
Data science can make robotic process automation more intelligent. Robotic process automation makes it easier to deploy data science models in production.
Robotic process automation (RPA) companies are endeavoring to deliver “the fully automated enterprise,” but even that promise may be shortsighted. Current trends are indicating that there’s much more that can be done with RPA - especially when combined with data science.
RPA tools started by getting computers to do the repetitive part of what humans do. The “robot” label here is key; it’s a metaphor that indicates that the software is not contained in one system but rather is connected with all (or many) of the information systems that a human worker touches.
An early RPA solution would mimic how a human interacts with systems, for example, by automatically routing calls that have to do with “support” to the tech team and routing calls that have to do with “sales” to agents. Or by scraping information from a website, like LinkedIn, and adding it to a CRM system whenever needed.
When RPA first met data science, this had industry-changing results. Rather than having humans look for new opportunities to improve automation, enterprises utilized “intelligent” process automation. You could now use machine learning to find patterns in real-life processes and help improve them automatically using a technique known as process mining. This was the step toward “the fully automated enterprise” that many RPA tools had been touting.
But a second wave of convergence between RPA and data science is opening new doors. This time, data science isn’t just helping RPA make human tasks more efficient - it’s helping execute some of these tasks better.
RPA and Data Science Meet Again
An increasing number of automated processes are dealing with data. In many cases, RPA programs are doing less pointing and clicking for humans and more downloading, sorting, combining, and even manipulating data. In the more advanced cases, the RPA programs are invoking machine learning models and adding the resulting predictions to the process automation.
Rather than simply help speed up a process, data science can be used inside the process to execute tasks more intelligently.
Those who have digitized their processes and made their workforce more efficient with RPA can now go a step further and integrate sophisticated data science techniques into their processes. The result is process automation becoming more intelligent and real-world data science becoming more automated.
Low-code Tools Smooth the Way
This trend is, at least in part, being enabled by low-code tools—technology that makes sophisticated technical processes human-readable and intuitive. This means that more advanced versions of RPA and data science can be more easily explained and endorsed. In some cases, they can be implemented by both technical and non-technical staff.
Low-code, visual platforms are not new to either domain. Low-code involves modules strung together visually in a “flow,” typically moving from left to right. This visual representation is both self-documenting and easily reusable for new projects.
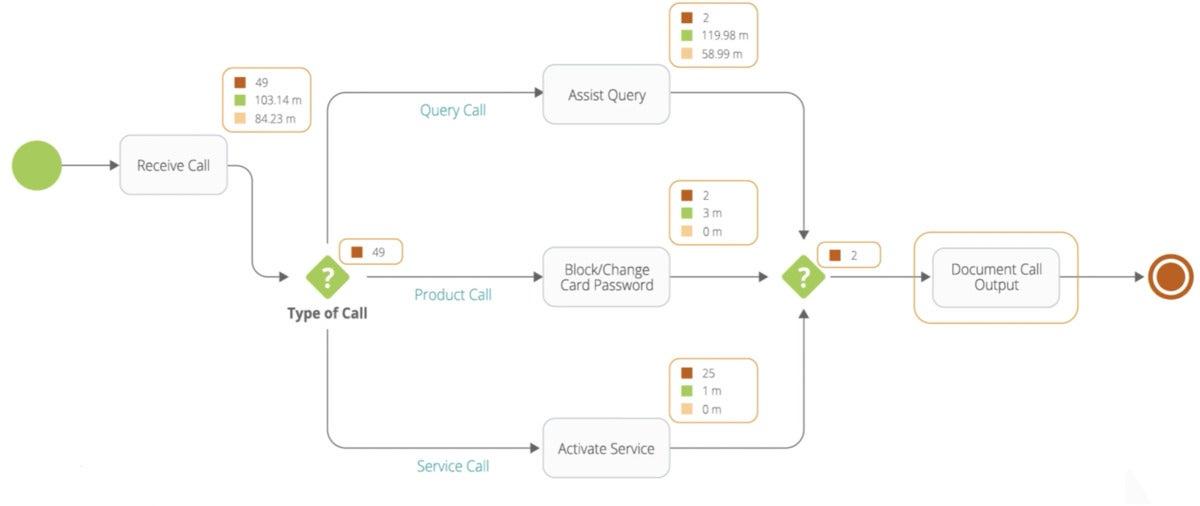
Low-code in an RPA context using the Bizagi Modeler.
The difference between how visual platforms are applied to the two use cases is subtle but significant. In RPA, the flow represents the order of a control flow—a series of actions that are performed, one after another. Some of these actions may even involve human interaction, such as approving a specific transaction.
In data science, the flow represents what’s done with data, how data is combined from different storage facilities (anything from Excel files to hybrid cloud databases), how it is transformed and aggregated, and how it might be fed to a machine learning algorithm or other analysis methods.
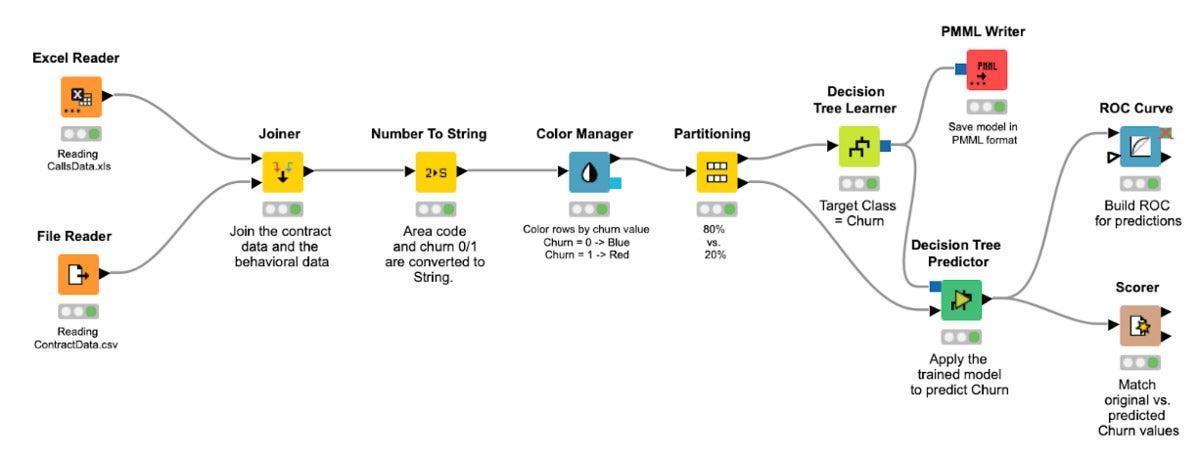
Low-code in a data science context using KNIME.
As mentioned above, however, there is overlap. Data flows not only exist in control flows but also vice versa. In a professional data science “visual programming” environment, we need to add control mechanisms to optimize parameters and determine which models are chosen for deployment.
The success of both RPA and data science relies on the integration of a number of different technologies, and low-code can significantly reduce the friction of implementing these. These implementations can be manually coded, but this can be a big effort in terms of mastering the various coding languages required as well as sharing what you’re doing with business counterparts.
RPA and Data Process Automation
Data science still has some maturing to do. While ETL and machine learning models have gotten quite sophisticated, we still run into a lot of issues when we try to apply these models in a real-life production environment. This is what we call the gap - taking our models and getting them to run in production, keeping them maintained, and knowing when to adjust them.
Deploying data science in production is, in essence, an RPA problem. How do we create a control flow between our models and the technology that we have integrated them with?
Perhaps the biggest challenge in data science has already been solved. We just have to spread the news. And rather than talking about “deploying data science,” we should be calling it “data process automation.”
As first published in InfoWorld.