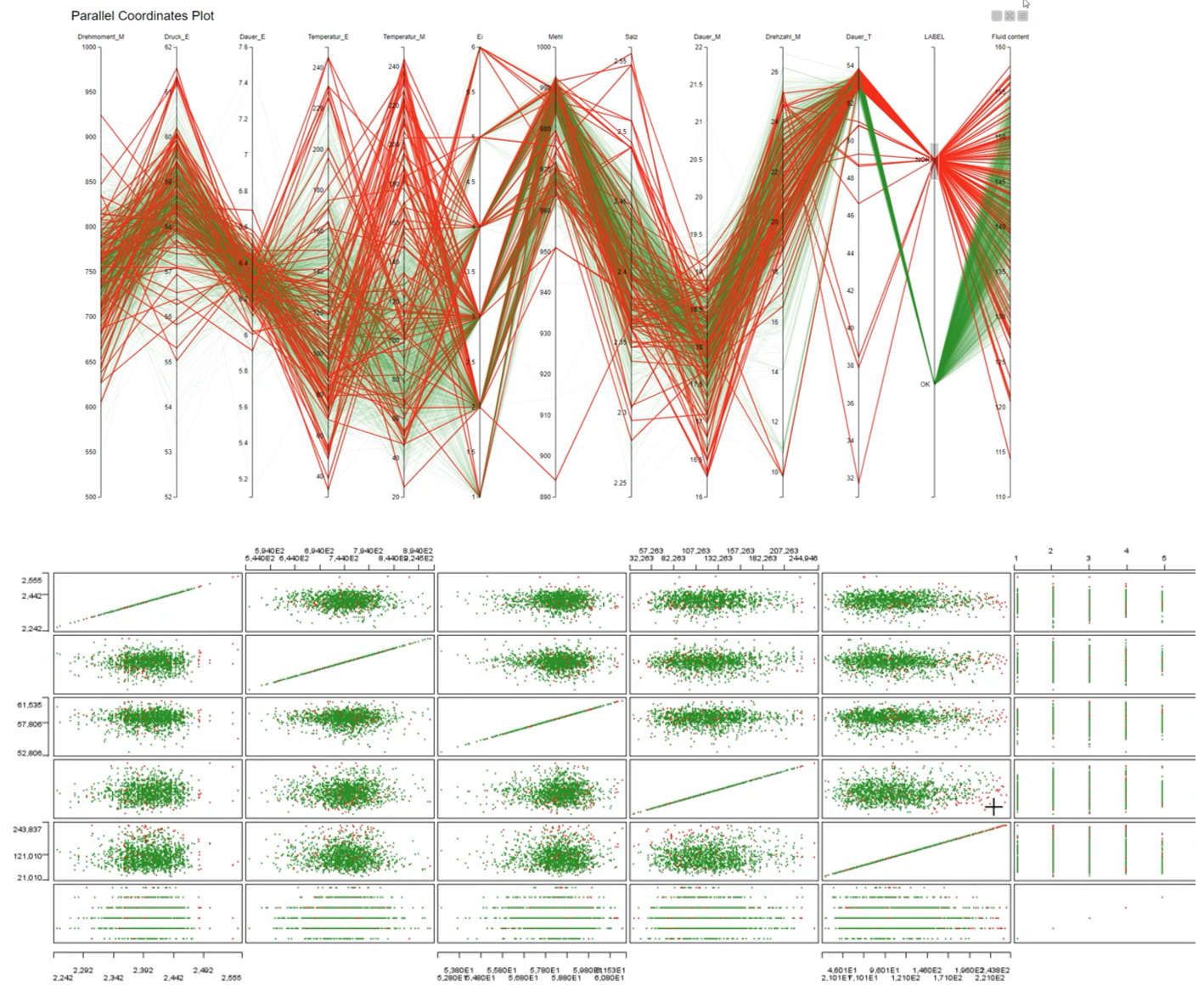
Compare multiple types of analysis to pinpoint optimal process performance
In a DMAIC project, we tend to define a single hypothesis, using regression analysis to measure whether results align with what we are expecting. But are we comparing our regression analysis with any other model type? Probably not.
With our workflow, however, we can not only regularly evaluate how our model is performing, but also set up multiple models and evaluate how they are all performing.
In our example, a visualized comparison shows us the quality of our three models. The results: Decision tree 0.91 - very high, Naive Bayes 0.73 - also good, Logistic Regression 0.74 show us that although our regression p value is OK, the decision tree is performing better. In typical Six Sigma tools, analysis techniques such as decision trees or Naive Bayes are not available options.
We can also decide to run each model based on 10 different test and training sets and it takes only a second. It provides us with failure rates and a visualization for each scenario.
A self-sustaining control system
With our data science solution, we can regularly evaluate our process, it is able to respond quickly to changes in the data, and we can compare – based on a range of models – if performances are changing, check why, and deploy the best process.
We can even automate this entire cycle.
By enabling the control system to be automatically monitored, evaluated, and (re)deployed, we ensure not only that it gets done reliably, but produces much more accurate results. When you tell a machine to control a process, it just does it. And keeps on doing it.
As first published in manufacturing.net: "For Six Sigma Black Belts: It's Time to Break Fresh Ground with Sustainable Process Performance