
Every Christmas, I bake my famous Christmas cookies. My recipes are well-kept secrets as I am painfully aware of the competition. There are recipes galore on the web nowadays. To make sure my cookies stay famous, I have to keep track of all the recipes on the web and their ingredients, particularly any ingredient I might have overlooked over the years.
My own recipes are stored securely in an MS Word document on my computer. One well-regarded web site for cookie recipes is http://www.handletheheat.com/peanut-butter-snickerdoodles/. I want to compare my own recipes with this one on the web and find out what makes them different. What is the secret ingredient for the ultimate Christmas cookie?
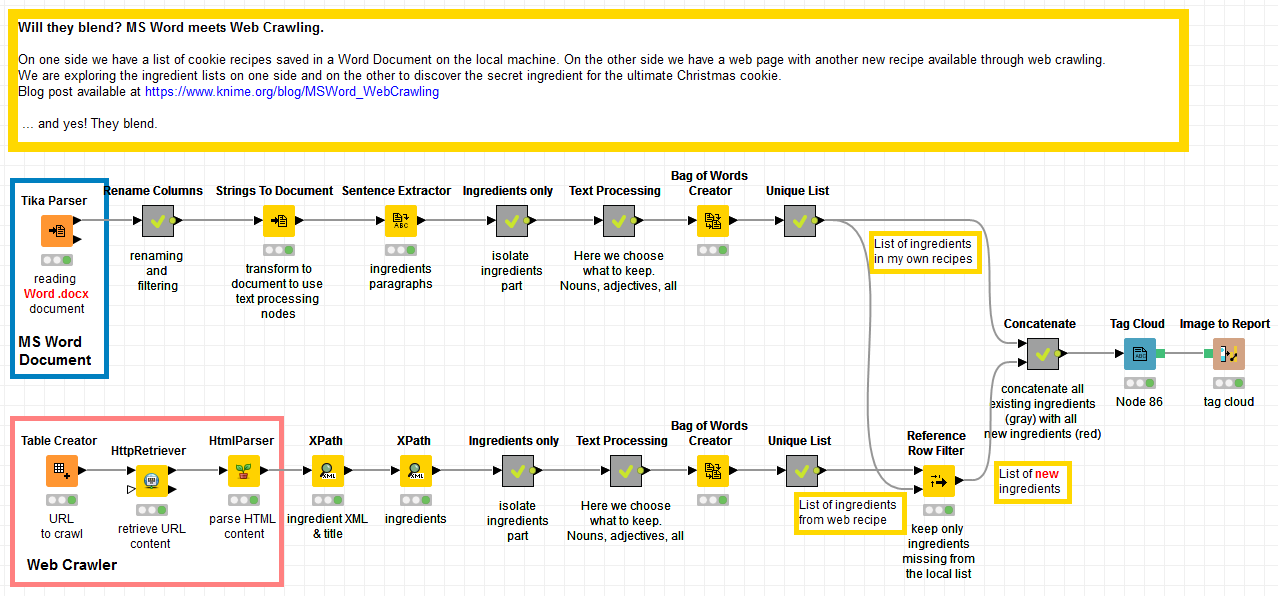
My Christmas cookie challenge is to identify secret ingredients in cookie recipes from the web by comparing them to my own recipes stored locally in an MS Word document. I want to use this example to show how you can read and parse my Word recipe texts and then use web crawling to read and parse this web-hosted recipe: all in KNIME.
Identify secret ingredients with text processing
The Text Processing Extension of KNIME Analytics Platform includes the Tika library with a Tika Parser node that can read and parse virtually any kind of document: docx, pdf, 7z, bmp, epub, gif, groovy, java, ihtml, mp3, mp4, odc, odp, pptx, pub, rtf, tar, wav, xls, zip, and many more!
The KNIME Text Processing extension can be installed from KNIME Labs Extension / KNIME TextProcessing. (A video on YouTube explains how to install KNIME extensions, if you need it.)
Read the MS Word file
- After installing the KNIME Text Processing extension, we take the Tika Parser node in KNIME Labs/Text Processing/IO to read and parse the content of the SnickerdoodleRecipes.docx file. The content of the file is then available at the node output port.
- The Strings to Document node converts a String type column into a Document type column. Document is a special data type necessary for many Text Processing nodes. After that, a Sentence Extractor node splits the document into the different recipes in it.
Extract the list of ingredients
- Next, we extract the paragraph with the cookie ingredients. This is implemented through a series of dedicated String Manipulation nodes, all grouped together in a metanode called “Ingredients only”.
- The “Text Processing” metanode works on the ingredient sections after they have been transformed into Documents: Punctuation Erasure, Case Conversion, Stop Word Filtering, Number Filtering, and N Char Filtering.
- Inside the same “Text Processing” metanode, a POS Tagger node tags each word according to its part of speech. Thus the Tag Filter node keeps only nouns and discard all other parts of speech. Finally, the Stanford Lemmatizer node reduces all words to their lemma, removing their grammar inflections.
- The data table at the output port of the “Text Processing” metanode now contains only nouns and is free of punctuation, numbers, and other similarly uninteresting words (i.e. non-ingredients). We now use the Bag of Words node to move from the Document cells to their list of words.
- Duplicate items on the list are then removed by a GroupBy node in the Unique List metanode.
Crawl the web page
Here we use a KNIME Community Extension, the Palladian extension, to crawl the web. It’s available under KNIME Community Contributions – Other / Palladian for KNIME. (A video on YouTube explains how to install KNIME extensions.) After installing it, we proceed to crawl the page http://www.handletheheat.com/peanut-butter-snickerdoodles/.
Crawling the web page.
- First a Table Creator node is introduced to contain the URL of the web page.
- Then the HttpRetriever node from the Palladian extension is applied to retrieve the content of the web page.
- The HtmlParser node uses the nu HTML Parser to extract the content of an HTML document and to store it in an XML data cell.
- Two XPath nodes extract the recipe from the XML document.
Now that we have the recipe text, we repeat the same steps described above in “Extracting the list of ingredients”.
Compare the two lists of ingredients
Two lists of ingredients have emerged from the two workflow branches. We need to compare them and discover the secret ingredient – if any – in the new recipe as downloaded from the web.
- A Reference Row Filter node compares the new list of ingredients with the list of ingredients from the existing recipes in the Word document. The ingredients from the old recipes are used as a reference dictionary. Only the new ingredients, missing from the previous recipes but present in the web-derived recipe, are transmitted to the node output port.
- New and old ingredients are then labeled as such and concatenated together to produce a color-coded word cloud with the Tag Cloud node. Here, new ingredients are highlighted in red while old ingredients are gray.
- Finally, the word cloud image is exported to a report, which is shown in figure 2.
Download the workflow to use yourself from the KNIME Community Hub.
It's peanuts!
We were able to successfully compare the MS Word document and data from web crawling to identify a key ingredient to add to my next batch of cookies.
Thanks to this experiment I have discovered something I did not know: peanut butter cookies. If you check the visualization, you can see the word “peanut” emerging red from the gray of traditional ingredients. I will try out this new recipe and see how it compares with my own cookie recipes. If the result is a success I might add it to my list of closely guarded secret recipes!

Credit for the web hosted recipe goes to Tessa. More infos at http://www.handletheheat.com/peanut-butter-snickerdoodles/