What is ETL?
ETL – Extract, Transform and Load – is the data integration process to access and transform data from multiple sources into an intermediate storage before loading it into a data warehouse or database for further analysis.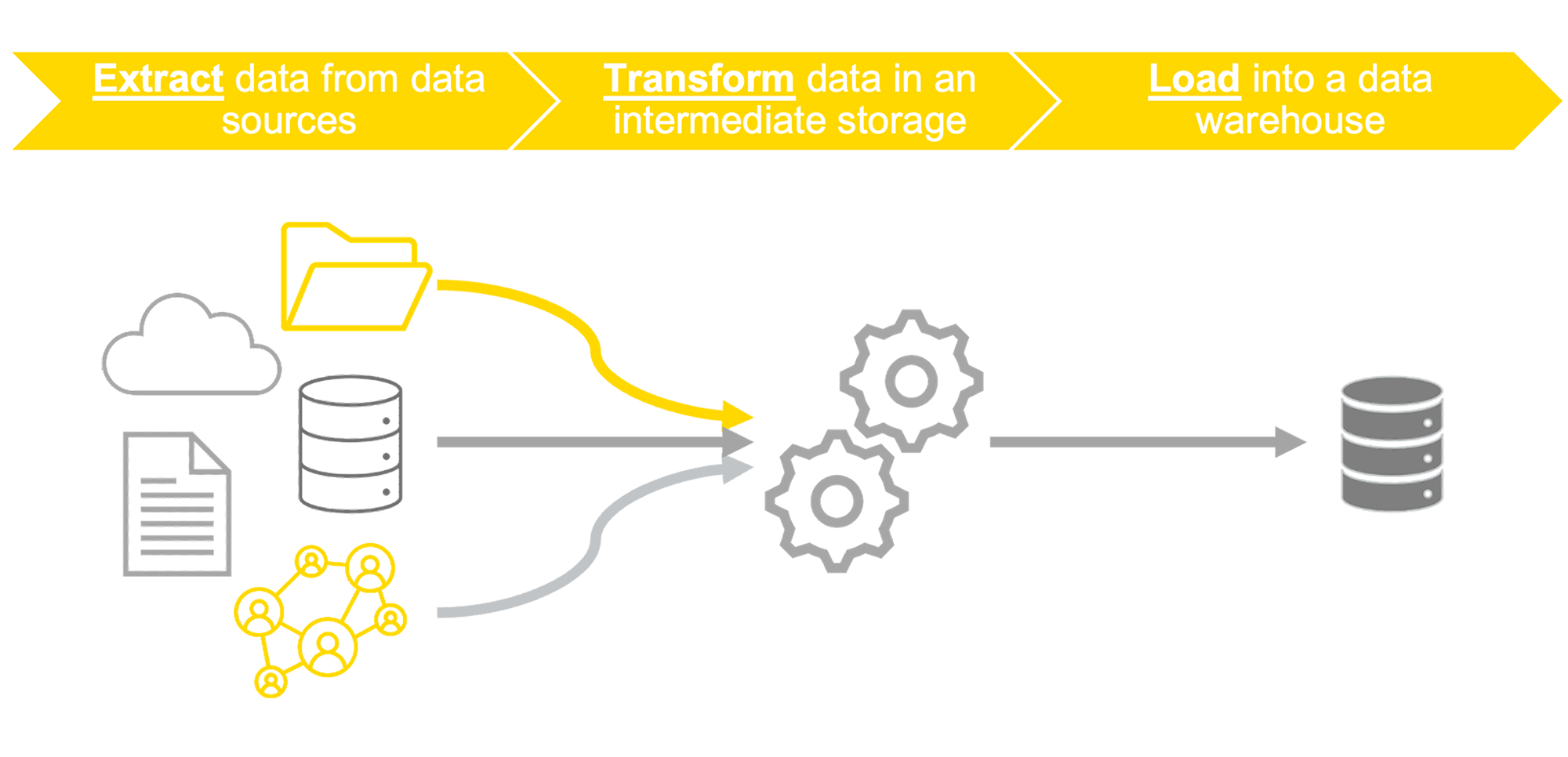
What is ELT?
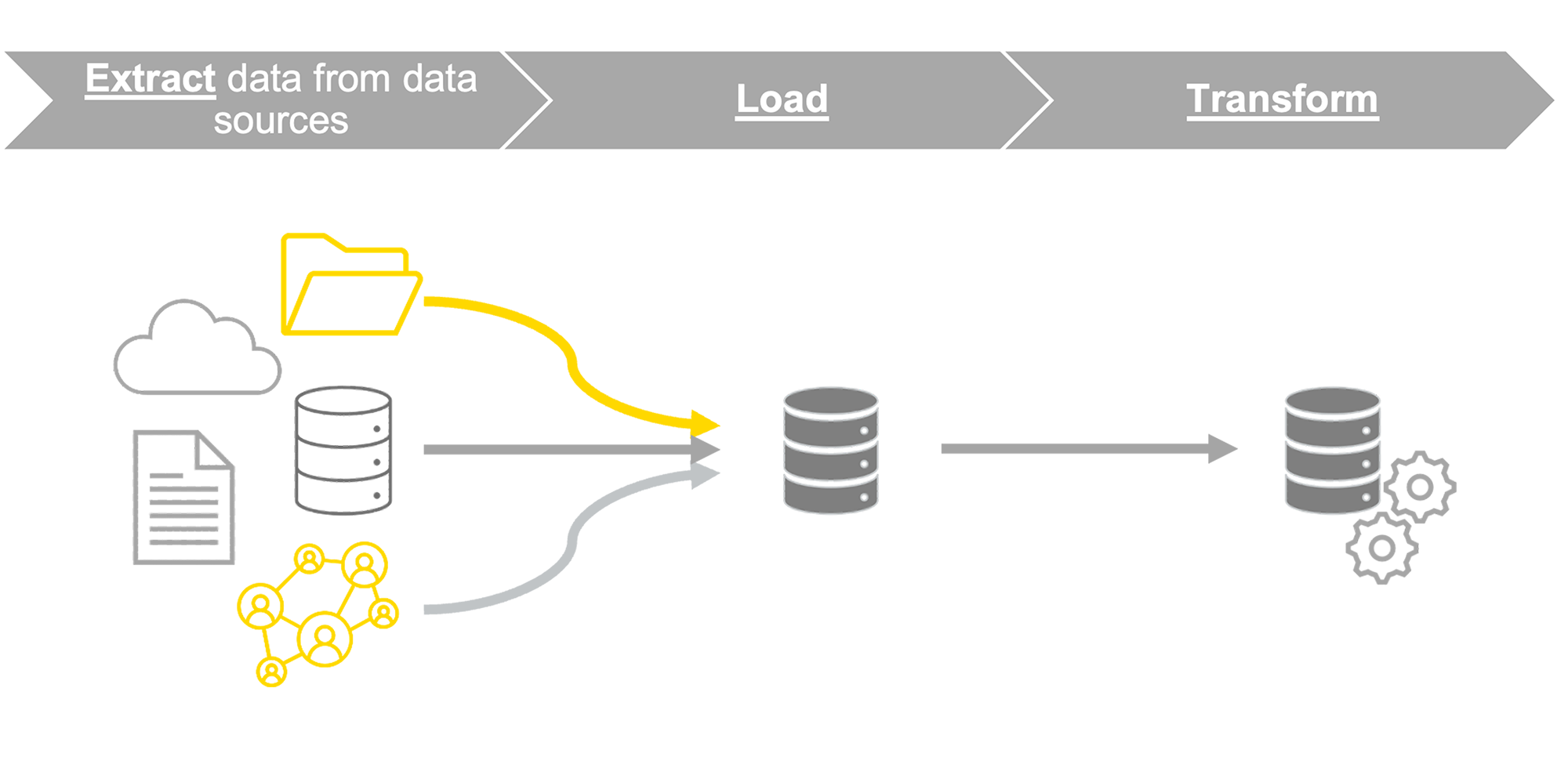
ELT – Extract, Load, and Transform – is a variation of the ETL process. Here data is extracted from multiple sources and loaded into a data storage. The data is then transformed near the time of analysis.
Why Are ETL and ELT Important?
In our interconnected digital world, business and data analysts need solutions to provide quick insights to answer complex business questions. To create business reports for customers or do ad-hoc analysis, they need to access and integrate data from multiple sources. Depending on IT to provide the right data can delay the time to insights.
ETL tools that enable accessing, transforming, and preparing data in an efficient, self-service environment give business and data analysts the flexibility and the speed they need to analyze data independently of IT.
How Does ETL Work?
The ETL process accesses and extracts multiple disparate data types and sources. It’s important that companies have easy access to all the data in real-time to enable analysts to work with the freshest data. Next, the data is transformed into the required format for the business use. Here the data is validated, cleaned, and standardized before being blended and (if required) anonymized. Now, it can be loaded into a respective storage and is ready for further analysis.
The ETL/ELT process runs repeatedly, automatically, and error-free to ensure analysts get the freshest, most reliable data for their analysis.
How Does KNIME Help With ETL?
An efficient and future-proof ETL process enables analysts to get quicker and reliable insight into their data. The free and open-source KNIME Analytics Platform ensures the ETL process is powerful, scalable, repeatable, and reusable.
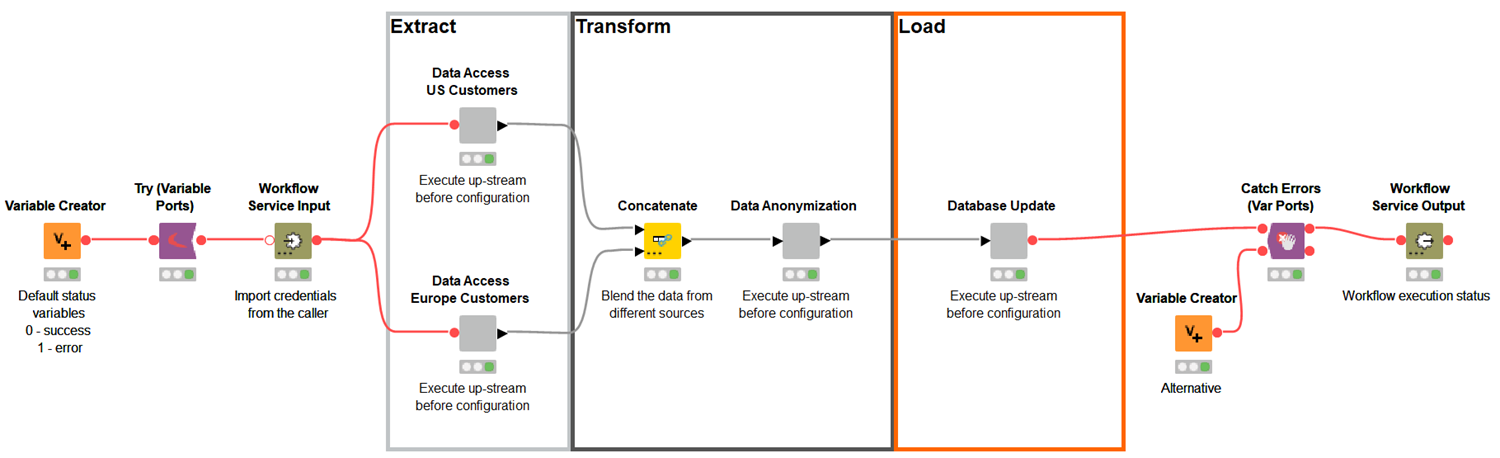
Extract Data With KNIME.
Powerful file handling: Data workers can spend more time on the analysis with KNIME’s flexible and powerful file handling for fast processing of data, no limits on the amount, almost no limits in formats. Access multiple disparate data sources via dedicated database, web and cloud services connectors. Read more about File Access and Transformation.
Transform Data With KNIME.
Mix and match processing: Analysts can blend, validate, authenticate, and anonymize data within KNIME, in-database, or in the cloud.
- Read/write tabular, structured, textual, chemical data, audio, image, and model files
- Integrate Python, R, H2O, and more
- Transform data before reading into KNIME
- Read from/write to local and remote file systems
- Send data directly to PowerBI, Tableau
- Manage files and folders within one or several local or remote file systems
Load Data With KNIME.
Connectors to target destinations: Teams can update databases with dedicated database writer, connector, and utility operations, or load data to a big data platform with KNIME’s Big Data connectors and perform IO and in-database processing, e.g. in Hadoop, Hive, Impala, Amazon S3, Google BigQuery, Databricks; even train machine learning models in Spark.
Establish Scalable, Repeatable, Reusable ETL Processes.
In KNIME, logic blocks and repeatable processes can be written once and reused by wrapping the process into a component. For example, components could consist of a company’s standardized ETL clean-up operations, or standardized logging operations, or model API interfaces. Wrapped into a component they can be shared within the enterprise and reused.