
Text mining is an efficient data analysis technique to use if you need to not only get a quick sense of the content of specialized documents, but also understand key terms and topics, and reveal hidden relations.
All kinds of different analysis opportunities are opened up by text mining techniques. Natural Language Processing (NLP), topic modeling, sentiment and network analysis - all text mining techniques - can be used effectively in areas such as marketing (analysis of online customer interactions), politics (analysis of political speeches to ascertain party alignment), technology (assessment of COVID-19 app acceptance), research (publication biases), and electronic records (e.g., email, messaging, document repositories), spam filtering, fraud detection, alternative facts detection, as well as Q&A.
However, extracting the valuable information that is potentially hidden in the textual data and depicting relations among the textual data explicitly, for example by visually representing key attributes of the text in relation to industry standards can pose quite a challenge. Overcoming this challenge is important for organizations to stay competitive.
Webinar about text mining techniques
The team of data scientists at Redfield has put together a webinar about text mining that addresses these challenges. The webinar is split into two parts:
- An overview of the range of insights and knowledge that can be mined from text, providing business cases to highlight this.
- Demonstration of a practical example of a KNIME workflow in order to:
- Gain insights from a collection of documents about chemical compounds
- Identify in which documents a specific chemical compound is mentioned
- Specify the topics of the selected documents
- Reveal what is common among two documents by building a knowledge graph from domain specific documents
Rewatch the webinar Text Mining Uses & Deep Dive into Use Cases and Techniques on YouTube
Gain insight and visualize findings
At the webinar, the Redfield team will be blending multiple Natural Language Processing (NLP) techniques and presenting the results in different output formats such as tables, graphs, also highlighting text as shown in the screenshots to help the user make sense of the information contained in the original text collection.
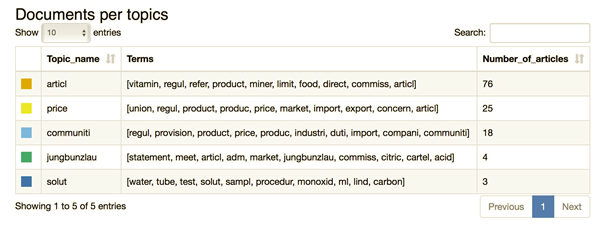
Fig. 1 Summary of topic modeling application to our text collection: list of topics with their label, list of terms and number of documents assigned to that topic as the majority topic.

Fig. 2 Visualization of Named Entity mentions and links. Each named entity is shown in a different color. Chemical compounds, for example, are shown in gray. These types of named entities are also automatically linked to the Wikipedia article about the respective chemical compound.
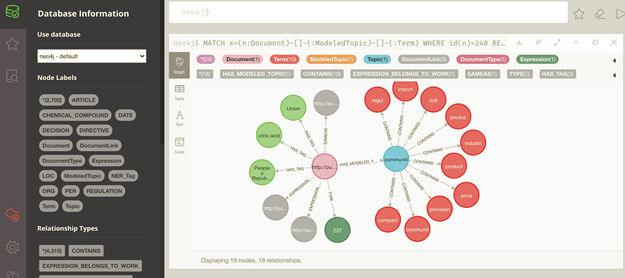
Fig. 3 Visualization of documents with their topics, topic terms, and named entities in Neo4j.
Use case: KNIME workflow for building a knowledge graph
The Redfield team will walk you through a KNIME workflow to build a Knowledge Graph, which consists of the following main steps:
- Retrieving the documents about a specific topic from a SPARQL endpoint
- Applying Named Entity Recognition and Linking, as well as Topic Modeling
- Populating our SQL and external (Neo4J) Graph databases
- Performing interactive named entity and document selection and table + graph visualization
The webinar in practice
The webinar is aimed at data scientists or business user/domain experts. It is designed for KNIME users who wish to get acquainted with more complex KNIME workflows that integrate multiple heterogeneous NLP and data science tasks.
Key takeaways for this session are:
- You will blend several NLP techniques to build a Knowledge Graph for a collection of documents within a KNIME workflow
- You will build interactive visualizations for text highlighting and relation finding between documents.
- We will provide a simplified version of the workflow for the users to download and play with.
The webinar presenters
Jan Lindquist is a data scientist leader at Redfield. He helps customers deploy KNIME Server on AWS. He also performs GDPR privacy assessments and standardization work to improve data governance through tools like KNIME and the KNIME privacy extensions.
Artem Ryasik has an academic background in life science and a PhD in biophysics. He works as a data scientist at Redfield. Projects include graph analysis, recommendation engines and data anonymization. When time permits he develops KNIME node extensions such as the OrientDB and Privacy nodes based on ARX open source software. He also teaches KNIME courses in Nordics.
Nadjet Bouayad-Agha holds a PhD in Natural Language Processing and has many years of experience in the field, as an R&D academic and in later years as a Freelance Consultant. She is particularly interested in Natural Language Generation, Ontologies, the Semantic Web and the use of Deep Learning/Machine Learning for resolving NLP problems.