
Identifying fraud, diagnosing a rare disease, predicting customer churn with machine learning— are all difficult because you need to identify the outlier: the fraudulent credit card purchase, the rare disease, the customer who churns. They are challenging to predict correctly due to the lack of examples: Most credit card transactions are normal. Only a few are fraudulent. This uneven mix is known as class imbalance.
In most real-world datasets, one class appears much more often than the other. Class imbalance can lead to misleading model performance and poor predictions—especially for the less frequent class. Class imbalance is a common challenge in machine learning and predictive modeling.
This article discusses the methods you can use to overcome the challenges of imbalanced data. We also show you how you can apply these methods in the open source KNIME Analytics Platform.
A case in point: A clinical decision support system
Clinical decision support systems provide healthcare professionals with information to enhance their decision-making and improve patient care.
The challenges associated with imbalanced data are particularly evident when developing clinical decision support systems. That’s because instances of rare diseases typically make up a very small percentage of the total patient population. This makes the dataset extremely imbalanced.
For example, in a previous study, we built a clinical decision support system for diagnosing diabetic retinopathy using a limited set of diabetes test results and demographic information from the electronic health records (EHR database).
In this dataset of several hundred thousand diabetic patients, only about 5% had diabetic retinopathy. The remaining 95% did not (See Piri et al., 2017 A data analytics approach to building a clinical decision support system for diabetic retinopathy: Developing and deploying a model ensemble).
What to do when a high accuracy turns out to be fool’s gold?
We encountered another imbalanced data problem in an educational decision support system aimed at predicting student dropout.
The main aim of this system was to identify, explain, and mitigate freshmen student attrition at a higher education institution (Thammasiri et al., 2014 A critical assessment of imbalanced class distribution problem: The case of predicting freshmen student attrition). The dataset for this project contained four times as many students who stayed enrolled compared to those who dropped out .
The graphic below shows the data imbalance we saw as we developed this system (Thammasiri et al., 2014).
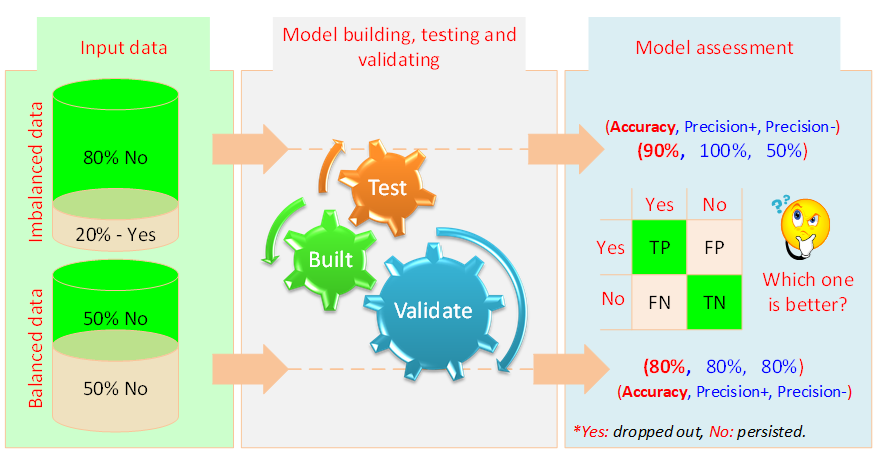
Observations after assessing the model
As you can see in the right side of the graphic, the imbalanced dataset was highly accurate at predicting the majority class, but performed poorly for the minority class. In contrast, when we rebalanced the data, performance for both classes improved significantly.
Although the overall accuracy in the imbalanced dataset appears to be scientifically higher, this is misleading—a concept often described as “fool’s gold” in data mining literature.
In conclusion, we can say that:
- Balanced datasets enable machine learning techniques to yield reasonably high prediction accuracy for both minority and majority classes.
- Imbalanced datasets can cause machine learning models to make poor predictions.
Why do imbalanced datasets cause ML models to make poor predictions?
This happens because machine learning algorithms learn from training data in a way that's similar to how people learn from experience.
In humans (and likely in many animals), memory is influenced by repetition—experiences we see often create more permanent, vivid memories. That makes them easier to remember and recognize later. Rare experiences, on the other hand, may be overlooked or ignored.
In the same way, in machine learning, the learning process can result in biased predictive models, because it’s focused primarily on patterns from the majority class, while neglecting the specifics of the minority class.
Which methods help overcome the imbalanced data problem?
There are several ways to deal with imbalanced data and help predictive models perform better. Here we want to look at four.
The graphic below (from Predictive Analytics: Data Mining, Machine Learning and Data Science for Practitioners, Delen, 2021) shows a simple overview of these methods.
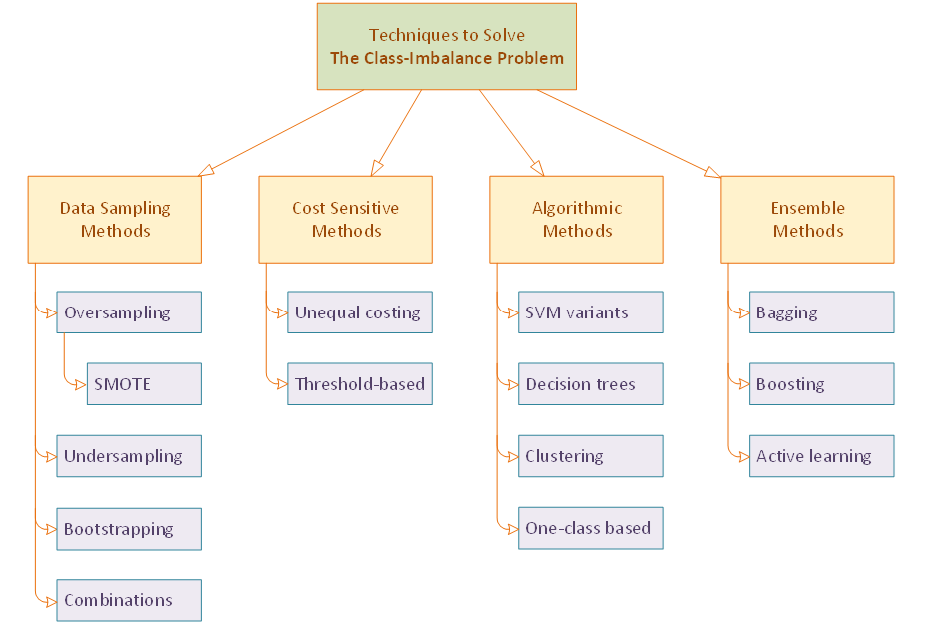
While some approaches are more complex than others, they all aim to ensure that the prediction algorithm pays equal attention to the patterns presented by all classes—majority, minority, and everything in between.
Some methods work by changing the distribution of classes in the training data, while others adjust the learning process, by modifying the algorithm or changing the importance (or cost) of mistakes, to prioritize accurate prediction of the minority class. (See cost-sensitive methods below.)
Note: Cost of performance refers to the consequences assigned to different types of prediction errors. In an imbalanced dataset, misclassifying a rare event (like disease or fraud) can be more serious than misclassifying a common event.
Let’s have a look at these methods in more detail. We’ll also point out which functionality you can use in the open source KNIME Analytics Platform to use these methods in your visual workflows.
#1. Data sampling methods
Data sampling methods are among the most widely used techniques in data science and machine learning due to their simplicity in understanding, formulation, and implementation.
These methods can be categorized into two main classes: oversampling and undersampling.
Oversampling methods
Oversampling methods increase the number of minority class examples in two main ways:
- By replicating existing examples until the number is equal to the majority class. This can be done by simply copying the data or through bootstrapping techniques.
- By synthetically generating new examples that are similar but not identical to the existing minority class samples.
One well-known technique is SMOTE (Synthetic Minority Oversampling Technique), which uses the k-nearest neighbor algorithm to generate new examples.
SMOTE works well with datasets that primarily consist of numerical features. But it doesn’t perform as well when the dataset has mostly categorical or nominal variables. Various variants of the SMOTE algorithm have been developed to address the shortcomings of the original method.
Undersampling methods
Undersampling methods keep all the minority class examples and randomly select an equal number of examples from the majority class. This means some of the majority class examples are removed from the training data.
The random selection can be done with replacement (where the same example might be picked more than once, known as bootstrapping) or without replacement (where each example is only picked once).
In KNIME Analytics Platform, you can use the Equal Size Sampling node to implement undersampling (A).
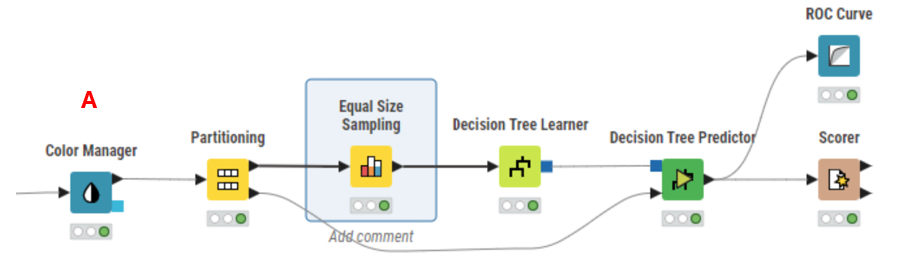
You can use the SMOTE node for oversampling techniques (B). Additionally, random row selection methods can be employed to create a hybrid sampling approach.
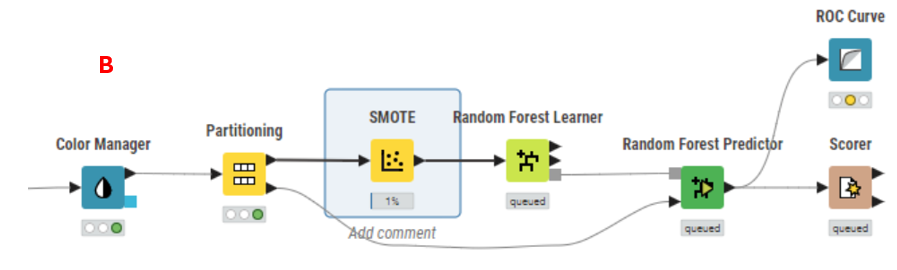
#2. Cost-sensitive methods
One way to handle class imbalance is by focusing on the cost of making mistakes – the cost of misclassifications.
While data sampling methods try to balance the dataset before the training process, cost-sensitive methods change how the model treats different types of classification errors, by adjusting the costs.
Cost-sensitive methods assign different misclassification costs to various classes based on the degree of imbalance. For example, they assign higher costs to misclassification errors involving the minority class, since those errors are often more important.
The goal is to either adjust the classification threshold or assign disproportionate costs to enhance the model's focus on the minority class. See more in How to optimize the classification threshold”.
#3. Algorithmic and one-class methods
Another group of methods used to handle imbalanced data involves algorithmic adjustments to different classification algorithms. These are known as algorithmic methods.
While all of these adjusted algorithms aim to reduce the negative impact of imbalanced data, they use different techniques to do so.
One of the most well-studied approaches in this area is support vector machines (SVMs) and their variants. For example, in our recent research, we developed a novel synthetic informative minority oversampling (SIMO) algorithm. It uses SVMs to improve learning from imbalanced datasets by creating synthetic examples of the minority class near the support vectors—areas that are hard to classify in the multi-dimensional feature space (Piri et al.2018, A synthetic informative mintory over-sampling (SIMO) algorithm leveraging support vector machines to enhance learning from imbalance datasets).
The one-class method is another technique used in the machine learning community to tackle class imbalance. The core idea is to focus on just one class at a time during training.
In this approach, the training samples consist solely of a single class label (e.g. only positive or only negative samples) so that it can learn the specific characteristics of that class.
Unlike traditional classification methods which differentiate between multiple classes, this approach is called “recognition-based,” while traditional methods are “discrimination-based.”
The goal with one-class methods is to create a model that is finely tuned to the characteristics of one class and can identify anything else as not belonging to that class.
This method uses three types of unification strategies:
- density-based characterization
- boundary determination, and
- reconstruction or evolution-based modeling.
These strategies are similar in concept to clustering techniques like k-means, k-medoids, k-centers, and self-organizing maps.
#4. Ensemble methods
Ensemble methods have recently emerged as a popular and effective way to handle imbalanced data.
Unlike single prediction models, ensemble methods combine the predictions of multiple models. These can be the same type of model (called homogeneous ensembles) or different types (called heterogeneous ensembles).
Variants of both bagging and boosting have been proposed to deal with class imbalance issues.
- In bagging, the data is sampled in a way that gives more attention to the minority class.
- In boosting, the model increases the weight of minority class examples to help improve their prediction.
Another approach being explored as a potential solution to the class imbalance problem is active learning. Active learning is a methodology that learns iteratively in a piecewise manner. It focuses on the most useful data at each stage to better handle class imbalance.
Looking ahead: The ongoing search for better solutions
Despite numerous efforts to overcome the class imbalance issue in the machine learning community, the current state-of-the-art approaches are limited to heuristic solutions and ad hoc methodologies.
There is still a lack of universally accepted theories, methodologies, and best practices. While many studies claim to have developed data balancing methods that improve prediction accuracy for the minority class, a significant number of them also conclude that these methodologies may degrade prediction accuracy for the majority class and overall classification accuracy.
Ongoing research seeks to address questions such as, "Can a universal methodology yield better prediction results?" or "Can there be an algorithm that prescribes the best data balancing technique for a specific machine learning approach and the data available?"