
The KNIME Streaming Executor is an extension that currently "hides" inside KNIME Labs. Not many of our users are aware it exists, so let's find out what it can (and can't) do and why you should be interested.
Streaming?
If you are used to KNIME's standard execution model you will know that connected nodes in a workflow are executed one after the other. The obvious advantage is that you can easily understand what is currently executing and what the (intermediate) results are, produced by each of the nodes in your workflow. That significantly simplifies debugging, because you can see immediately if some intermediate step isn't producing the expected result. You can also reset/continue with the execution at any point in the workflow without re-running the whole workflow -- saving on computation time. Another benefit of the standard execution model is that you can use KNIME's Hiliting to inspect the results and also explore your data using some of the view nodes.
However, the standard execution model also has some drawbacks. Each node needs to cache its results, which requires additional temporary space. (Note that KNIME doesn't duplicate the data from node to node but saves only what has changed between subsequent nodes ... so this isn't as bad as it might sound.) Additionally, as a node doesn't start processing the data until its upstream node has completed, it will need to read the dataset from start to end. Depending on whether those data live in main memory or on hard disc (which is KNIME's choice and depends on data size + available memory) this may require additional I/O operations, which can slow things down. You will notice that if you have a long chain of simple preprocessing nodes, most of the time is spent on just reading the data and caching the intermediate results.
To address these bottlenecks we've developed the KNIME Streaming Executor. Instead of executing node by node it executes nodes concurrently in a section of your workflow. In this process, the results of one node are instantly provided as input to downstream nodes. That cuts down on I/O and memory usage as only the few rows 'in transit' need to be taken care of, which should speed up your calculations. If you are familiar with Unix shells you will know this from pipes such as
Streaming!
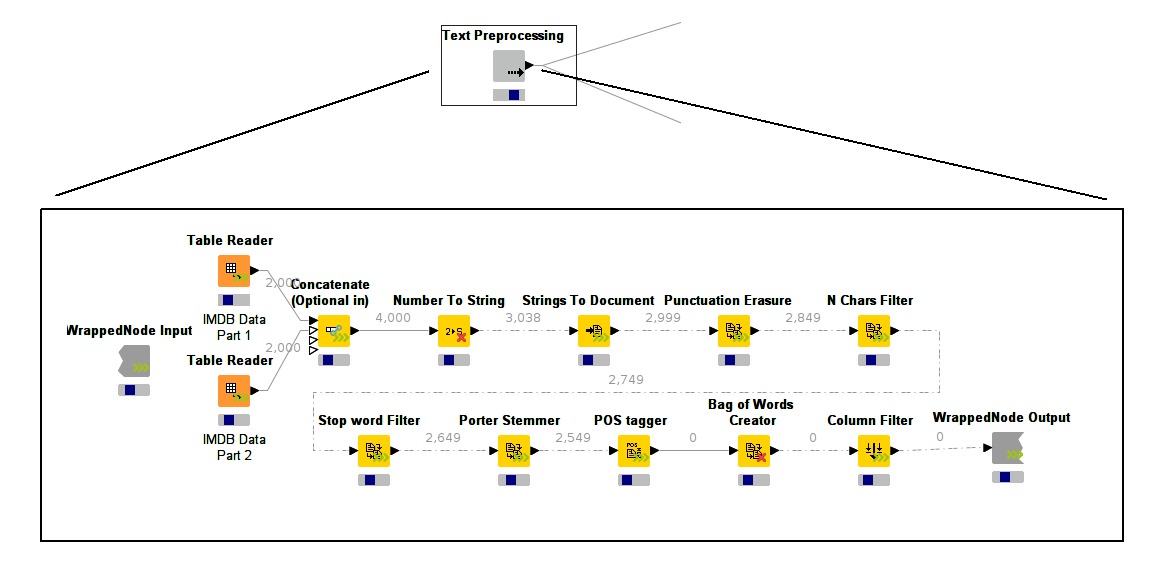
Before looking at installation and set-up steps let's look at an example. Below is a screenshot of a workflow, which we use internally to monitor the KNIME.org web server(s) traffic. It's a typical use case for weblog analysis.
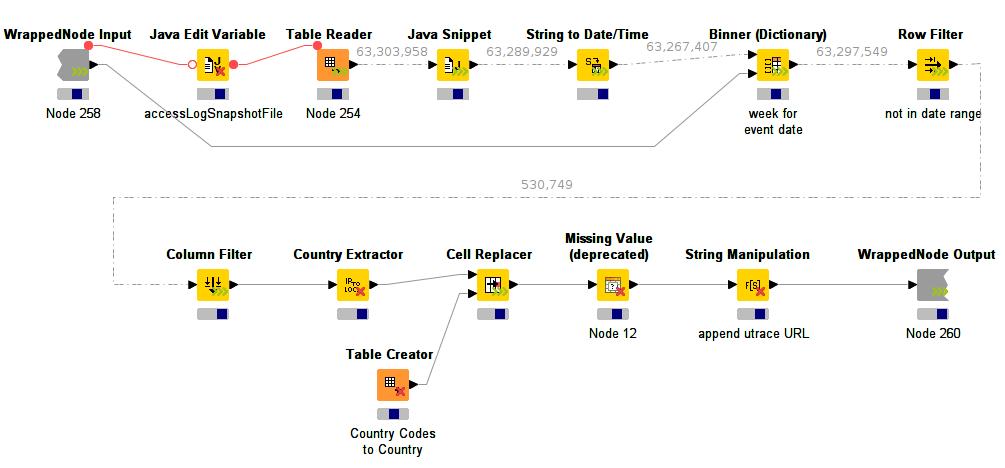
The workflow reads some data source (a KNIME table that is created by another workflow parsing apache log files) and then does some simple preprocessing and filtering such as filtering by date, removing invalid entries, etc. It also maps IP address fragments to countries.
From the screenshot you will notice that the workflow executes all nodes concurrently (they all have an undetermined progress bar and don't show the traffic light). Also note that some of the connections are dotted, the numbers above the lines show the number of records that have passed that particular connection. In fact, the connections are animated and the counts are increasing. The data 'flows' between these nodes. This particular section of the workflow processes around 10GB of compressed data. Using the standard executor -- node by node -- this takes about an hour of execution time (using my average 2 year old laptop). Using the streaming executor, execution time is reduced to under 10min. This is mostly due to the data being read/written only once and also due to a fairly selective row filter, which causes a lot of data to be read and immediately discarded. (The workflow is filtering the server logs for a particular time window.)
This workflow is only a part of a much bigger workflow but it is by far the most expensive operation taking place. The result of the preprocessing step is then fed into various loops and finally prepared to be rendered in a KNIME report. This is not shown here.
Installation and Set-up
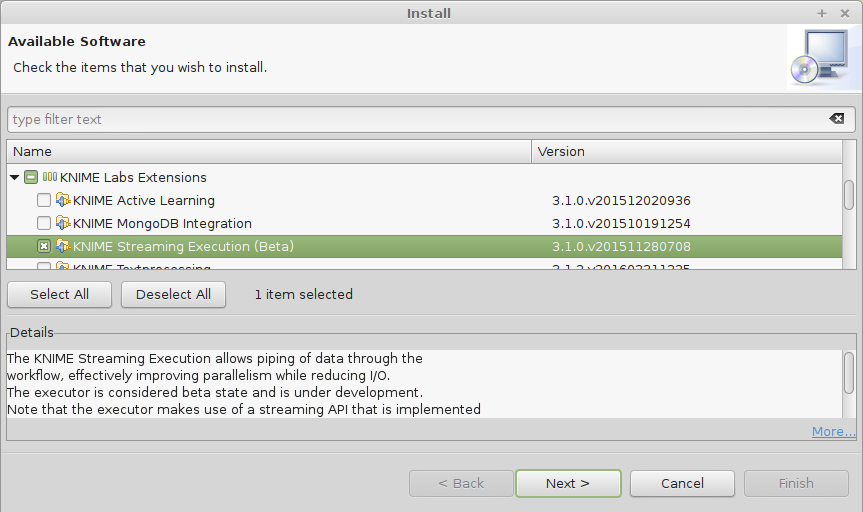
So let's see how this is done in KNIME Analytics Platform. As mentioned before, you will need the corresponding Labs extension, called "KNIME Streaming Execution (Beta)":
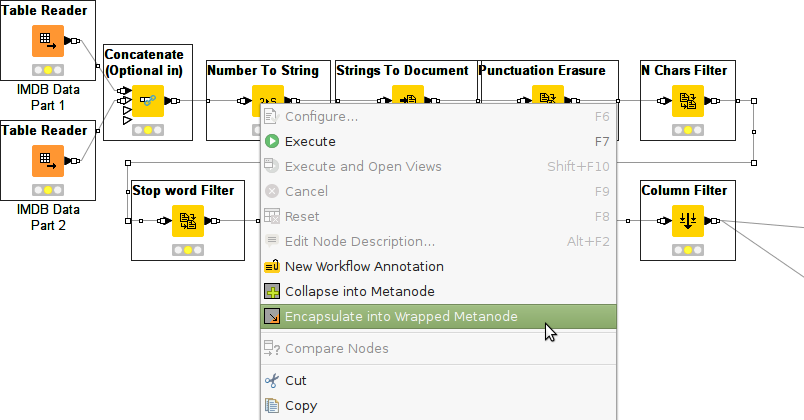
In order to use the executor you will need to identify the part of your workflow that should be running in streaming mode and collapse it into a Wrapped Metanode. Select the nodes, right click them and choose "Encapsulate into Wrapped Metanode" (in KNIME Analytics Platform 3.1.x and before you would first choose "Collapse into Metanode" and then "Wrap"):
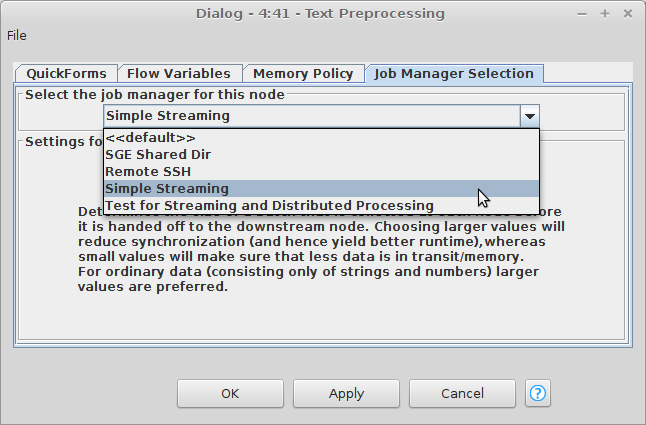
After giving it a meaningful name you can set the "Simple Streaming" executor in the configuration dialog of the newly created wrapped metanode.
And that's all. When executed, the data are streamed inside the wrapped metanode.
There are a couple of important issues to note: You can only execute the entire wrapped metanode. It's no longer possible to enter the metanode and selectively execute parts of it. Secondly, most of the nodes won't show any table after completion; this is because the intermediate results are not cached. However, the end node ("WrappedNode Output") will cache all of the results and that's what we care about.
Remarks
The KNIME Streaming Executor is currently part of KNIME Labs and can be considered "beta" quality. It's an active field of development and while we know the computed results are correct the general (error) handling leaves room for improvement.
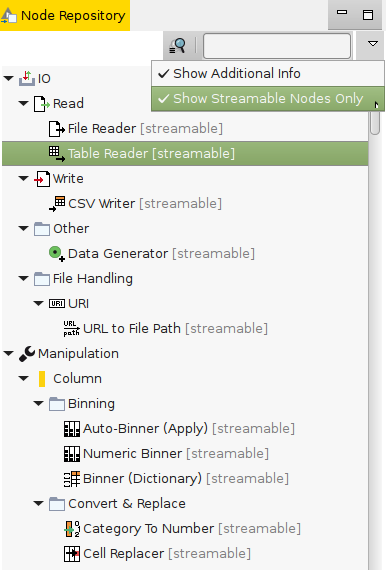
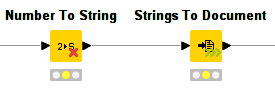
The Streaming Executor builds upon a new API that each of the node implementations needs to follow in order to 'stream'. The API was developed in cooperation with one of KNIME's technology partners, Actian. While some of the nodes follow this new API, the majority of nodes still allow only for node-by-node execution. The executor can deal with this, meaning that 'new' and 'old' nodes can be mixed. As a user you can easily identify if any given node is adopted by the new API -- you'll find small decorators attached to the nodes. Nodes with three green arrows on the bottom right follow the new API, nodes with a red cross don't. Additionally, the node repository has a new filter that allows you to see only those nodes that support streaming natively:
The executor does not currently exploit the full breadth of the API (for instance parallelization and distribution), although the streaming capability is in place.
Summary
I hope this gave a comprehensive summary. While the executor isn't quite ready for prime time, it's certainly worth a look. If you want to use it in your own workflow I'd suggest carefully reviewing and isolating the costly part and running the streaming executor on it. That is usually the data reading part and longer chains of preprocessing nodes. We will be working on moving more nodes to the new API and also on improving the executor in future releases.