Welcome to the seventh episode of our series of Guided Labeling Blog Posts1 by Paolo Tamagnini and Adrian Nembach (KNIME). In the previous episodes we have covered active learning and weak supervision theory. Today, we would like to present a practical example based on a KNIME Workflow and implementing Weak Supervision via Guided Analytics.
A Document Classification Problem
Let’s assume you want to train a document classifier, a supervised machine learning model that will predict precise categories for each of your unlabeled documents. This model is required for example when dealing with large collections of unlabeled medical records, legal documents or spam emails, defining a recurrent problem across several industries.
In our example we will:
- Build an application able to digest any kind of documents
- Transform the documents into bags of words
- Train a weak supervision model using a labeling function provided by the user
We would not need weak supervision if we had labels for each document in our training set, but as our document corpus is unlabeled, we will use weak supervision and create a web based application to ask the document expert to provide heuristics (labeling functions).
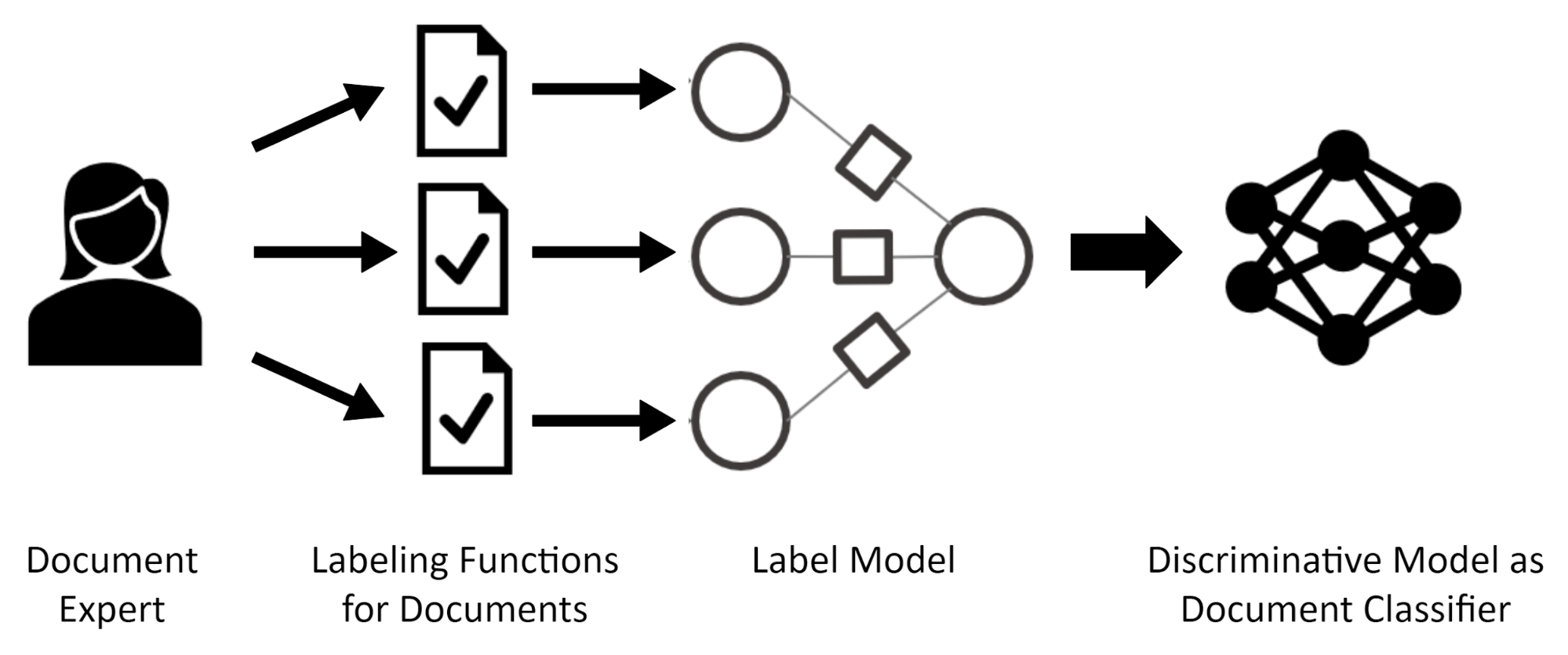
Figure 1 : The weak supervision framework to train a document classifier: A document expert provides labeling functions for documents to the system. The produced weak label sources are fed to the label model which outputs the probabilistic labels to train the final discriminative model which will be deployed as the final document classifier.
Labeling Function in Document Classification
What kind of labeling function should we use for this weak supervision problem?
Well, we need a heuristic, a rule, which looks for something in the text of a document and, based on that, applies the label to the document. If the rule does not find any matching text, it can leave the label missing.
As a quick example let’s imagine we want to perform sentiment analysis on movie reviews, and label each review as either “positive (P)” or “negative (N)”. Each movie review is subsequently a document, and we need to build a somewhat accurate labeling function to label certain documents as “positive (P)”. A practical example is pictured in Figure 2.
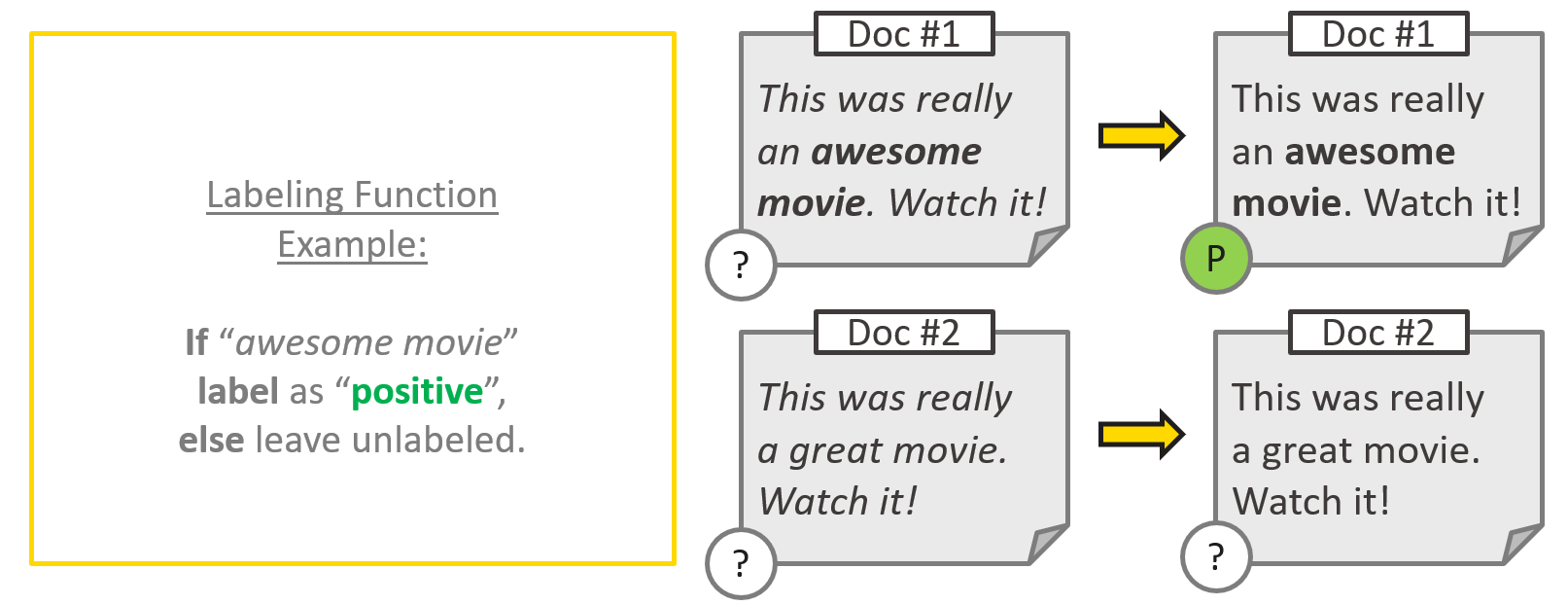
Figure 2: An example of labeling function. In the first document, which describes a movie review, the labeling function is applied and provides a positive label; a slightly different document that does not apply to the rule means that the document is left unlabeled.
By providing many labeling functions like the one in Figure 2, it is possible to train a weak supervision model that is able to detect sentiment in movie reviews. The input of the label model (Figure 1) would be similar to the table shown in Figure 3. As you can see no feature data is attached to such a table, only the output of several labeling functions on all available training data.
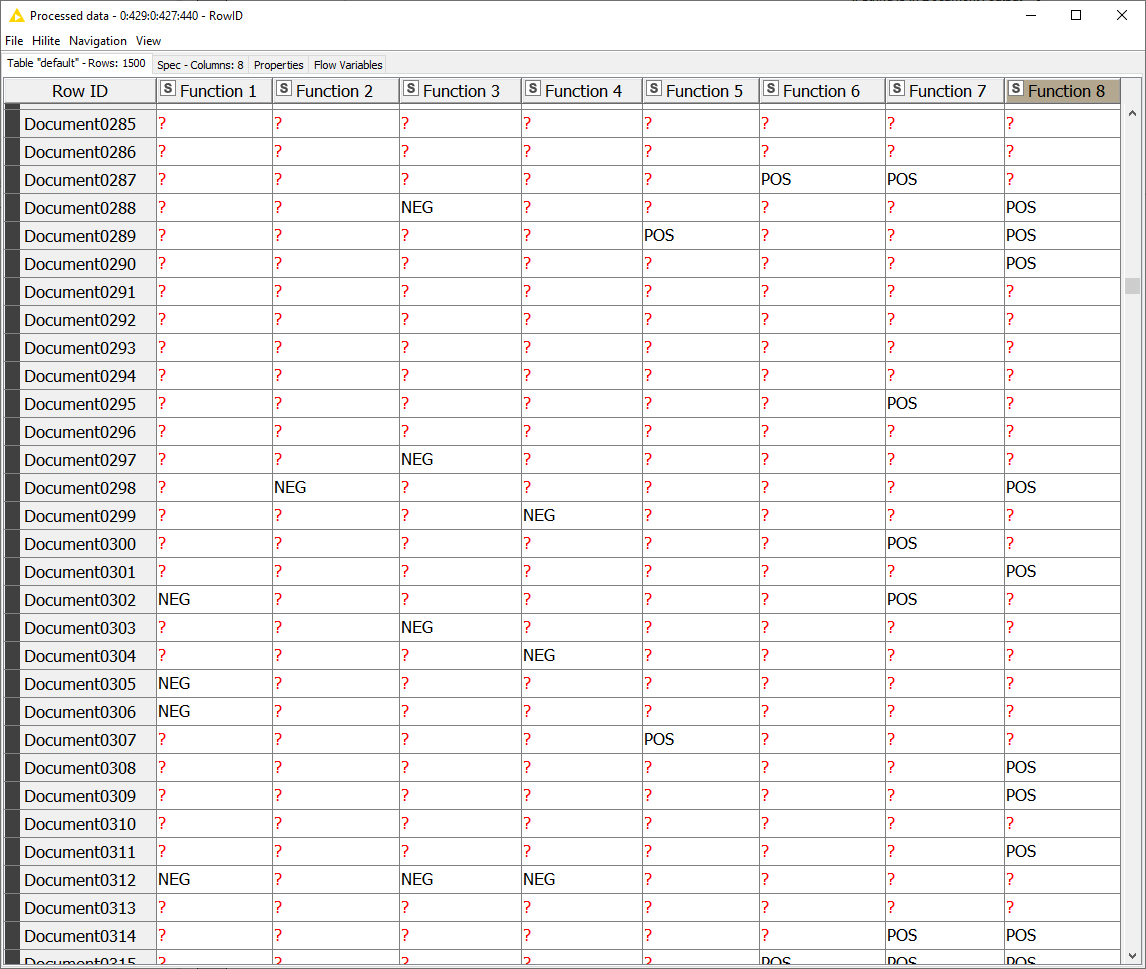
Figure 3: The Output Labels of Labeling Functions for Sentiment Analysis. In this table the output of eight labeling functions is displayed for hundreds of movie reviews. Each labeling function is a column and each movie review is a row. The labeling function leaves a missing label when it does not apply to the movie review. If it does apply, it outputs either a positive or negative sentiment label. In weak supervision this kind of table is called a Weak Label Sources Matrix and can be used to train a machine learning model.
Once the labeling functions are provided it only takes a few moments to apply them to thousands of documents and feed them to the label model (Figure 4).
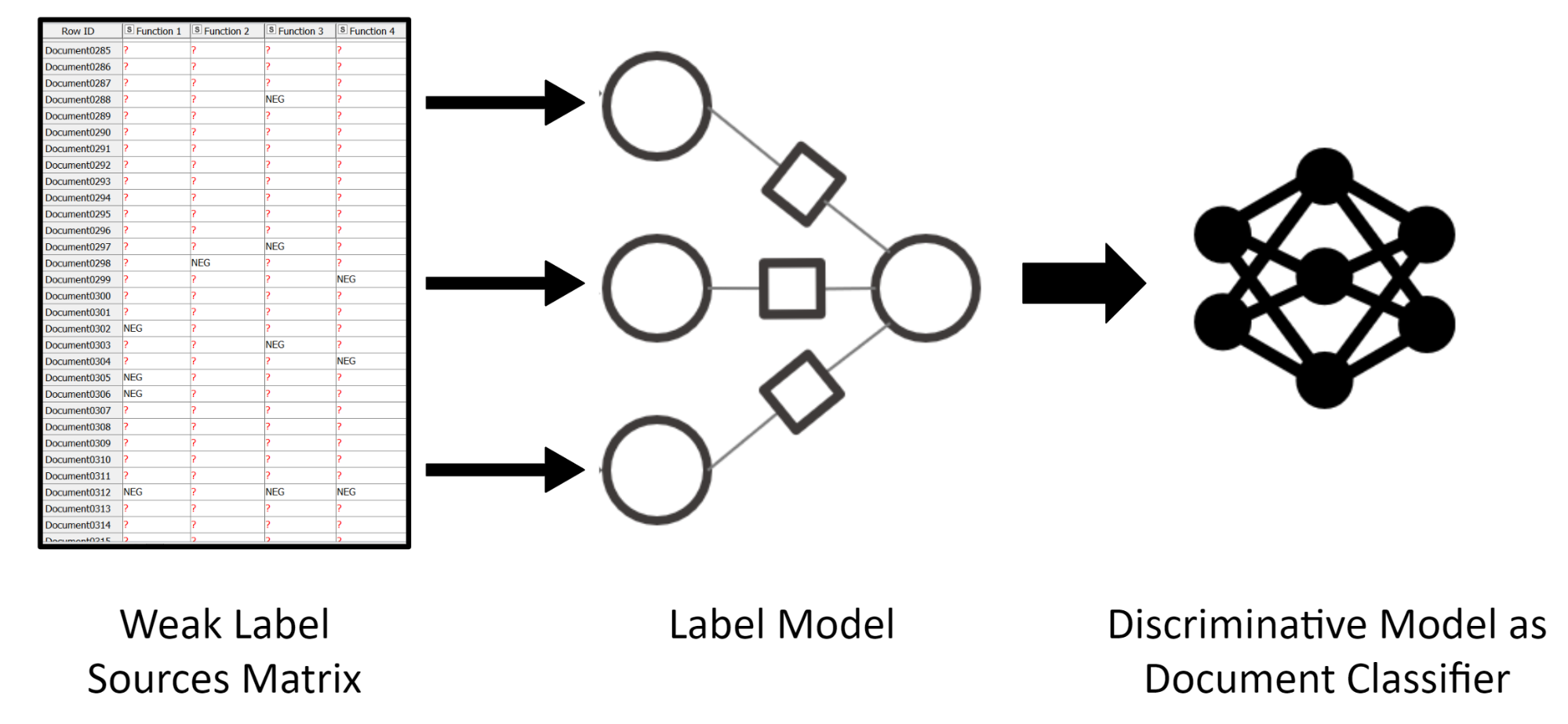
Figure 4: The Labeling Function Output in the Weak Supervision Framework. We feed the labeling functions to the label model. The label model produces probabilistic labels which alongside the bag of words data can be used to train the final document classifier.
Guided Analytics with Weak Supervision on the KNIME WebPortal
In order to enable the document expert to create a weak supervision model we can use Guided Analytics. Using a web based application that offers a sequence of interactive views, the user can:
- Upload the documents
- Define the possible labels the final document classifier needs to make a prediction
- Input the labeling functions
- Train the label model
- Train the discriminative model
- Assess the performance
We created a blueprint for this kind of application in a sequence of three interactive views, as shown in Figure 5. The generated web based application can be accessed via any web browser in the KNIME WebPortal.
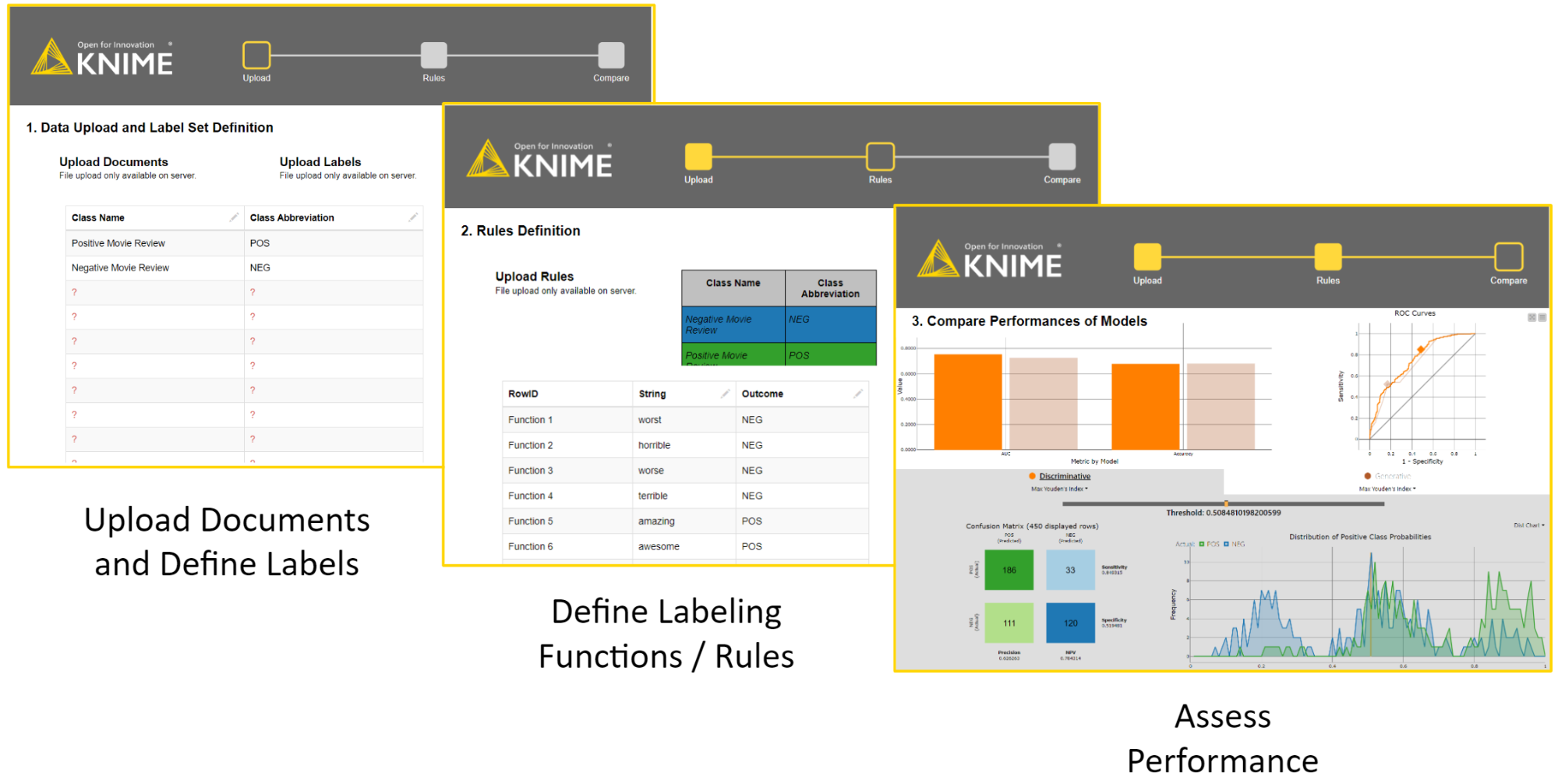
Figure 5: The three views generated by our Guided Analytics Application blueprint. The application aims at enabling document experts to create a weak supervision model by providing labeling functions via interactive views.
The implementation of this application was possible in the form of KNIME workflow (Fig. 6) currently available on the KNIME Hub. The workflow is using the KNIME Weak Supervision extension to train the Label model with a Weak Label Model Learner node and Gradient Boosted Trees Learner node to train the Discriminative Model. Besides the Gradient Boosted Tree algorithm others are also available which can be used in conjunction with the Weak Label Model nodes (Fig. 6).
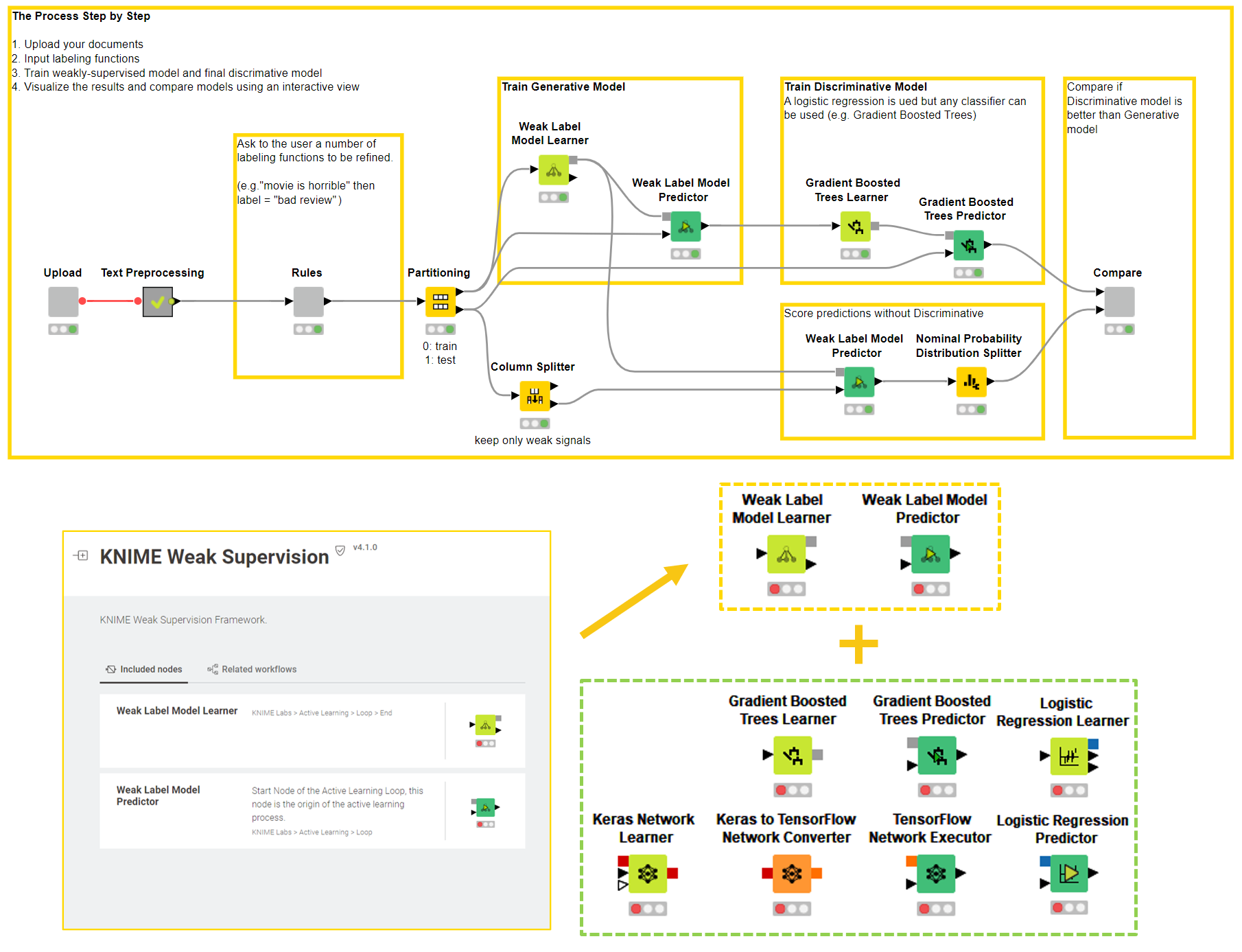
Figure 6: The workflow behind the Guided Analytics Application and the nodes available in KNIME Analytics Platform to perform Weak Supervision. The workflow compares the performance of the label model probabilistic output with the performance of the final discriminative model via an interactive view. The available nodes are listed in the lower part of the screenshot:. The nodes framed in yellow train a label model, and the nodes framed in green train a discriminative model. The workflow in this example uses Gradient Boosted Trees.
When Does Weak Supervision Work?
In this episode of our Guided Labeling Blog Series we have shown how to use weak supervision for document classification. We have described a single use case here, but the same approach can be applied to images, tabular data, multiclass classification, and many others scenarios. As long as your domain expert can provide the labeling functions, KNIME Analytics Platform can provide a workflow to be deployed on KNIME Server and made it accessible via the KNIME WebPortal.
What are the requirements for the labeling functions/sources in order to train a good weak supervision model?
- Moderate number of label sources: The label sources need to be sufficient in number - in certain use cases up to 100.
- Label sources are uncorrelated: Currently, the KNIME implementation of the label model does not take into account strong correlations. So it is best if your domain expert does not provide labeling functions that depend on one another.
- Sources overlap: The labeling functions/sources need to overlap in order for the algorithm to detect patterns of agreement and conflicts. If the labeling sources provide labels for a set of samples that do not intersect, the weak supervision approach is not going to be able to estimate which source should be trusted.
- Sources are not too sparse: If all labeling functions label only a small percentage of the total number of samples this will affect the model performance.
- Sources are better than random guessing: This is an easy requirement to satisfy. It should be possible to create labeling functions simply by laying down the logic used by manual labeling work as rules.
- No adversarial sources allowed: Weak supervision is considerably more flexible than other machine learning strategies when dealing with noisy labels, i.e. weak label sources are simply better than random guessing. Despite this, weak supervision is not flexible enough to deal with weak sources that are always wrong. This might happen when one of the labeling functions is faulty and subsequently worse than simply random guessing. When collecting weak label sources it is more important to focus on spotting those “bad apples” rather than spending time in decreasing the overall noise in the Weak Label Sources Matrix.
Looking ahead
In the upcoming final episode of Guided Labeling Blog Series we will look at how to combine Active Learning and Weak Supervision in a single, interactive Guided Analytics application.
Stay tuned! And join us on the KNIME Forum to take part in discussions around the Guided Labeling topic on this KNIME Forum thread!
The Guided Labeling KNIME Blog Series
Read the entire series on Guided Labeling by Paolo Tamagnini and Adrian Nembach (KNIME) here.