As an instructor, you’ll know just how much exercises contribute to a student’s understanding of a topic. But coming up with an instructive and interesting exercise is difficult. The concepts your students are learning vary, they require different kinds of datasets, and the datasets need to be simple enough to allow the student to focus on the task at hand.
For our own self-paced machine learning course, we came up with a novel solution. Instead of searching, filtering, and transforming real-world datasets, we are generating synthetic datasets. Using these synthetic datasets it is easier to design hands-on exercises for our students to test their knowledge of machine learning algorithms.
How can synthetic data help you teach machine learning?
Using synthetic data instead of real-world data as a base for practical exercises gives us the following benefits:
No excessive volume of exercise data
Real-world datasets contain all the types of properties students need to learn about in order to apply the best techniques to deal with them – redundant features, duplicate features, linearly correlated features, and so on. But they might be too large to share and redundant to carry through all exercises of your course.
With synthetically generated datasets, we can work with compact data that only contains the required number of columns and rows. And we can always rename the columns and create a story around the generated data if we want to make the exercises more engaging.
Customize the features of the dataset
Many popular datasets for machine learning exercises, such as the adult dataset, are able to demonstrate one algorithm, the decision tree for example, but lack features to demonstrate other algorithms, the linear regression for example.
With synthetic data, we can construct the features just as we need, allowing us to demonstrate each algorithm effectively.
Generate characteristics that are implicit in real-world data
Some characteristics of the data affect how the algorithms perform. At the same time, they are difficult to find in real-world data. For example, knowing whether the classes are linearly separable in the feature space and finding a dataset to demonstrate that might require excessive data exploration. However, this characteristic makes a difference in the performance of two classification algorithms: the logistic regression and the decision tree.
When we generate synthetic data, we can ensure that the characteristics of the data enable our students to learn to consider which algorithm will perform best.
Generate synthetic data with KNIME verified components
As an example, we’d like to show you four KNIME verified components that teachers can use to generate synthetic data and demonstrate classification tasks.
Each component’s functionality is based on functions in the Python scikit-learn library, yet all the settings for the data generation are defined in the component’s configuration dialog. If you are using the KNIME Python integration for the first time, please follow the instructions at the end of this article to enable the execution of a Python code under the hood of your visual workflows.
Let’s see how to use the Synthetic Data Generator (Classification) component and generate data for classification. With this data we’ll be able to demonstrate that the logistic regression and decision tree algorithms perform differently.
In our L4-ML course, we teach students that the decision tree algorithm performs better if the decision boundary is non-linear (left side in figure 3 below), whereas the logistic regression algorithm performs better if the decision boundary is linear (right side in the figure below).
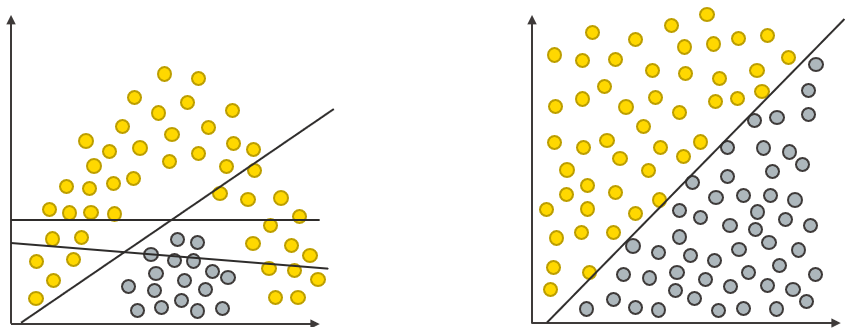
We want to replicate the scenario illustrated in Figure 1 in synthetic data. We can do so by regulating the class separation parameter in the Synthetic Data Generator (Classification) component. Figure 2 below shows the result:
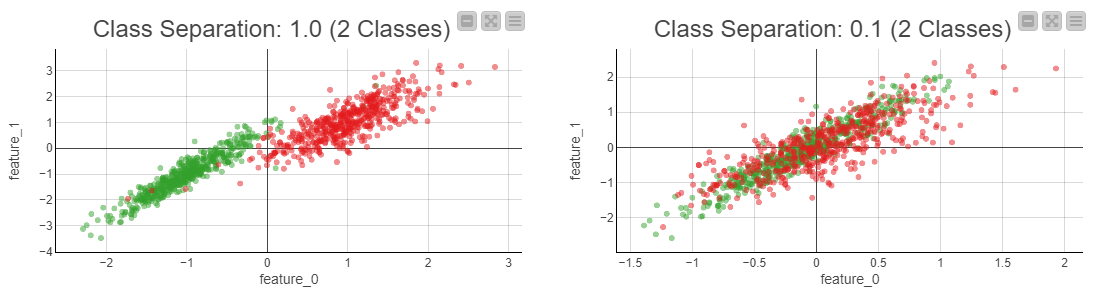
The scatter plot on the left shows the desired output, data with linear class separation. For a reference, the scatter plot on the right shows data with no linear class separation. If you want to compare how the linear regression and decision tree algorithms perform on this generated data, try out the corresponding exercise workflow of the course.
The Class Separation parameter and other settings of the component appear in its configuration dialog shown below:
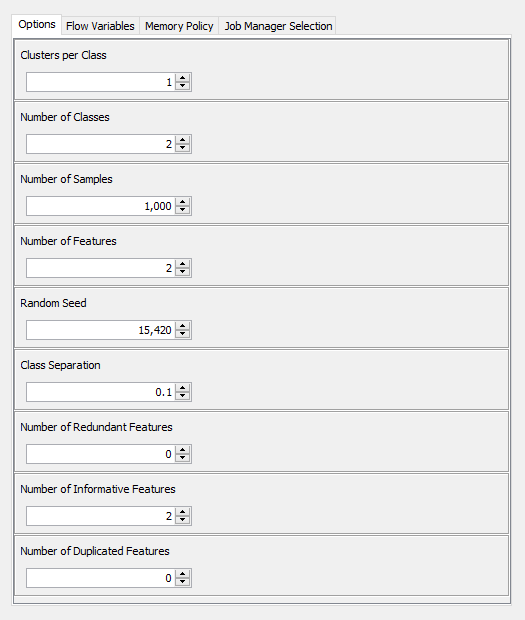
In the configuration dialog, you can control how many features and samples to generate, how many features are informative/redundant, and how many are duplicates. Besides, you can assign the classes into one or more clusters. As an example, Figure 4 below visualizes two kinds of clustering:
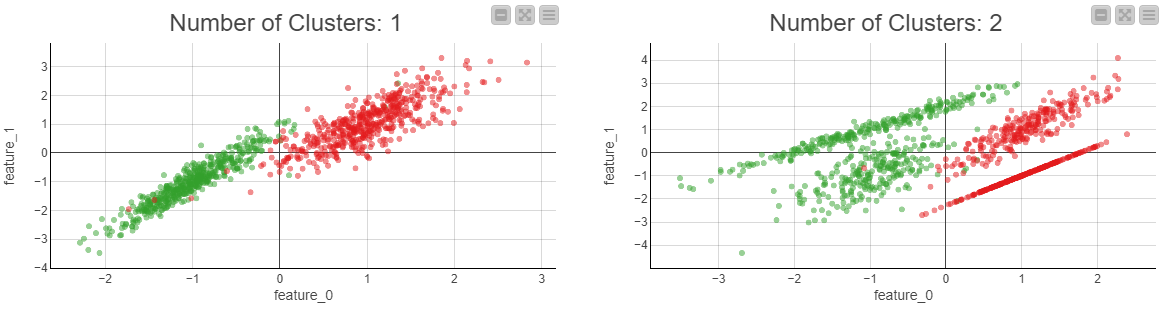
On the left, you can see that the green and red classes are not distributed into separate clusters. On the right, you can see two clusters within both classes.
Finally, it is also possible to regulate the seed parameter to make the data reproducible in repeated executions of the component.
Get started with KNIME data generation components
In the same way, by following the steps introduced above, you can generate data for a multinomial classification problem, regression problem, or multilabel classification problem.
Follow these steps to get started:
1. Configure Python in KNIME
-
Install Miniconda from https://docs.conda.io/en/latest/miniconda.html
-
Install the KNIME Python Integration
-
Configure KNIME Preferences under File > Preferences > Python and browse to your Miniconda Installation Directory under Conda
For details, you can consult the KNIME Python Integration Guide.
2. Download Franziska’s example workflow demonstrating the functionality of all components is available on the KNIME Hub (available at https://kni.me/w/7hWbEYwXtU6bJ-us) and shown below:
3. Inspect and re-configure the components as you like!
Synthetic data generation for clear demonstration of ML operations
Demonstrating machine learning tasks in practice for teaching purposes is a challenge. Different algorithms require different properties of the data; introducing them all at once expands the exercise data into unwieldy dimensions.
Our solution is to generate synthetic data for classification, regression, multilabel classification, and clustering with the KNIME Verified Components. These components generate the data you need fast, in a compact size, and with the properties you’d like to demonstrate.