
Disclaimer: For folks who are not familiar with the KNIME Software ecosystem and for better understanding of this article, we’d like to point out that KNIME Server jobs require a running KNIME Executor in order to be run.
Oftentimes, our customers ask the following question:
The possibility to use KNIME Server with distributed KNIME Executors – with the option to have this in an autoscaling zone so that more Executors be available when the need arises – is great! But, can we run the same distributed KNIME Executors, with auto scaling, on our High Performance Computing Cluster (HPC)?
Why run KNIME Executors on HPC?
The KNIME Server distributed executor architecture assumes dedicated machines (cloud or on-prem) running KNIME Executors. But organizations often have one of the following three good reasons why they would like to launch KNIME Executors on HPC nodes.
- Your organization has recently invested in HPC resources which need to be utilized because it makes sense both economically and politically. This Makes more sense than paying for cloud resources and better utilized resources are indicators of better resource management.
- Your organization does not wish to use cloud resources. This could be because of legal restrictions, security requirements, or the budget for cloud resources is limited.
- Your organization simply has access to compute power on HPC
The answer to the question “can we run the same distributed KNIME Executors, with auto scaling, on our HPCC?” is “Yes, in some ways”.
Why only in some ways? To ensure that we can preserve the concept of auto-scaling, this needs to be extremely well crafted. Basically three things need to be in place to ensure auto-scaling:
- We need to host the KNIME Executor (a full build and portable KNIME Analytics Platform Software) on a shared drive that is accessible in the compute nodes to be used for this purpose. This executor installation needs to be able to run multiple times on different compute nodes – which the KNIME Executor supports.
- If needed, we need to be able to remotely launch a new KNIME Executor and remotely shutdown a running one and thereby release the resources of the compute node.
- We need the ability to orchestrate the “auto” in auto-scaling.
For Item 1, we need a KNIME Executor installation with all the necessary plugins installed. Then we need to host it on the cluster via a shared file system. The installation must be accessible from the compute nodes intended to be used for this purpose. And we need a mechanism to launch multiple executor processes from it.
Item 2 is straightforward. There is a way to send a shutdown signal to a running Executor from the KNIME Server via a REST call.
Item 3, on the other hand, is tricky. We need a more involved process to make this happen. We have a number of suggestions for this more involved process.
Let’s see how to solve these challenges.
Prepare the KNIME Executor Install:
First we need a full-build KNIME Analytics Platform installation that has all required plugins installed and configured. This can be downloaded from KNIME’s commercial software download site. If additional extensions are required to run workflows specific to your organization’s needs, they can be installed by running the following example commands from the installation directory. The KNIME Analytics Platform version number can be adjusted as needed.
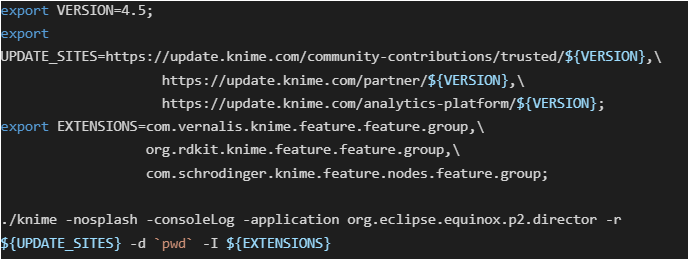
Host the Executor on a Shared Mount
Now that we have an executor installation ready, we need to get it into a shared drive accessible on the cluster. We also have to make sure that intended users have execution permissions to the binaries within the installation. Alternatively we can put it under the home directory of a specific user(s) that will be launching executors.
Multiple KNIME Processes from Single Installation
The goal of enabling multiple KNIME processes from a single installation can be achieved by modifying the way we launch our KNIME Executor to get an instance of a knime process. Each knime process needs its own configuration and workspace. This means we need to guarantee that each instance uses its own unique folder for configuration and workspace. We also need to make sure there is no file locking happening. Let’s discuss each of these points one by one..
KNIME Workspace
The workspace, aka knime-workspace, is where workflows and user preferences live. A single workspace can be used by a single running executor process. One workspace can be used by two different installations of a KNIME Executor at different times, but not simultaneously. This is enforced by keeping a .lock file within the workspace. But there is an option to run the knime process with a custom workspace path. This gives us the chance to ensure the uniqueness of the workspace path.
In practice, setting the -data parameter as follows ensures that the workspace is unique per user and per HPC job.

Note that getting the variable could differ depending on the type of controller used by the HPCC. For SLURM controllers for example, it is named as
Configuration Area
KNIME Executor is an eclipse based product and as such, it keeps a configuration within the installation which is updated on every run. This configuration area cannot be shared between two running knime processes. Luckily, this default behavior can also be overridden using the -configuration command line parameter.
Our example from setting the knime-workspace (above) can be modified as follows.

Disable File Locking
File locking is not supported by many HPC file systems such as Lustre. We can disable file locking by using the following two JVM parameters accordingly.

Aggregating the above configurations, we can create a shell script to launch the KNIME Executor process/es as a job on one or more HPC node/s. An example shell script for a SLURM controlled HPC is shown below. It might need to be adapted to the error / message handling commands specified by your organization’s HPC system.
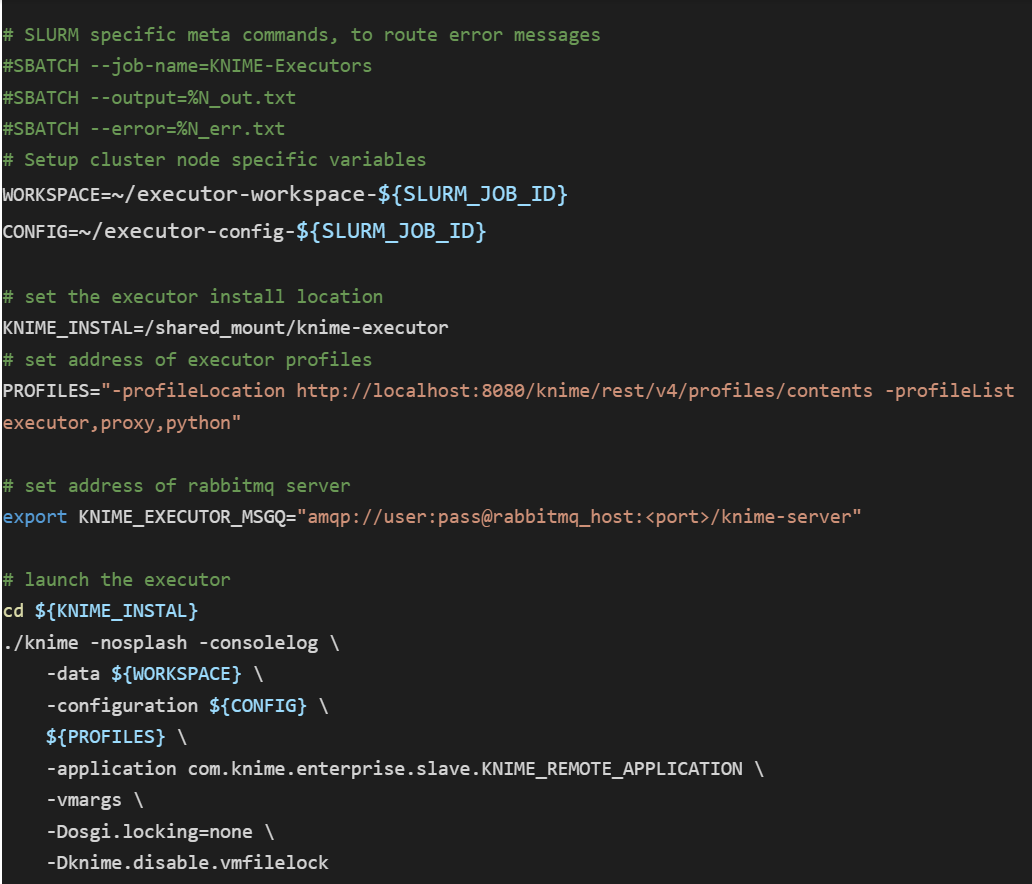
We can queue the above script using an HPC system’s job submission mechanism. Since we are describing a setup that is based on SLURM Workload Manager, the following invocation will queue X instances of the executor, which will connect to your KNIME Server instance and will start processing jobs for it.

More Ways to Launch Executors
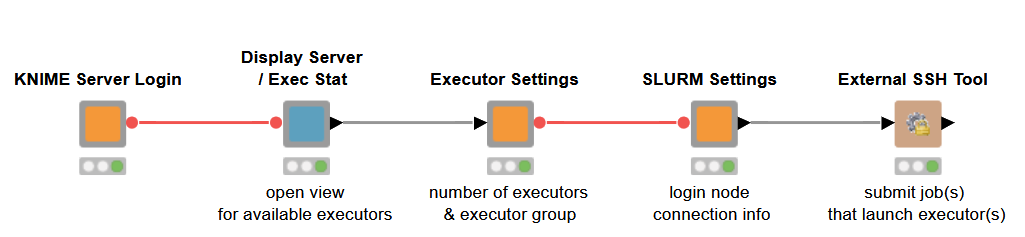
1. If we can guarantee at least one executor to be always running, we can mimic auto scaling behavior using a scheduled KNIME workflow that can ssh to the login node of a cluster and launch an arbitrary number of executors.
The workflow can be built in such a way that it sees how many KNIME Server jobs are waiting in a queue or the average CPU load on running executors. We could launch more executors when the queue gets larger or shut down running executors when the average CPU load drops below a certain threshold.
The example workflow in the screenshot below shows how to do this, but omits the automation.
2. We can embed the launch X executor logic within the actual workflow so that the main computation of the overall workflow is performed by the newly launched executors. For this to work we need to design our workflow carefully. Basically we need to have a master-worker workflow setup.
- The master workflow orchestrates the launch of new executors including waiting for them to go online. Sometimes the jobs, launching the executors, could be stuck in the HPC queue depending on node availability.
- The main workhorse workflow (worker) has to be called and checked that it runs in the newly launched executor.
- The executors need to be shutdown after the job is done.
Shutting Down Running Executors
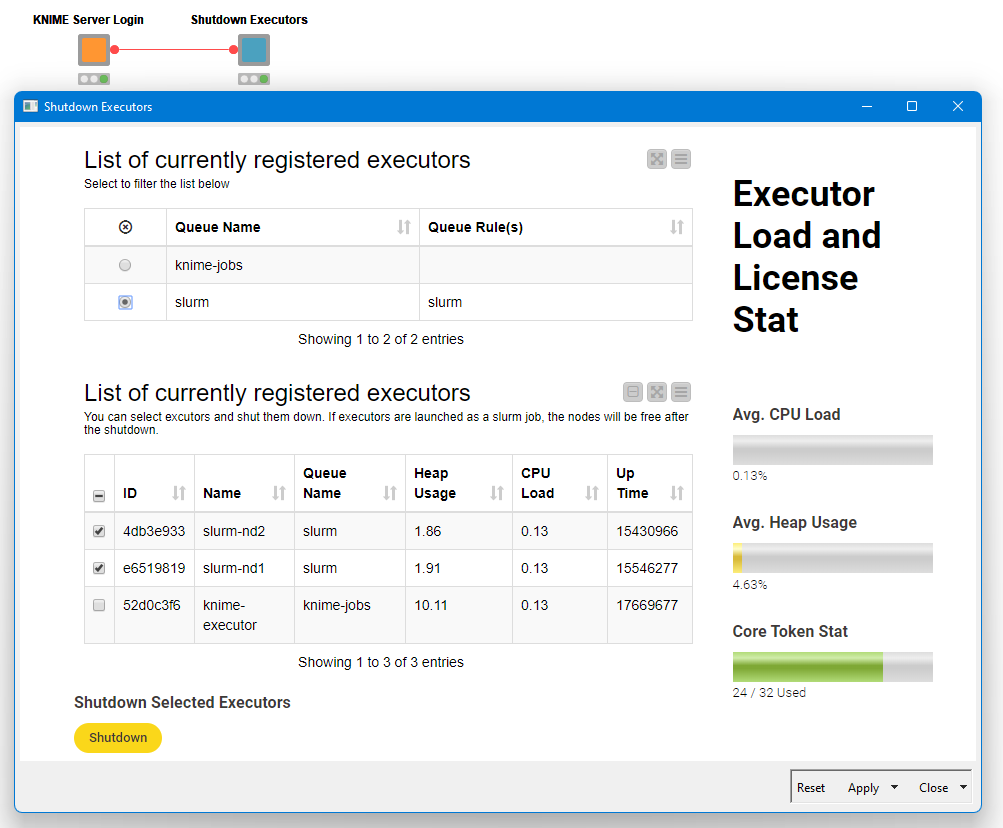
The KNIME Server provides a REST endpoint (/rest/v4/admin/executors) to monitor and control KNIME Executors registered with it. You need to be a KNIME Server administrator to use this endpoint.The endpoint is well documented in the Swagger UI documentation page of the KNIME Server Rest API under https://
First, we need to gather information about existing executors using the GET method of the endpoint. The returned JSON has detailed information about individual executors including a fully formatted DELETE request URL for each executor. This DELETE request can be used to shutdown a specific executor. Please have a look at the KNIME workflow that handles shutdown-executors. It provides a data app (screenshot shown below) using the described endpoint to select and shutdown one or more executors.
Utilizing Multiple KNIME Executors on HPC
Once we have KNIME Executors up and running we can treat them as any distributed executors. This means we can exploit KNIME Server distributed execution features such as workflow pinning, executor reservation and executor groups.
One way of utilizing the executors running on HPC is by designing workflows in master-worker pairs. The master workflow can make use of the Parallel Chunk Start and End nodes effectively creating multiple executing branches. In these branches, we can use the Call Workflow Service node to call the worker workflow which does the computational heavy lifting. The following example use case on cell segmentation demonstrates how we can do that.
Example Use Case – Cell segmentation
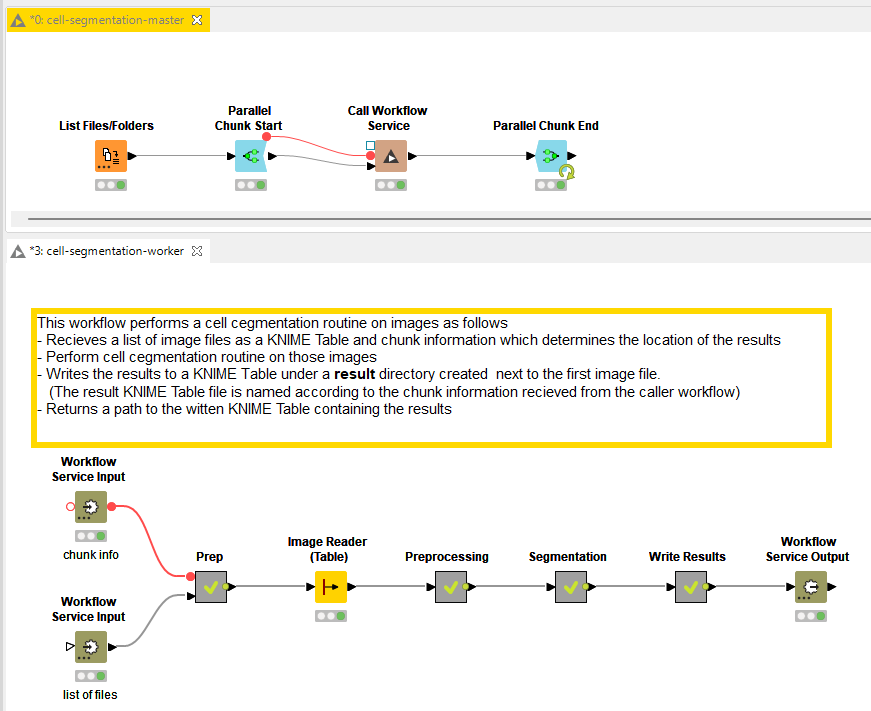
In this example use case, we have two workflows performing cell segmentation. The first workflow (cell-segmentation-master) gets the list of image files from a directory and distributes them to be processed by the worker workflow (cell-segmentation-worker). The cell-segmentation-worker workflow contains the entire logic to segment cell nuclei from cytoplasm and label them.
When the execution of the master workflow is triggered, it effectively creates multiple jobs out of the worker workflow each working in a separate set of files. To avoid large amounts of data being transported between the server and HPC Nodes, we recommend passing only pointers to input files between the master and worker workflows. Provided that a) the files live in a shared drive and accessible on the cluster b) local file system access is enabled for the executors, this should work without a problem. Depending on the requirements of worker workflows, we can make sure that they are executed on a selected group of) executors by editing the workflow properties as described in the workflow pinning section of the KNIME Server Admin Guide.
Summary
Running KNIME Executors on a HPC cluster can be useful in different scenarios. We’ve shown how this can be achieved using the distributed executor capabilities of the KNIME Server. We have also touched upon the building blocks necessary to automate the process of launching more executors or shutting down existing ones and potentially automate the process. Then, we provided an example use case to showcase one way of using such executors. In the example, workflows were designed as master-worker pairs, where the worker workflows are pinned to run in parallel on multiple executors.