
This blog describes the usage of KNIME Analytics Platform to compare the runtime performance of two different Hive execution engines. The heart of an analysis in KNIME is a workflow that consists of nodes representing operations on data and edges representing the data flow between nodes.
The Workflow
KNIME workflow comparing different Hive execution engines by running an SQL query several times for each engine.
The workflow in Fig. 1 compares the runtime performance of the default Hive execution engine based on MapReduce with the new execution engine based on Tez. The workflow consists of standard KNIME nodes in conjunction with the Hortonworks certified Hive Connector node, which is part of the KNIME Big Data Extension. As a test cluster, we use the Hortonworks Sandbox in version 2.2. The Hortonworks Sandbox is a full featured HDP platform bundled in a virtual machine that gets you up and running in 15 minutes. However you can also use your own cluster by simply changing the connection parameters in the Hive Connector node.
At the center of the workflow is the “SQL Generation” MetaNode (grey node with green tick), which defines the SQL statement executed with Hive. KNIME allows you to collapse parts of a workflow into MetaNodes to hide complex subflows in order to make the flow easier to understand. These MetaNodes can be stored to be re-used and shared with other people.
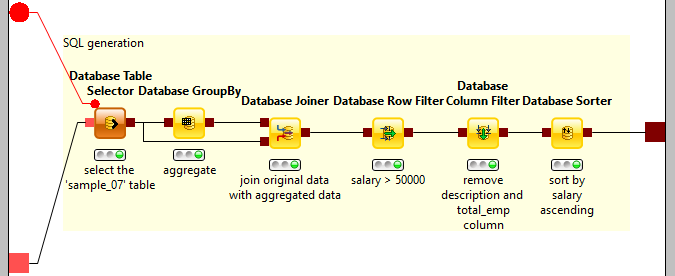
The subflow within the “SQL Generation” MetaNode that generates the SQL query to be executed in the loop.
The “SQL Generation” MetaNode consists of database nodes that are part of the open source KNIME Analytics Platform (see Fig. 2). These nodes allow you to visually assemble DB operations modularly and create complex SQL statements without having to write any code.
Each of the database nodes comes with a user-friendly interface to tweak the individual query parameters. For example, Figs 3 and 4 show the dialog of the Database GroupBy node where you can specify the grouping columns as well as the aggregation columns and functions you want to use.
The database nodes are also SQL dialect independent, making you independent of your big data platform choice.
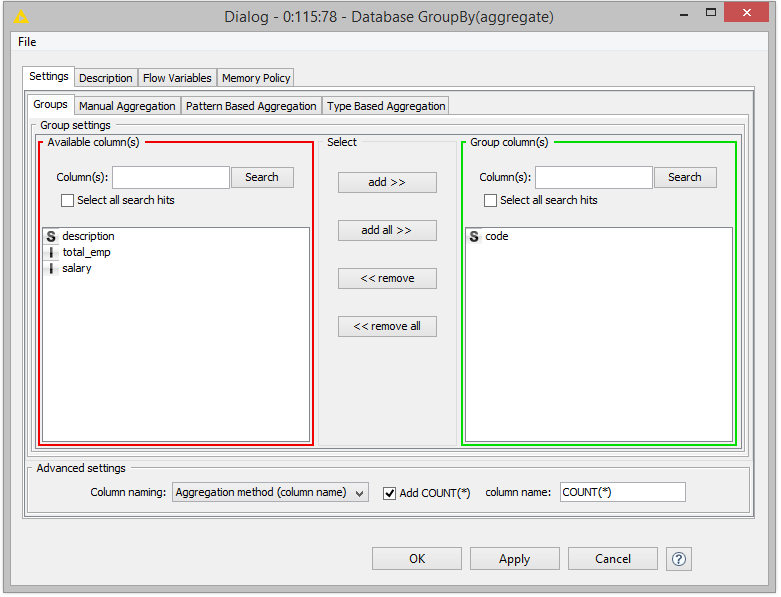
The Groups tab of the Database GroupBy dialog where you can specify the columns to group by e.g. code.
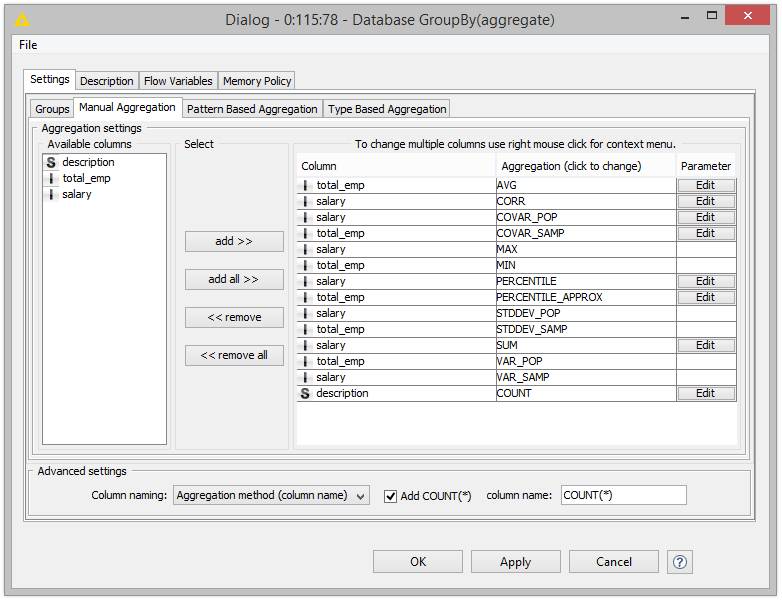
The Aggregation tab of the Database GroupBy dialog where you can specify the aggregation columns and functions.
Results
The SQL query that is visually assembled in the “SQL Generation” Meta Node (see Fig. 2) is executed in the Database Connection Table Reader node. Prior to execution, the execution engine you want to use is defined in the Database SQL Executor by executing the “set hive.execution.engine=\$\${Sengine}\$\$” statement whereby \$\${Sengine}\$\$ is replaced by the engine you want to use, e.g. mr or tez. In addition to the execution engine, we also compared the performance of the standard data format with the Optimized Row Columnar (ORC) data format. Each query is executed 15 times for each execution engine and each data format to prevent artefacts.
The average runtime for each execution engine and data format is depicted in Fig. 5. Even with this small dataset the difference between the MapReduce and TEZ execution engine is striking. The Tez based execution engine is more than four times faster than the MapReduce execution engine. The difference between the new ORC file format and the standard format is negligible. The reason for this might be that the generated query accesses almost all rows and columns in the data set.
Mean execution time in seconds for the different execution engines and file formats.
The line chart in Fig. 6 depicts the individual execution time in seconds for each of the 15 iterations. The execution time of both engines remains relatively stable throughout the iterations.
Line chart showing iteration on the x-axis and execution time on the y axis.
Summary
This blog compared the Hive standard execution engine based on MapReduce with the new Tez based execution engine. The results demonstrate that for this experimental setup the Tez based execution engine is more than four times faster than the standard execution engine based on MapReduce. However, the result has to be taken with a pinch of salt, since the workflow only executes a single SQL statement on a very small data set. It also demonstrates how easy it is to assemble complex SQL queries and benchmarking flows within KNIME Analytics Platform.
Requirements:
- KNIME Analytics Platform
- KNIME Big Data Extension (contact contact@knime.org for an evaluation licence)
- Hortonworks Sandbox or Hortonworks Data Platform (2.1 or 2.2)
The KNIME workflow is available for download on the KNIME Example Server at 017_BigData/017010_Tez_vs_MapReduce.