
Today: XML meets JSON

The Challenge
Do you remember the first post of this series? Yes, the one about blending news headlines from IBM Watson News and Google News services about Barack Obama? Blending the news headlines involved a little side blending – i.e. blending JSON structured data – the response of Google News – with XML structured data – the response from IBM Watson News.
Today, the challenge is to parse and blend XML structured data with JSON structured data. Recycling part of the original blog post workflow, we query IBM Watson AlchemyAPI News service for the first 100 news headlines on Barack Obama and the first 100 news headlines on Michelle Obama. We want the response for Barack Obama to be received in XML format and the response for Michelle Obama in JSON format. Two data sets: one for Barack Obama (XML) and one for Michelle Obama (JSON). Will they blend?
Topic. News Headlines on Barack Obama and separately on Michelle Obama from October 2016.
Challenge. Blend the two data response data sets respectively in XML and JSON format.
Access Mode. JSON and XML parsing for IBM Watson AlchemyAPI News REST service response.
The Experiment
- We build a request for the IBM Watson AlchemyAPI REST service GetNews, as described in the previous post https://www.knime.org/blog/IBM-Watson-meets-Google-API inserting the API Key, the topic, and the output format as parameters.
Notice that we encapsulated the whole REST service request part in two identical wrapped metanodes, both named “Querying IBM Watson”. The advantage of the wrapped metanode is that the Quickform parameters are shown in its configuration window. This means it is easy to change the topic in the metanode configuration window without needing to access the internal content of the wrapped metanode. The same parameters shown in the wrapped node configuration window are shown in a web browser through KNIME WebPortal. Finally, since the metanodes are identical except for the parameter values, they could actually be replaced with links to wrapped node templates located on some KNIME Server, making maintenance of the workflow and its metanodes much easier.
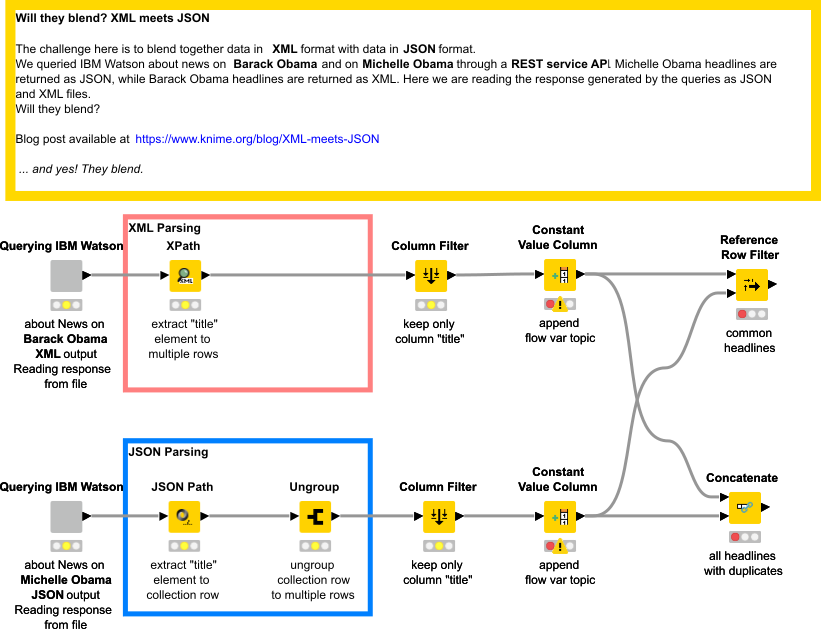
The output format is set to XML for Barack Obama and to JSON for Michelle Obama. - The XPath node uses the following query
/results/result/docs/element/source/enriched/url/title
to extract all news titles from the XML response. To process the array of news headlines properly, it is important to set the return type to String (Cell) and to allow for multiple rows in the Multiple Tag Options frame in the configuration window of the XPath node. - The JSON Path node uses the following query
\$['result']['docs'][*]['source']['enriched']['url']['title']
to extract all news headlines into a collection-type data cell. Since the XPath node does not have the “multiple rows” option, we use an Ungroup node to transform the collection cell into a number of separate data rows. - The experiment is practically finished with 100 headline titles in the upper branch for Barack and 100 in the lower branch for Michelle. We can now concatenate the results for further processing or we could, for example, extract the common headlines reporting about both Obamas.
The workflow that blends Barack’s XML-structured headlines and Michelle’s JSON-structured headlines in KNIME Analytics Platform is shown in figure 1. A version of this workflow reading IBM Watson responses from a file is available on the KNIME EXAMPLES server under 01_Data_Access/04_Structured_Data/03_XML_meets_JSON01_Data_Access/04_Structured_Data/03_XML_meets_JSON*.
The Results
Yes, they blend!
The experiment was run in November 8, 2016. 100 news headlines were extracted between October 22 and November 8 for each of the Obamas. At that time, the Obamas had only one common headline at the output of the Reference Row Filter node.
The workflow successfully blended XML-structured data for Barack with JSON-structured data for Michelle. Again, the most important conclusion is: Yes, they blend!
Coming Next…
If you enjoyed this, please share this generously and let us know your ideas for future blends.
We’re looking forward to the next challenge. There we will explore Shakespeare world and we will try to make peace between the families of Kindle epub documents and JPEG images. Will they blend?
* The link will open the workflow directly in KNIME Analytics Platform (requirements: Windows; KNIME Analytics Platform must be installed with the Installer version 3.2.0 or higher)