
This is going to be a bit different from our normal KNIME blog posts: instead of focusing on some interesting way of using KNIME or describing an example of doing data blending, I’m going to provide a personal perspective on why I think it’s useful to combine two particular tools: KNIME and Python. This came about because I keep getting questions like: “But you know Python really well, why would you use KNIME?” or “Now that you work at KNIME you aren’t really using Python anymore, right?”.
When to use one or the other?
So should you use Python or should you use KNIME?
Fortunately you don’t need to make this hard choice; it’s perfectly straightforward and, I think, quite productive to use both. It’s easy to take advantage of either tool from the other. I’ll spend most of the rest of this post looking at that. But there are areas where I think one tool or the other particularly shines.
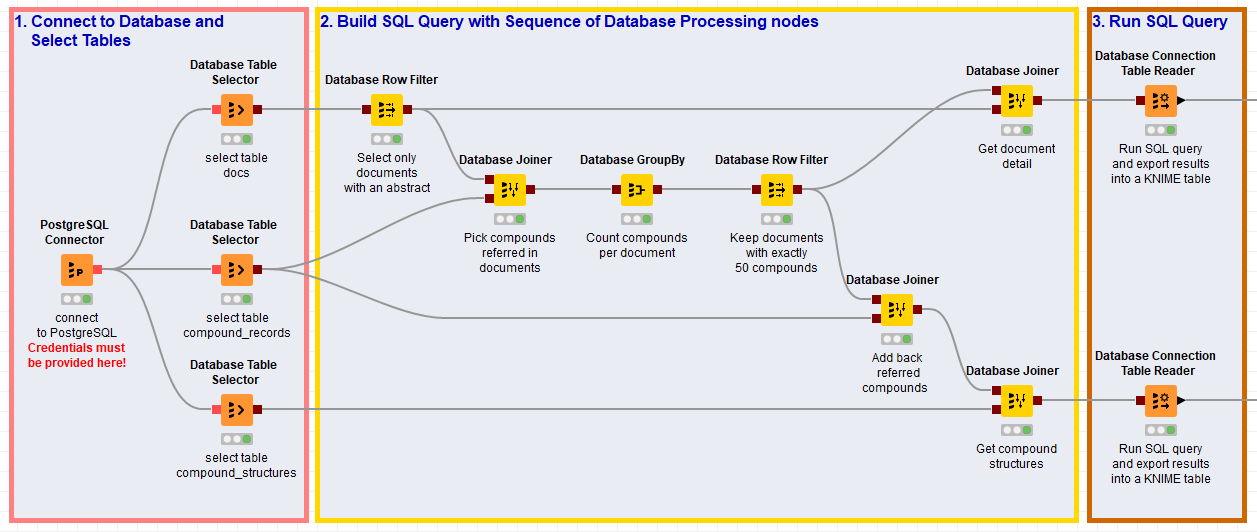
A good example of this is working with databases. I find that using an interactive tool like KNIME makes building complex queries a lot easier. Being able to browse the database structure and get previews of what a partial query will return is super helpful. As a concrete example, Figure 1 shows the bit of a workflow I recently built to pull a dataset from a large database1. Though I could have manually constructed the queries built by this bit of workflow, why would I?
Figure 1. Piece of a sample KNIME workflow that builds a complex SQL query
Using Python from KNIME
There are a number of nodes available that make it easy to use Python from inside KNIME Analytics Platform. I’ve previously blogged about configuring KNIME to use the Python nodes. Using them is straightforward: most of the time you’ll be using one of the Python Scripting nodes and these provide you the data from KNIME as a Pandas DataFrame and expect you to provide your results also as a Pandas DataFrame. It’s super easy and it allows me to use the standard Python data science stack.
I tend to use the Python nodes for things like:
- Complex data transformations that there aren’t currently KNIME nodes for
- Prototyping and experimenting with new computational methods
- Taking advantage of the machine-learning tools available in scikit-learn (these complement KNIME’s built-in capabilities quite nicely)
These are all things that certainly could be done from within KNIME itself, particularly if one were to either make heavy use of the Java Snippet node or write custom nodes, but I’m not that much of a Java programmer, so I really appreciate being able to use Python for this.
A real benefit of using Python inside of KNIME is that when I save the executed workflow, I have the input data, my code, and the results all together in one package. It’s easy for me to archive this or move it from machine to machine and reproduce or expand upon what I’ve done.
Using KNIME from Python
Ok, that was the more familiar case of using Python from within KNIME Analytics Platform. Suppose I want to go the other way and use a KNIME workflow that I’ve created from inside the Jupyter notebook or a Python script. How would that work?
One way to do to this is to use a local copy of KNIME in batch mode. Since we have a FAQ for that I’m not going to cover it here and I’ll focus instead on using a workflow that’s been uploaded to the KNIME Server as a web service. I’ve previously blogged about how easy it is to create these services. Now I want to use one from my Python code. The excellent requests package makes it super easy to call a web service on the KNIME server from Python:
Figure 2. Example of calling a web service on the KNIME Server from Python
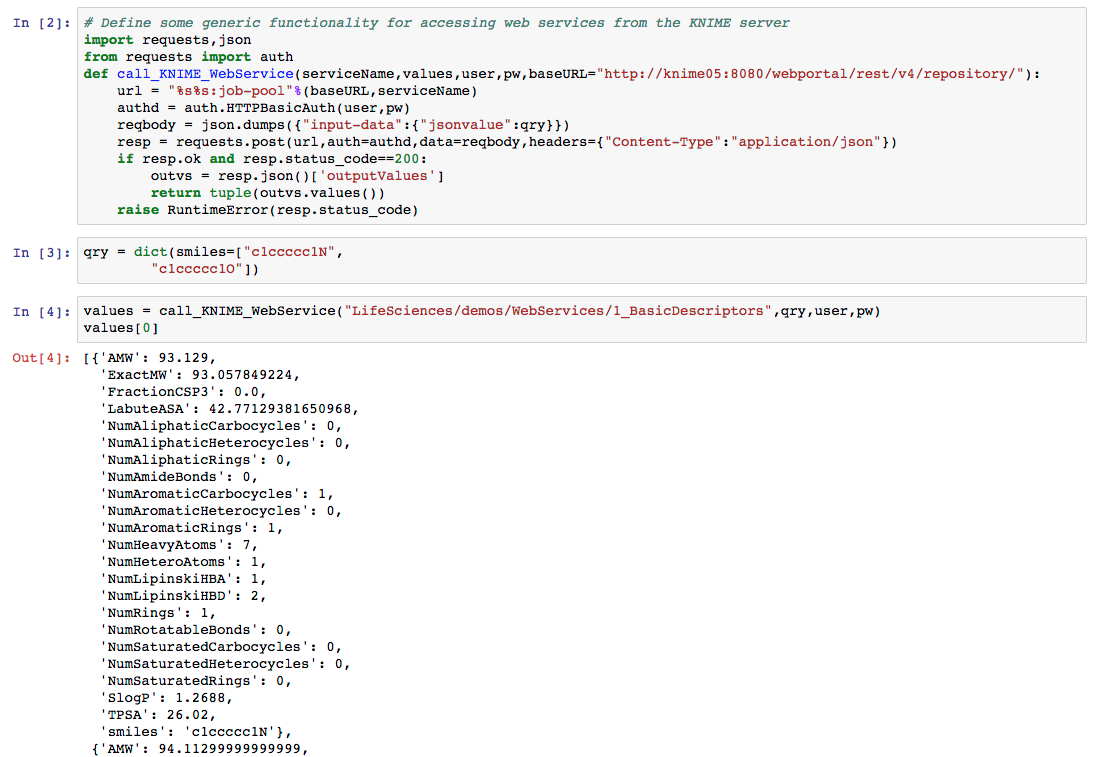
The key function call_KNIME_WebService() is available as a gist.
What’s going here is relatively simple: I construct a Python dictionary that has the parameters I want to send to the web service call. I pass that dictionary, together with my server username and password along to call_KNIME_WebService(). That function takes care of the details of POSTing the REST call to the server and processing the results and then returns the results to me as a Python object.
Using this basic pattern I can use any workflow deployed as a web service on our KNIME Server. It’s really nice to be able to take advantage of the work that KNIME-using colleagues have done from my Python scripts.
Wrapping up
You don’t have to choose between KNIME and Python. In this post I showed a couple of ways in which KNIME Analytics Platform and Python can be used together and provided a bit of personal perspective on why you might want to do that. I hope it was helpful!
1For those who care about such things, this is a search of the ChEMBL_23 database. The top query grabs information about documents that have abstracts and contain at least 50 unique compound entries. Information about documents and compounds is stored in separate tables. The bottom query grabs the information about all of the compound structure records found in those documents. Here a third table, containing the compound structure records, must also be used in the query. [back]