
Sentiment analysis of free-text documents is a common task in the field of text mining. In sentiment analysis predefined sentiment labels, such as "positive" or "negative" are assigned to text documents.
In a previous article we described how a predictive model was built to predict the sentiment labels of documents (positive or negative). In this approach single words were used as features. It was shown that the most discriminative terms w.r.t. separating the two classes are "bad", "wast", and "film". If the term "bad" occurs in a document, it is likely to have a negative sentiment. If "bad" does not occur but "wast" (stem of waste) it is again likely to score negatively, etc.
There are, however, several drawbacks to using only single words as features. Negations, such as "not bad" or "not good" for example, will not be taken into account. In fact single word features can even lead to misclassification. Using frequent n-grams as features in addition to single words can overcome this problem.
In this blog post we show an example of how the usage of 1- and 2-grams as features for sentiment prediction can increase the accuracy of the model in comparison with only single word features. The KNIME Text Processing extension is used again in combination with traditional KNIME learner and predictor nodes to process the textual data and build and score the predictive model.
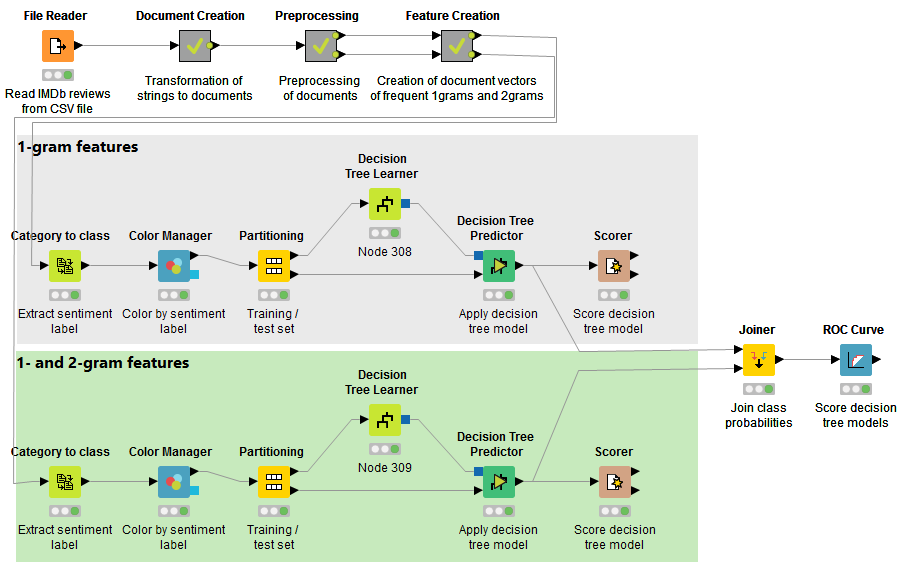
A set of 1500 documents has been selected from the training set of the Large Movie Review Dataset v1.0. Note that these documents have not been sampled randomly, but have been chosen on purpose in order to illustrate this approach. The Large Movie Review Dataset v1.0 contains 50,000 English movie reviews along with their associated "positive" and "negative" sentiment labels . For details about the data set see http://www.aclweb.org/anthology/P11-1015. We selected 750 documents from the positive group and 750 documents from the negative group. The goal here was to assign the correct sentiment label to each document.
The workflow associated with this article is available for download on the EXAMPLES server under: /009_TextMining/009008SentimentClassification-NGram.
Reading Text Data
As in the previous sentiment analysis article the data is available as a csv file and loaded into KNIME with a "File Reader" node. The textual data is transformed into documents using the "Strings to Document" node. The sentiment labels are stored in the category field of each document in order to extract the category afterwards. All columns with the exception of the column containing the document cells are filtered afterwards.
Text Pre-processing
The textual data is preprocessed by various nodes provided by the KNIME Text Processing extension. All preprocessing steps are applied in the second meta node "Preprocessing", as shown in the following Figure.
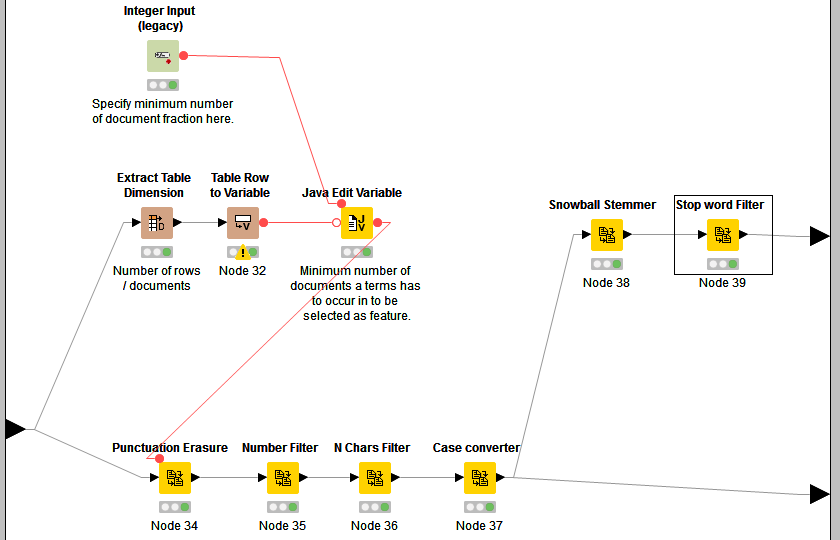
First, punctuation marks are removed by the "Punctuation Erasure" node: numbers and words with less than 2 characters are filtered, and all terms are converted to lowercase. The resulting documents are available at the bottom output port of the meta node. These documents (terms) are used to generate the 2-gram features later on in the next meta node. Stop words are not filtered here as we want to preserve words like "no" or "not". Also stemming is not applied because we want to build (and count) the n-grams based on the original words.
Stemming and stop word filtering is applied in an additional branch of the sub workflow. The resulting documents are available at the top output port of the meta node. Based on these documents (terms), the single word (1-gram) features are created in the next meta node.
In addition to the preprocessing nodes, a Quickform node "Integer Input" is used in the meta node to specify a minimum number of documents (in percent) as the workflow variable "MinPercentage". This number represents the minimum percent of documents in which a feature (1- or 2-gram) has to occur in order to be deemed frequent enough to be used as feature. As described in the previous sentiment article we assume that a term has to occur in at least 1% or 2% of all documents in order to represent a useful feature for classification later on. Here the default value of "MinPercentage" is set to 2.
At the same time, the number of available documents at the input port of the meta node is extracted and the minimum number of documents is computed based on the workflow variable "MinPercentage". The result is again stored as the workflow variable "MinDF". Here "MinDF" is 30, which is 2% of 1500 documents. "MinDF" is used later on to filter infrequent features.
Feature Extraction and Vector Creation
In the next "Feature Creation" meta node the features we want to use for classification are created and extracted, as shown in the following Figure.
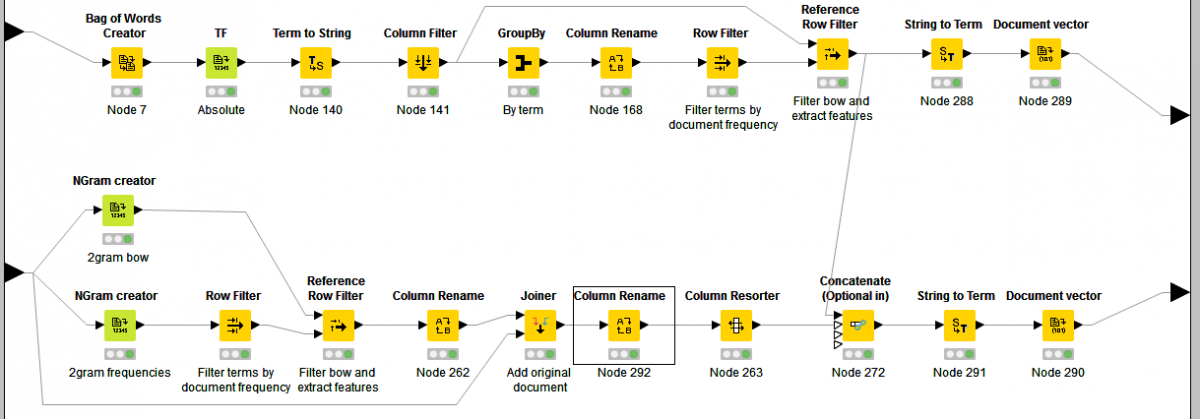
The meta node has two input ports and two output ports. In the top output port, document vectors are provided with single word features only. In the bottom output port document vectors with 1- and 2-gram features are available. These vectors are used for classification in the next steps.
In the top branch of the meta node, first a bag of words is created containing all single words (1-grams). This bag of words is filtered based on the minimum frequency "MinDF", which was computed in the previous meta node, and provided as the workflow variable. Terms that occur in less than "MinDF" documents are filtered out and not used as features.
In the bottom branch a bow of 2-grams is created as well as a list of all 2-grams together with their frequency in the document corpus. The 2-gram bow is filtered, again based on the minimum frequency "MinDF". 2-grams that occur in less than "MinDF" documents are filtered out and not used as features. Finally the 2-gram bow and 1-gram bow are concatenated and document vectors are created.
The vectors containing 1-grams only consist of 910 features (top output port). The vectors with 1- and 2-grams consist of 1865 features (bottom output port). Taking the 2-grams into account doubles the feature space in this case.
Classification
For both branches (top with 1-grams as features only, bottom with 1- and 2-gram features) predictive models are built, tested and compared. For classification we can use any of the traditional mining algorithms available in KNIME (e.g. decision trees, ensembles, support vector machines, and much more). When the documents have been created, the target variable is stored as a category in the documents. To extract the target variable as column the "category to class" node is used here, follow by a "Color Manager" which assigns the color red to documents with a negative sentiment and green to documents with a positive sentiment. The "Partitioning" node splits the dataset into training and test set in both branches.
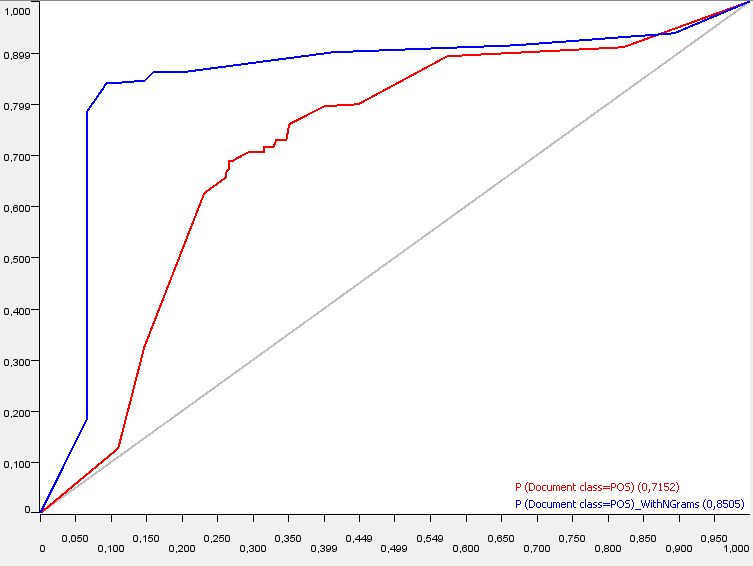
Finally two decision trees are built on the training sets and applied on the test sets. The decision tree in the top branch, trained on the data set with 1-gram features achieved only an accuracy of ca. 70%. The decision tree of the bottom branch, trained on the data set with 1- and 2-gram features achieved an accuracy of ca. 84%. The ROC curve of both models can be seen in the following Figure. The model of the bottom branch (blue curve) clearly outperforms the model of the top branch (red curve).
As in the previous sentiment analysis article, decision trees were used here as predictive models, as these models can be easily interpreted in contrast to a SVM model, for example. The following Figure shows a part of the decision tree of the model trained on the data set consisting of 1- and 2-grams.
The most discriminative feature w.r.t. separating the two sentiment classes is the feature "worst". In the second level of the left branch of the tree the 2-gram features "not good" and "not bad" have been selected. It can be seen, that if the word "bad" occurs, the sentiment of the document is not necessarily negative. The feature "not bad" also has to be taken into account. If the 2-gram occurs in the document it has most likely to be a positive sentiment, otherwise negative.
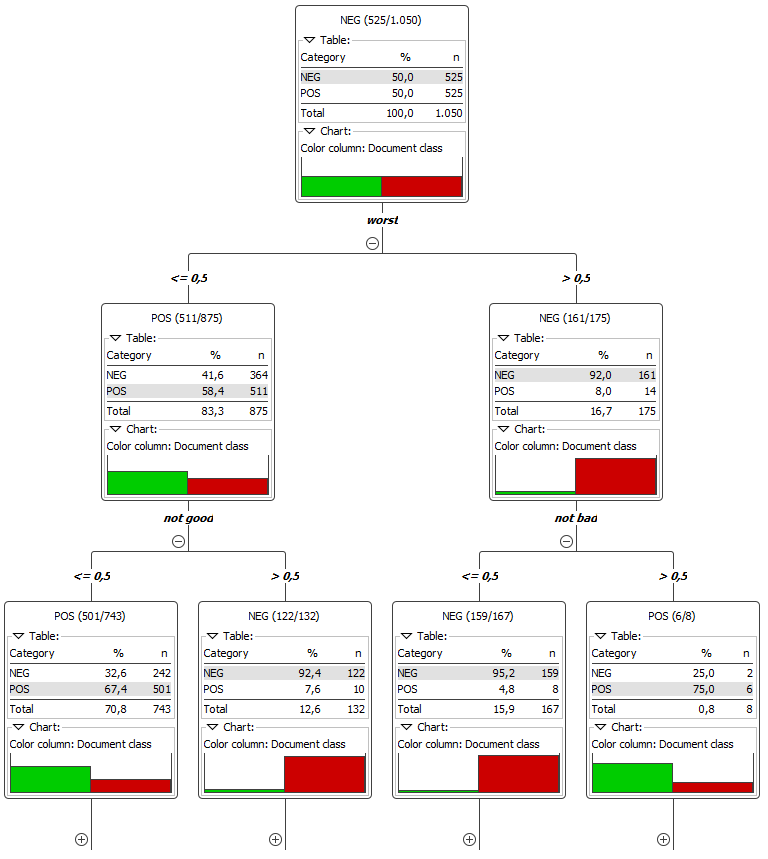
Here it can be seen clearly how n-grams used as features in classification can improve the result. However, they can also blow up the feature space tremendously. In this example the number of features doubled (from ~900 to ~1400) when also using 2-grams as features. Applying this on bigger data sets requires good feature selection methods to reduce the feature space before model building.
If you are interested and want to learn more about text mining with the KNIME Analytics Platform, come and visit us at the KNIME Spring Summit 2016 and attend at the text mining semiar at the 23. February, in Berlin.