
KNIME continually prioritized access to more cutting-edge analytic techniques for its users. Here’s why.
Investing in a data science platform that has no limit on analytic capabilities is the difference between a short-term and a long-term digital transformation initiative.
Even though more than half of organizations are still somewhere between the “crawl” and “walk” phase of analytic readiness, the pace of adoption of AI has drastically accelerated over the course of the pandemic. In fact, according to PwC, machine learning and data science is just a few years away from being considered “mainstream technology.”
Retooling and upskilling an organization to effectively make sense of their data can take anywhere from 3-5 years, yet the processes to use data at scale – at any level of sophistication – is the same. Data teams need to ensure compliant data collection and proper storage, they need a standardized tool set for data pipelining, they need visualization and self-service tools, they need modular components for use and reuse, and so on. Irrespective of where you are in your analytic journey, you’ll want to set the foundation to either catch up or spring ahead, as the data science landscape evolves.
Here’s how you can future proof your investment in the right data analytics platform.
Your Checklist for Analytic Sophistication
Because of the hype surrounding the topic, headlines have begun to use the term “AI” liberally. Seeing “AI” or “Machine Learning” on a website is no longer telling – leaders need to do their due diligence to ensure that the platform they choose truly offers broad analytic capabilities.
First, ensure that the platform connects to all your necessary data sources, and can support working with all data types – not just strings and integers, but also images, text, networks and location.
Next, see if all the current popular and advanced analytics algorithms are accessible through the platform. Today, a data scientist toolbox should include:
-
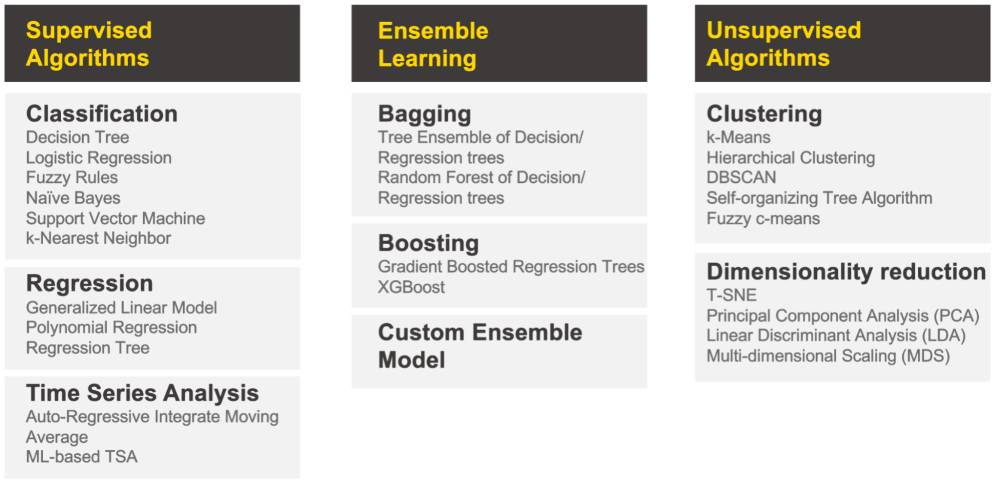
Classification techniques used to assign items to categories. For example a classification model could be used to identify customers at high, medium or low risk of churn. Techniques include Decision Tree, Logistic Regression, Naive Bayes, Support Vector Machine, Fuzzy Rules and k-Nearest Neighbor.
-
Regression techniques, used to predict numeric outcomes based on other, known factors. For example, a regression might be used to predict how an increase in advertising spend might affect the return on that investment. Regression techniques include Polynomial Regression, Generalized Linear Model, and Regression trees.
-
Time Series Analysis techniques that deal with trend analysis. This kind of technique is used to see trends over time, based on defined time intervals. Many marketing and sales teams, for instance, already use this technique when they look at month over month revenue or quarterly churn numbers. More sophisticated techniques include Auto-Regressive Integrate Moving Average (ARIMA), and ML-based Time Series Analysis.
-
Clustering techniques identify naturally occurring groups in your dataset. Unlike classification, which requires you to define labels, clustering is an “unsupervised” analysis–so it identifies patterns without predefined labels. A health insurance provider might use clustering to identify high-risk groups based on doctor visits per year, age, household size and chronic conditions. Examples of Clustering include k-Means, Hierarchical Clustering, DBSCAN, Self-organizing Tree Algorithm and Fuzzy c-Means.
-
Dimensionality Reduction techniques help make a dataset more manageable by reducing the number of attributes, without sacrificing the variation. High dimensionality in a dataset can impede model performance and require exorbitant computing resources, while also being extremely difficult to visualize and explore. Algorithms like Principal Component Analysis (PCA), t-SNE, and Linear Discriminant Analysis (LDA) cover these distinct use cases.
As new algorithms are invented, they’re typically made available in ML libraries. When evaluating analytics tools, ensure that the platforms integrate with the currently popular libraries, like Tensorflow or Keras, and with the ONNX ecosystem – and try to get a sense of how quickly the vendor integrates new libraries. Here, open platforms offer a definitive advantage, as community-driven innovation keeps products up to date with any industry-adopted tools and languages.
A platform that supports all of the above ensures that your business and data experts never reach a moment of “now what?”
Why KNIME
From day one, KNIME was built for real data science. With KNIME’s low-code, no-code approach, data experts could always focus on extracting meaningful insights from their data–rather than worry about keeping up to speed with programming languages and/or client server architecture. Over the years, KNIME has invested significantly in the intuitiveness and ease of use of the platform, opening it up to beginner users and domain experts. KNIME now offers complete depth and breadth for advanced users, while still offering an easy on-ramp for those just getting starting with data science.
KNIME offers all basic statistics and ETL capabilities, and enables automation of any manual tasks that can be performed in a spreadsheet. For advanced users, KNIME supports dozens of analytical techniques including supervised, semi-supervised and unsupervised algorithms.
Because KNIME is an open platform, users have access to all the popular machine learning libraries, including TensorFlow, Keras and H2O. The platform makes it easy for users to mix and match any of the tools and techniques they know and love and apply it to data that sits anywhere.
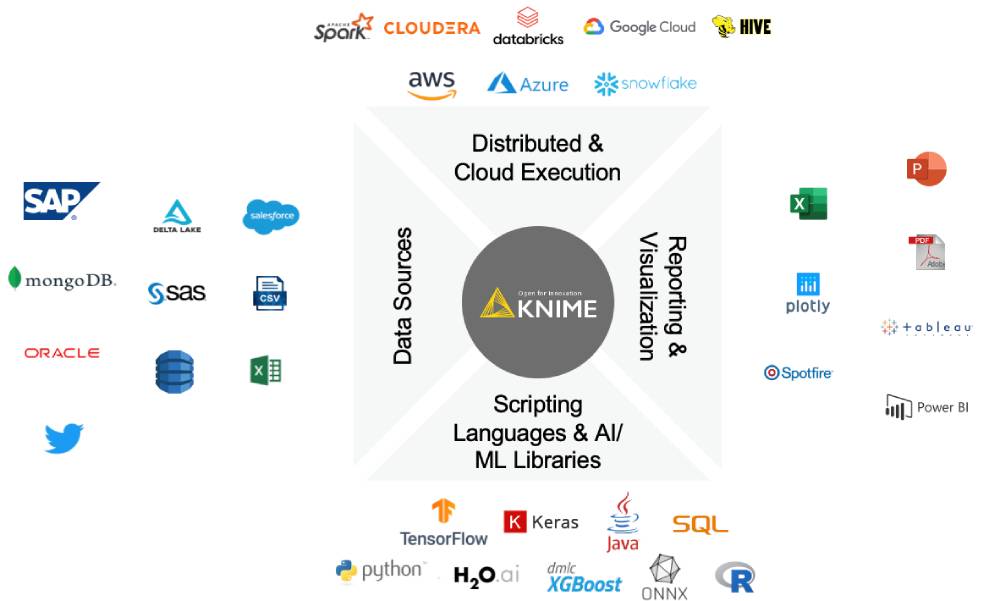
KNIME also offers a Python integration, allowing data scientists to run their scripts seamlessly in KNIME workflows. The extension supports scripting, model building and prediction, and visualizations. KNIME users can make their expertise available to others in their organization by bundling Python scripts as reusable components. Furthermore, scripters can build out new functionality to enable non-experts to fully benefit from the Python ecosystem.
Finally, KNIME’s open source approach ensures that any new tools and techniques in the market will be integrated quickly and made available for the wider community.
Analytic Sophistication in an End-to-End Platform
Ultimately, the sophistication of your algorithms doesn’t matter in a vacuum. You also need the capability to be able to test, validate, deploy and monitor your models safely and efficiently ensure that you’re actually getting value out of the insight that the analysis produces. For that reason, it’s much better to choose a platform that offers both: analytic sophistication as well as end-to-end data science support.
Learn more about what else you should consider when choosing an analytics platform in our recent e-Guide.