
More and more often people are finding that the amount of available raw data collected by a system can grow exponentially fast, quickly reaching a very large size and a very high number of features, sometimes even qualifying for what is referred to as “big data”. In the case of really large data sets, it can then be helpful to take advantage of big data platform performances, especially to run ETL procedures.
Connecting to a big data platform can generally be quite complex, requiring pieces of dedicated code. However, KNIME provides a number of connector nodes for connecting to databases in general and to big data platforms in particular. Some connector nodes have been designed for specific big data platforms, hard-coding and hiding the most complex configuration details. These dedicated connector nodes therefore provide a very simple configuration window requiring only the basic access parameters, like the credentials. Such connector nodes are available under KNIME Big Data Extension.
Connector nodes produce a connection to a database / big data platform at their output port (red square port) and do not include any SQL queries. Dedicated connectors are available, as of today, for Cloudera Impala (Cloudera certified), Apache Hive (Cloudera and Hortonworks certified), and HP Vertica. And if a dedicated connector is not available for the big data platform of choice, you can always connect using a generic Database Connector node. Here though you need to upload the JDBC driver for the chosen platform in the Preferences page and set it in the configuration window of the Database Connector node. JDBC drivers must be provided by the vendor.
With KNIME Big Data Extensions, you no longer need to know all the big data related java code instructions to be able to connect to a big data platform!
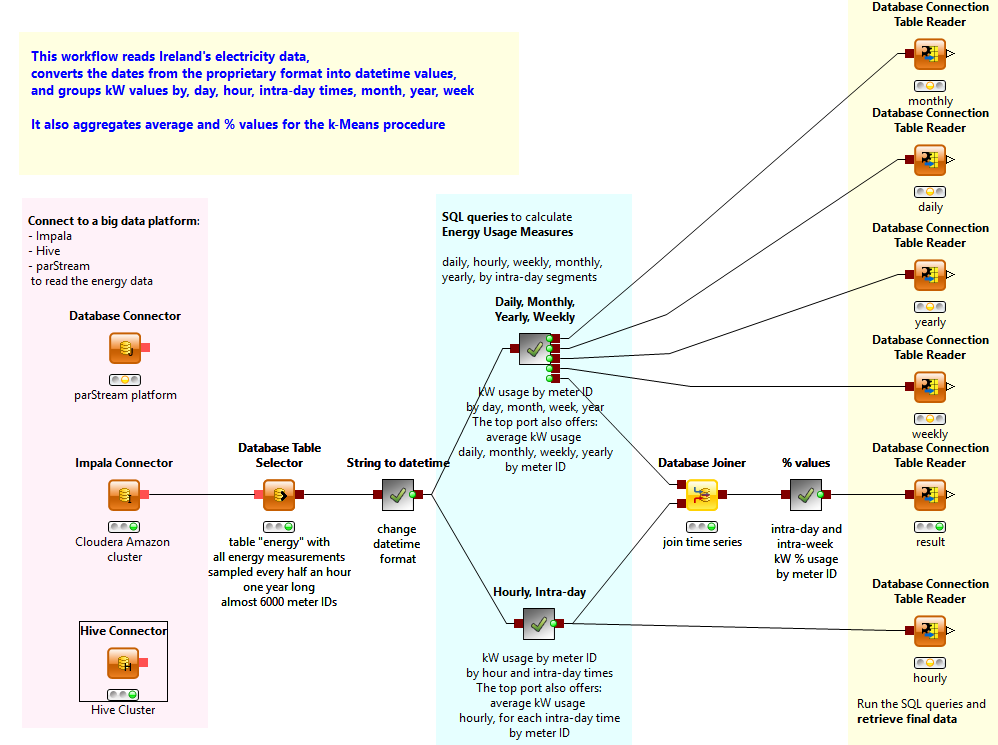
After the connection has been established a series of SQL helper nodes follow to select the original table, perform the required SQL queries, and retrieve the resulting data.
There are many big data platforms available to the data analyst and often the choice of one or the other can only be made after thorough testing of speed and implementation difficulties. The usage of KNIME connector nodes makes such testing easy and fast. A workflow can contain a number of different connectors to as many different big data platforms. At each time, only one of the established connections is piped into the following cascade of SQL helper nodes. Thus, running the SQL helper nodes on a different big data platform only requires connecting a new connector node to the cascade of SQL helper nodes!
The figure below shows three Connector nodes: Impala Connector, Hive Connector, and a generic connector used to connect to the parStream platform. It also shows a number of metanodes embedding SQL manipulation nodes that implement the required ETL operations.
The latest whitepaper, titled “KNIME Opens the Doors to Big Data” includes a step-by-step guide to implement and run a few ETL operations on any big data platform from within a KNIME workflow.
In summary, the integration of a big data platform into KNIME is very straightforward.
- Drag & drop the appropriate connector node into the workflow to connect to the big data platform of choice
- Configure the connector node with the parameters required to access the data on the big data platform, meaning: credentials, server URL, and other platform specific settings
- Define the SQL query to perform the ETL operations with the help of SQL manipulation nodes. The SQL manipulation nodes indeed help you to build the correct SQL query without you needing to know a thing about SQL queries.
- Finally, the execution of a data retrieval node (Database Connection – Table Reader node) enables data retrieval according to the previously built SQL query.
Such an easy approach opens the door to the introduction of big data platforms into KNIME, without the headache of configuring each tiny platform detail. It also preserves the quick prototyping feature of a KNIME workflow. Indeed, the user can change the big data platform of choice, just by changing the database connector node in step 1 and reconnecting it to the subsequent SQL builder nodes.
It is really that easy to integrate big data platforms in KNIME and considerably speed up the whole ETL part of the data science discovery trip! For firsthand insights about the KNIME Big Data Extension come to the User Group Meeting 2015 in Berlin and attend at the Big Data workshop.
In the mentioned whitepaper, we rescued an ETL workflow developed in 2013 for the analysis of energy usage time series (see KNIME whitepaper: “Big Data, Smart Meters, and Predictive Analytics”). Data about energy usage had been collected for more than a year through smart meters in an experimental project in Ireland between 2009 and 2011.
Introducing big data platforms to the workflow for the execution of the ETL operations reduced the execution time from almost two days to less than half an hour!
The workflow used in this whitepaper is available on the EXAMPLES server under 004_Databases/004005_Energy_Prepare_Data (Big Data). A sample of the original data can be retrieved from www.knime.com/files/reducedenergydata.zip . Please remember that we are not allowed to distribute the original dataset. The entire dataset must be requested directly from the Irish Social Science Data Archive reported below: http://www.ucd.ie/t4cms/CER_energy_electric_issda-data-request-form.docx.