
If you are a KNIME Server customer you probably noticed that the changelog file for the KNIME Server 4.5 release was rather short compared to the one in previous releases. This means by no means that we were lazy! Together with introducing new features and improving existing features, we also started working on the next generation of KNIME Servers. You can see a preview of what is there to come in the so-called distributed executors. In this article I will explain what a distributed executor is and how it can be useful to you. I will also provide some technical details for the geeks among you and finally I will give you a rough timeline for the distributed executors' final release.
State of the KNIME Server
Currently the installation of a KNIME Server is straight-forward because all components reside on the same physical machine. These components are: the workflow repository; the executor, which runs workflow jobs; and the server itself, which provides the interface to the outside world (via WebPortal, REST, or EJBs for access from the KNIME Analytics Platform). The figure 1 shows this setup.
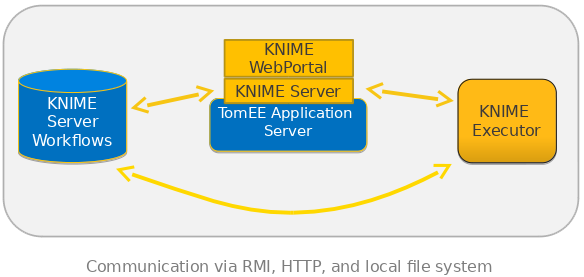
Having all components on the same machine has the main advantage that communication between them is fast and reliable. The downside though is - obviously - scalability. Depending on the workflows that you have created and on the amounts of data you are processing, the single executor on a single physical machine can become a bottleneck. Of course you could use a bigger machine, but there are clear limits to this approach. Therefore we decided to introduce the distributed executors!
Scale me!
The general concept of distributed executors is easy to understand: you run multiple executors on independent hardware. If the existing executors are all busy executing jobs and cannot accept new jobs you simply add more executors that handle the waiting jobs. The figure 2 shows this general idea.
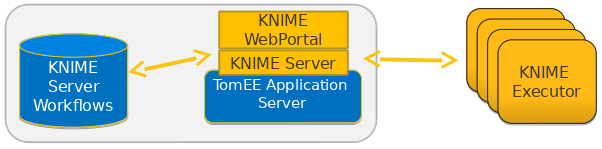
Technically this setup becomes much more challenging. First of all, you cannot use the file system any more to exchange information (mainly workflows) between the server and the executors. This means all communication must be performed via a network, ideally using some standard protocol, such as HTTP. The existing REST interface already available in the KNIME Server is then a natural candidate. Indeed, in the designed architecture, the distributed executors rely heavily on it.
However, using only HTTP for communcation would require the server to know exactly which executors are available and where to reach them at each moment. The server would also need to queue requests in case no free executor is available. Since this is a common problem to many applications, some solutions are already available, one of which is the so-called "message queue". The concept of a message queue is quite simple: a sender puts a message in the queue and the system ensures that it is distributed to the right recipients (think of it as a post office).
Roger Rabbit
One of such message queueing systems is RabbitMQ. Although it is written in the rather exotic programming language Erlang, it's straight-forward to install and manage (and also fast for that matter). It can run on the same system as the KNIME Server or on any other system that is reachable by both the server and the executors. Then you have to tell both parties where to find the queue, and that's it. Setup of queues itself is done by the application. There is no configuration required in RabbitMQ.
Let's have a closer look at what happens if a user wants to execute a workflow on the server using the distributed executors.
- First the server receives the request (from either of the available interfaces) and then creates a message saying that workflow X should be loaded for user Y. This message is sent to RabbitMQ.
- This message is now forwarded to one of the executors. This executor then can decide whether to accept the message or not. Reasons for rejection could be too much load on the executor or missing capabilities for the job. If the message is rejected, it is offered to the next executor in a round-robin fashion.
- If an executor has accepted the message, it loads the workflow, acknowledges the load message, and finally sends back a status message to the server via RabbitMQ.
- This last message is processed by a dedicated queue for this job only, so that messages belonging to a particular job are not distributed to all executors. If the executor would have died between accepting the message and acknowledging it, the message would be put back in the queue and distributed to another executor.
If an executor requires data from the server, e.g. the workflow itself or data files required by a workflow job, then the REST interface is used. The message to load a workflow also contains the server's address; therefore the executor knows from where to get the data. The main reason for this split between message queue and REST is that message queueing systems are optimized for small messages, while workflows or data files can in principle be quite large. The figure 3 shows a sketch for the final setup.
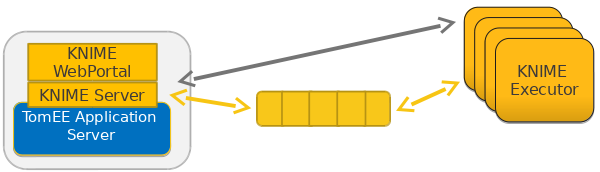
Try it!
Since the changes required to decouple the executors from the server are rather large, we are not finished yet with implementing this new generation of KNIME Servers. However, a large part of the distributed executor functionality is already available. Since quite some customers are interested, we have prepared a preview of the KNIME Server 5 that you can already try now!
If you are an existing customer, go to the commercial products download page for the 2017-07 release. Under the downloads section for KNIME Server 4.5, you will find the links to the downloads and documentation for the KNIME Server 5 preview. The documentation also contains a list with available and still missing functionalities. If you are not a KNIME Server user yet but are interested in trying out the distributed executors, just contact us.
See the latest information about KNIME Server for productionizing data science applications and services.