

Hi! My name is Emil and I am a Teacher Bot. I am here to point you to the right training materials for your early questions on how to use KNIME.
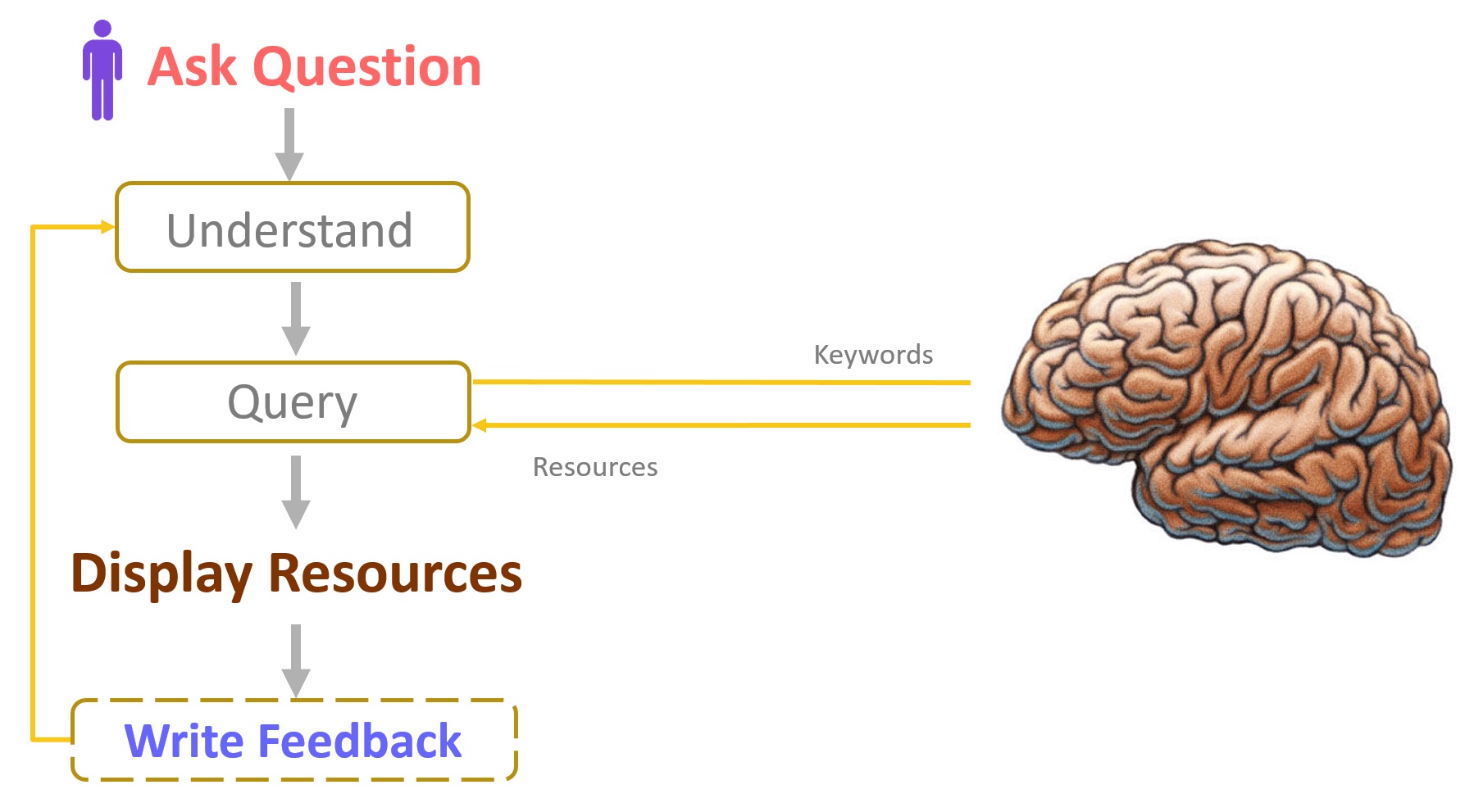
In a previous post, I described the KNIME workflow that built me. In that post the focus was on the details of my deployment (Fig. 1). A brain was mentioned, but very little explanation was given on the how-to for assembling it. The moment has arrived to give you some of these details and, in particular, to explain how my brain was conceptually designed to give answers.
Remember? It all starts with a question, your question. After parsing it and understanding it with the help of the KNIME Text Processing extension, queries are sent to my brain for possible answers.
Figure 1. Emil, the Teacher Bot. Here is what you need to build one: a user interface for question and answer, text processing to parse the question, a machine learning model to find the right resources, and optionally a feedback mechanism.
Educational Resources on the KNIME site
My ultimate goal is to provide you with the one and only web tutorial that perfectly answers your question. Let’s start then with the tutorial material that is available on the KNIME website.
First of all, of course, the e-learning course. The e-learning course consists of 7 chapters (so far). From installing KNIME Analytics Platform and its extensions to data access, from ETL procedures to Machine Learning, from data visualization to flow control: there is a good chance the topic you are looking for is here.
Another very much visited resource is the KNIME blog. The KNIME blog started in 2014 with the mission of producing nuggets of data science, machine learning, and KNIME tools.
Then, there is the Node Guide. Similar to the blog, this resource contains even more atomic pieces of information on single node and single use case usage.
Finally, there could be all the books from the KNIME Press, covering basic and advanced KNIME, text processing, data blending, ETL, etc …
In this repository consisting of some 400 pages, I am very likely to find what you need and probably more. The problem is that this “what you need” is not sorted and is not easy to find. Entering some meaningful keywords in the site search box, will probably lead you to a forum thread asking a similar question to yours. Note that if you can already identify some meaningful keywords, you are probably closer to the answer than you think. Be warned: if you try a conversational style, the site search engine will lose you completely. The advantage of me, however, is that I can understand your more complex text and I should – if trained properly – be able to match the right resource with your question keywords.
My brain needs training to match question and resource, i.e. ultimately the right resource URL. So, could this be done by training a machine learning model?
The questions in the KNIME Community Forum could be used as training examples. While it is true that the KNIME Forum should answer support questions, it is also true that a lot of questions start with “I am a beginner with KNIME….” This implies that the KNIME Community Forum is actually used also as an educational tool. A machine learning model could then be trained to associate the right resource URLs to the questions in the KNIME Forum.
All of the content of these educational pages on the KNIME site as well as the questions posted on the KNIME Forum, can be downloaded using the open source Palladian web crawling extension for KNIME Analytics Platform.
Data Science and Machine Learning in a Less than Perfect World
In a perfect world, there is a data set, a set of classes, and labels for all records in the data set. Using the provided class system and the corresponding labels, a training set and a test set can be created, a model can be trained on the training set and evaluated on the test set. This procedure can be repeated until performance is satisfactory. As I mentioned, this kind of things happens in a perfect world, which you might experience in a Kaggle dataset, but rarely in everyday life.
In the real world, there is a data set, tons of missing values, no labels, and sometimes even no clue about which class system to use. This is exactly our case.
Figure 2. Data in a perfect world on the left and data in a less than perfect world on the right. In a real life project often data miss values, labels, and even a class system.

We have the forum questions on the one hand, which we want to use as the training set, and the tutorial pages on the other, to be used as classes. Unfortunately questions in the forum are not always linked to any of the tutorial pages, i.e. labels in the data set are not provided. This hints at unsupervised machine learning, with some kind of clustering or distance based assignment.
As a matter of fact, the first attempt to build my brain relied on a Tanimoto similarity measure, matching the keywords extracted from each question with the keywords extracted from the resource pages. Results were sub-optimal. The a priori distribution of resource topics and the low number of extracted keywords constrained the model to opt for resource documents belonging to the most frequent topic. Indeed, the largest group of resources deals with how to install KNIME Analytics Platform and its extensions. Therefore, questions were often redirected to installation resource pages. Experimenting with other similarity measures did not change the assignment strategy considerably.
So, if the first unsupervised attempt was disappointing, I hear you say, what are the other options? Active learning could be an alternative option to refine the label system. Active learning starts with a data set with potentially faulty labels, trains a model, extracts a subset of the original data set for manual relabeling, retrains the model, and repeats until no significant change in model performance can be observed.
The data set resulting from the label assignment based on Tanimoto similarity measure could be the starting point of an active learning procedure. Active learning would accept our data set with possibly (surely) faulty labels as the starting point. The next step would be to train a supervised model on it, i.e. on a training set with approx. 400 possible classes, i.e. the 400 resource page URLs. This is clearly not feasible, especially considering the fact that the number of questions available on the KNIME Forum between 2013 and 2017 barely exceeds 5000.
We need to rethink the class system. Let’s go back to the beginning.
My ultimate goal is to provide you with the one and only web tutorial page that answers your question. Well, this is hardly possible. Even if you are a beginner to KNIME, you often ask questions that require material from two or three or even four different tutorials to get the right answer.
It is probably better to provide you with a list of potentially helpful tutorials, rather than just one. Furthermore, it might even be best to identify the areas of expertise touched by your question and then to identify the most relevant tutorial resources for each one of these areas. This is what my brain should do: identify the areas of expertise and, from these, identify the list of the most relevant articles.
That is, my thinking organ should consist of a machine learning model coupled together with a similarity search feature. The machine learning model should be trained to identify such areas of expertise and the similarity search feature should identify the list of the most relevant articles within each area. This opens up a whole new set of problems:
- Selection and training of a machine learning model
- Definition of the areas of expertise, i.e. the class system, on which to train the model
- Set-up of an active learning framework to iteratively refine the labels in the training set
- Implementation of a similarity search procedure
In this blog post, I focus only on problem number 2: definition of the areas of expertise, i.e. of the class system, on which to train the model. We will leave the labeling of the data, the model training, and the distance implementation to be discussed in the next blog posts in this series.
An Ontology for Emil
A class system is also referred to as a class ontology.
An ontology is a set of entities, each with a name, properties, and relations to the others. A class ontology is a set of classes, each with a name, possible properties and relations. The most famous class ontologies can be found in medicine, such as anatomy ordered classes, or inter-related animal classes in biology. In a data science problem, an ontology is a set of classes used to train a machine learning algorithm. To get more information about ontologies and why they are needed, you can check R. Shane’s post “Why Ontologies?”
As a result of algorithm limitations, a class ontology should contain a limited number of high level classes, especially with a training set of reduced size. In our case, we are looking for an abstraction of the ~400 tutorial pages into 20 or maybe 30 higher level classes.
One of the main principles in data science (as in life, too) is to avoid reinventing the wheel. If something can be reused, then let’s reuse it!
For example, the KNIME e-learning course which has been organized in 7 chapters: Installation and Introduction; Data Access; ETL; Data Export or Deployment; Data Visualization; Machine Learning and Predictive Analytics; and Control Structure. These chapters could be used as the first 7 classes of the desired ontology to identify questions about installation, data access, and so on.
Figure 3. Introductory Course to Data Science on the KNIME site is organized in 7 main chapters.

Other popular resources on the KNIME website include a number of extensions - such as text processing, image processing, big data, and reporting – documentation about the KNIME Server, and use cases in the form of simple solutions or more complex whitepapers. Let’s add these additional six classes to the ontology.
Having started with class assignment via active learning and with model training, it soon became evident that 13 classes are not yet enough to describe all of the questions stored in the KNIME Forum! Looking closer, we also see questions about node development, integration (mainly with R and Python), specific life science topics, and software performance. In addition, a few posts are simply announcements of partner extension releases, bug reports, or copyright questions. These additional 7 classes, taken from experience, have been added to the initial ontology.
The final class ontology is shown in Figure 4 and consists of 20 classes. I am sure it could be refined and perfected further while I am accumulating experience.
Figure 4. Final class ontology used to train a supervised model to categorize questions from the KNIME Forum. The model will then be part of the brain used for Emil the teacher bot.

The next step consists of properly labeling some of the questions in the dataset, according to this set of classes, which will be used as the training set. Since manually labelling all questions in the training set was not budgeted, an active learning strategy was adopted. And this specific topic is also a topic for another blog post in this series!
Do not get too attached!
Even though defining a class ontology is not a code writing or workflow building activity per se, it is nevertheless of vital importance for the success of the project. Indeed, this was the breakthrough point while building my brain.
Please remember to always keep a healthy degree of detachment from what you have built so far. It might need to be adjusted or even remade. Do not make the mistake of desperately wanting to keep your past work at all costs. Especially at the beginning of a project, the class ontology and the system architecture must undergo a number of more or less drastic changes!
Have you seen the new KNIME Community Forum? It has a completely new look and feel and a large amount of new functionalities. For example, now you can rate answers, like posts, and share the most useful comments. If you have not already, register and start exploring the new KNIME Community Forum!