This is a revised edition of the article that was first published in InfoWorld, April 30, 2020.
Deploying data science for production is still a big challenge. Not only does the deployed data science need to be updated frequently but available data sources and types change rapidly, as do the methods available for their analysis. This continuous growth of possibilities makes it very limiting to rely on carefully designed and agreed-upon standards or work solely within the framework of proprietary tools.
KNIME has always focused on delivering an open platform, integrating the latest data science developments by either adding our own extensions or providing wrappers around new data sources and tools. This allows data scientists to access and combine all available data repositories and apply their preferred tools, unlimited by a specific software supplier’s preferences. When using KNIME workflows for production, access to the same data sources and algorithms has always been available, of course. Just like many other tools, however, transitioning from data science creation to data science production involved some intermediate steps.
In this post, we are describing an addition to the KNIME workflow engine that allows the parts needed for production to be captured directly within the data science creation workflow, making deployment fully automatic while still allowing every module to be used that is available during data science creation.
Why is deploying data science in production so hard?
At first glance, putting data science in production seems trivial: Just run it on the production server or chosen device! But on closer examination, it becomes clear that what was built during data science creation is not what is being put into production.
I like to compare this to the chef of a Michelin star restaurant who designs recipes in his experimental kitchen. The path to the perfect recipe involves experimenting with new ingredients and optimizing parameters: quantities, cooking times, etc. Only when satisfied, are the final results — the list of ingredients, quantities, procedure to prepare the dish — put into writing as a recipe. This recipe is what is moved “into production,” i.e., made available to the millions of cooks at home that bought the book.
This is very similar to coming up with a solution to a data science problem. During data science creation, different data sources are investigated; that data is blended, aggregated, and transformed; then various models (or even combinations of models) with many possible parameter settings are tried out and optimized. What we put into production is not all of that experimentation and parameter/model optimization — but the combination of chosen data transformations together with the final best (set of) learned models.
This still sounds easy, but this is where the gap is usually biggest. Most tools allow only a subset of possible models to be exported; many even ignore the preprocessing completely. All too often what is exported is not even ready to use but is only a model representation or a library that needs to be consumed or wrapped into yet another tool before it can be put into production. As a result, the data scientists or model operations team needs to add the selected data blending and transformations manually, bundle this with the model library, and wrap all of that into another application so it can be put into production as a ready-to-consume service or application. Lots of details get lost in translation.
For our Michelin chef above, this manual translation is not a huge issue. She only creates or updates recipes every other year and can spend a day translating the results of her experimentation into a recipe that works in a typical kitchen at home. For our data science team, this is a much bigger problem: They want to be able to update models, deploy new tools, and use new data sources whenever needed, which could easily be on a daily or even hourly basis. Adding manual steps in between not only slows this process to a crawl but also adds many additional sources of error.
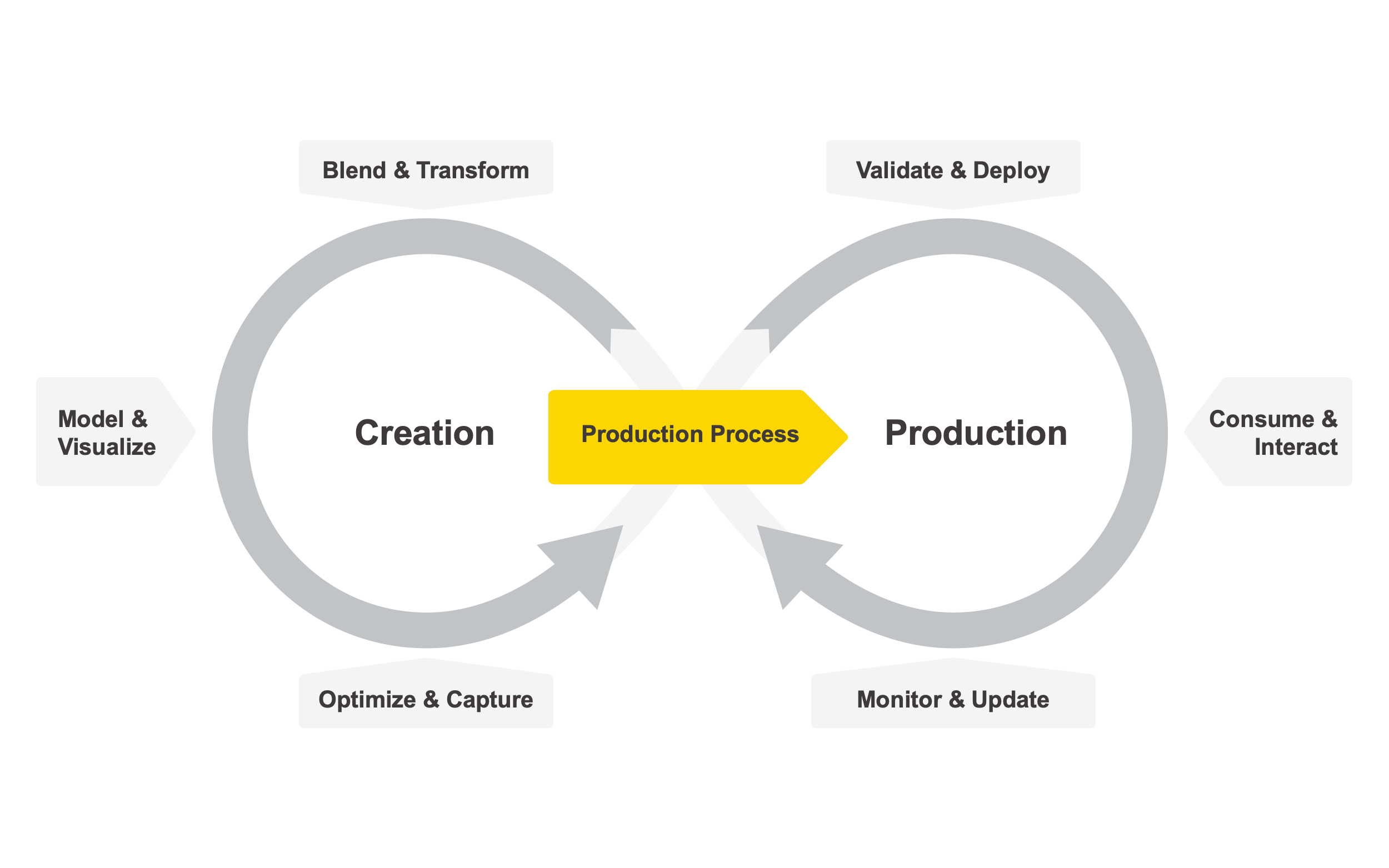
The diagram below shows how data science creation and productionization intertwine. This is inspired by the classic CRISP-DM cycle but puts stronger emphasis on the continuous nature of data science deployment and the requirement for constant monitoring, automatic updating, and feedback from the business side for continuous improvements and optimizations. It also distinguishes more clearly between the two different activities: creating data science and putting the resulting data science process into production.
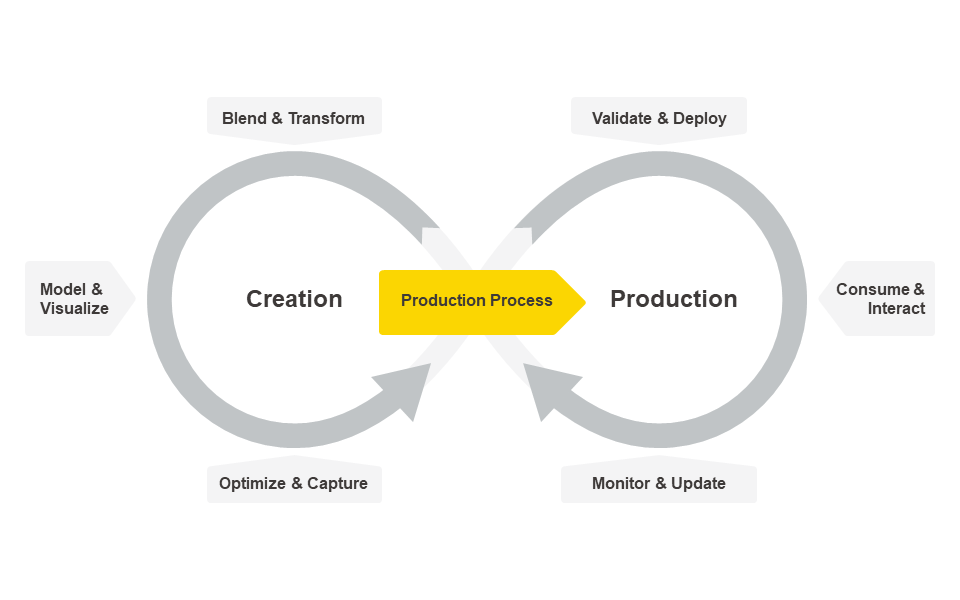
Often, when people talk about “end-to-end data science,” they really only refer to the cycle on the left: an integrated approach covering everything from data ingestion, transforming, and modeling to writing out some sort of a model (with the caveats described above). Actually consuming the model already requires other environments, and when it comes to continued monitoring and updating of the model, the tool landscape becomes even more fragmented. Maintenance and optimization are, in many cases, very infrequent and heavily manual tasks as well. On a side note: We avoid the term “model ops” purposely here because the data science production process (the part that’s moved into “operations”) consists of much more than just a model.
Removing the gap between data science creation and data science production
Integrated deployment removes the gap between data science creation and data science production by enabling the data scientist to model both creation as well as production within the same environment by capturing the parts of the process that are needed for deployment. As a result, whenever changes are made in data science creation, these changes are automatically reflected in the deployed extract as well. This is conceptually simple but surprisingly difficult in reality.
If the data science environment is a programming or scripting language, then you have to be painfully detailed about creating suitable subroutines for every aspect of the overall process that could be useful for deployment — also making sure that the required parameters are properly passed between the two code bases. In effect, you have to write two programs at the same time, ensuring that all dependencies between the two are always observed. It is easy to miss a little piece of data transformation or a parameter that is needed to properly apply the model.
Using a visual data science environment can make this more intuitive. The KNIME Integrated Deployment extension allows those pieces of the workflow that will also be needed in deployment to be framed or captured. The reason this is so simple is that those pieces are naturally a part of the creation workflow. This is because first, the exact same transformation pieces are needed during model training, and second, evaluation of the models is needed during fine tuning. The following image shows a very simple example of what this looks like in practice:
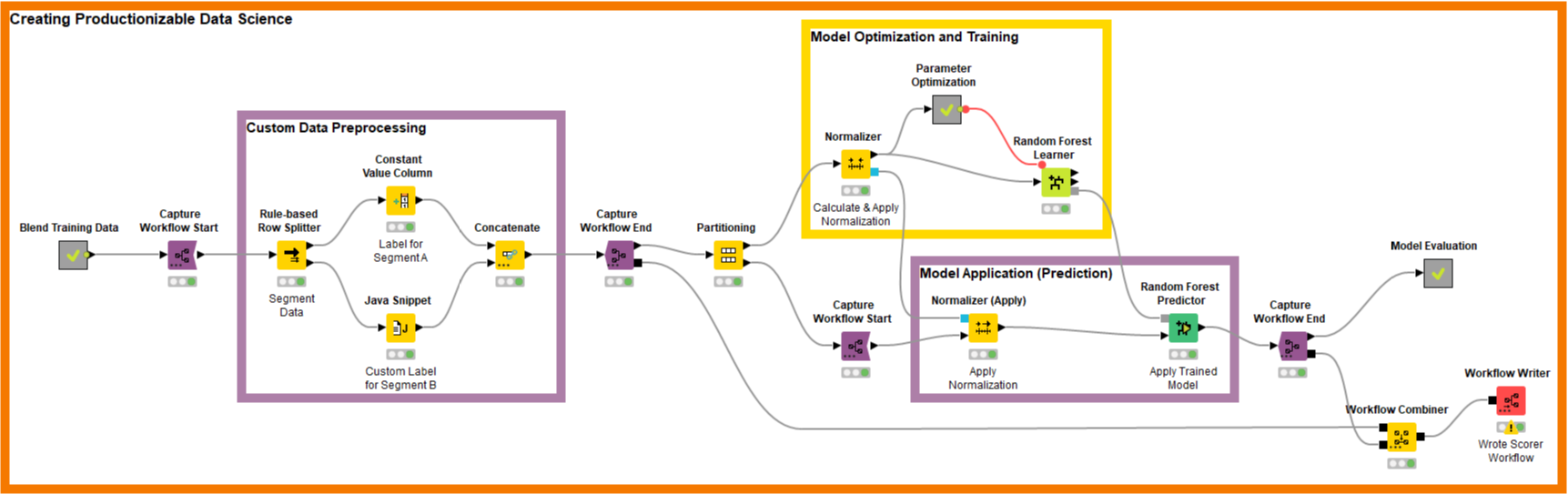
The purple boxes capture the parts of the data science creation process that are also needed for deployment. Instead of having to copy them or having to go through an explicit “export model” step, now we simply add Capture-Start/Capture-End nodes to frame the relevant pieces and use the Workflow-Combiner to put the pieces together. The resulting, automatically created workflow is shown below:
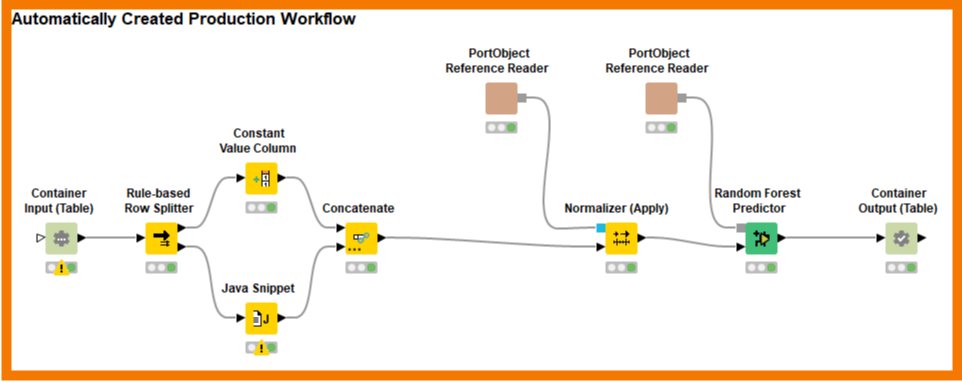
The Workflow-Writer nodes come in different shapes that are useful for all possible ways of deployment. They do just what their name implies: write out the workflow for someone else to use as a starting point. But more powerful is the ability to use Workflow-Deploy nodes that automatically upload the resulting workflow as a REST service or as an analytical application to KNIME Business Hub or deploy it as a container — all possible by using the appropriate Workflow-Deploy node.
The purpose of this article is not to describe the technical aspects in great detail. Still, it is important to point out that this capture and deploy mechanism works for all nodes in KNIME — nodes that provide access to native data transformation and modeling techniques as well as nodes that wrap other libraries such as TensorFlow, R, Python, Weka, Spark, and all of the other third-party extensions provided by KNIME, the community, or the partner network.
With the Integrated Deployment extension, KNIME workflows turn into a complete data science creation and productionization environment. Data scientists building workflows to experiment with built-in or wrapped techniques can capture the workflow for direct deployment within that same workflow. For the first time, this enables instantaneous deployment of the complete data science process directly from the environment used to create that process.