
In the realm of natural language processing (NLP), extracting meaningful insights from extensive textual datasets remains a challenge. Latent Dirichlet Allocation (LDA) and Structural Topic Modeling (STM) offer powerful solutions for understanding and simplifying the content of a collection of documents. However, those algorithms are influenced by a few parameters. One of particular significance is the number of topics that the researcher wants to extract, which must be predetermined.
Indeed, the essence of topic modeling lies in the ability to cluster complex textual data into coherent and interpretable themes, yet the determination of the optimal number of topics is a challenging task.
To tackle it, researchers have devised a range of indicators, each carrying its own set of strengths and weaknesses. In Blei’s seminal work (2003), the authors introduced the perplexity index, which is one among the prominent methods for evaluating topic model performance. The indicator measures essentially how well the topic model can predict unseen topics. However, while perplexity serves as a common measure in topic modeling, it is important to note its limitations. Perplexity does not directly measure accuracy; hence, a model may exhibit low perplexity yet high error rates. In essence, a model’s confidence in its predictions does not necessarily guarantee their correctness. Moreover, comparing perplexity across datasets poses challenges due to the unique word distributions inherent in each dataset, compounded by variations in model parameters. Consequently, directly comparing the performance of models trained on different datasets becomes arduous.
In this article, we will explore a methodology that involves computing Chi-square statistics (χ²) to measure the goodness of fit of a topic model. This method addresses the limitations mentioned earlier.
All along, we’ll rely on a low-code approach using the Topic Model Goodness of Fit (χ²) component in KNIME Analytics Platform.
Let’s get started!
Recap: LDA Basic Setup
Topic models indeed function akin to techniques for clustering. They uncover the latent structure of the words within a collection of documents by identifying clusters that constitute topics.
More formally, we define a corpus and a document respectively as collections of documents and words:
Corpus = {document₁, document₂, document₃, document }
document = {word₁, word₂, word₃, wordⱼ}
The content of the corpus is summarized by the estimation of two matrices:
- The Document-Topic Weights (DTW) matrix shows topics distribution across documents;
- The Topic-Word Weights (TWW) matrix assigns weights to words within each topic, aiding human comprehension.
DTW displays the topic presence across documents, aiding quantitative exploration. This is achieved by adding N columns (topicₙ) that represent the probabilities of each document discussing that particular topic.
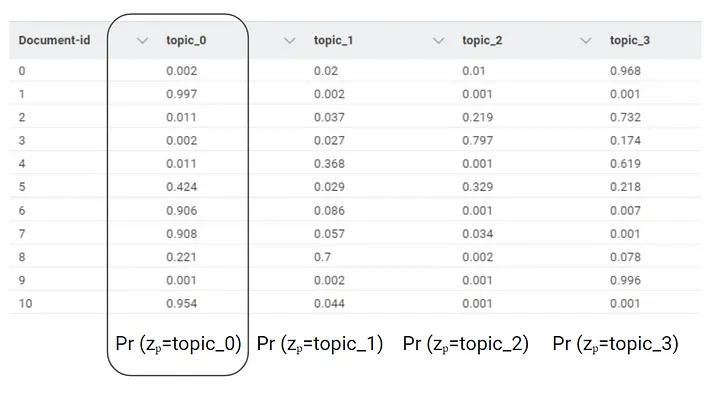
TWW enhances topic interpretation by assigning a weight to words and the topics, facilitating qualitative insights extraction. The relationship between words and topics is not exclusive; the same words might be assigned to different topics. We can determine the conditional probability of a word, represented by wordₚ , belonging to topic zₚ, using the softmax function to transform the weight.
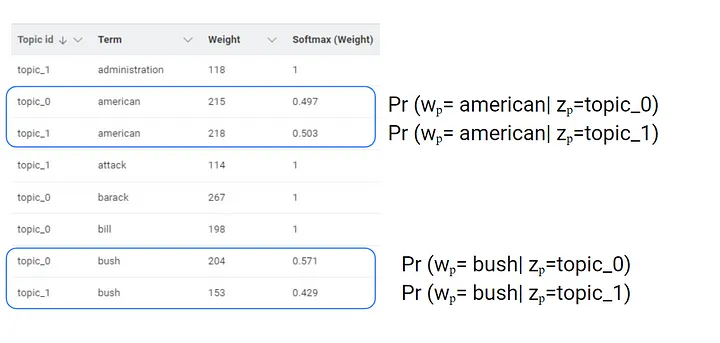
In the figure above, you can observe that the model does not directly provide the probabilities of occurrence for the words within each document. This information needs to be derived by performing a pairwise multiplication between the DTW and DTM. By doing that, we can estimate the word vectors according to the LDA:
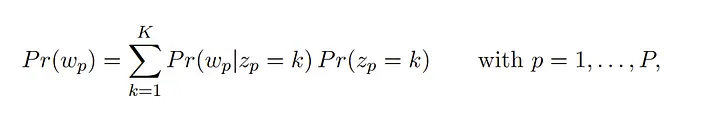
where Pr (wₚ| zₚ=k) is the probability of observing wordₚ given the presence of topic zₚ , and Pr (zₚ=k) is the probability of observing the topic zₚ, in documentⱼ.
This equation enables the quantification of the word relative frequencies following the generative process of the topic model, as Pr (wₚ| zₚ=k) can be easily derived by means of TWW and Pr ( zₚ=k) are the probabilities in the DTW.
Why Chi-square (χ²) statistics?
Determining the goodness of fit of a topic model involves establishing a theoretical framework to address the question: what constitutes a proficient representation of a corpus of documents by a topic model?
Lewis, C. M., & Grossetti, F. in “A Statistical Approach for Optimal Topic Model Identification” (Journal of Machine Learning, 23(58), 1−20, 2022), introduced a series of parametric tests designed to assess the fit of a topic model to a given corpus. The first test indicates that a k-topic model accurately describes a collection of documents if the actual word frequencies (what we see in the documents) and the estimated word frequencies (calculated by means of the topic model output by the formula above) are very close.
To quantify this discrepancy and assess whether the word vectors align, they devised a Chi-Square Statistics that utilizes both observed word vectors and those estimated by the Latent Dirichlet Allocation (LDA) model. Indeed, this traditional statistic serves as a similarity measure. The authors also developed an R package, which is not on CRAN yet.
Remember that a Chi-Square, in its easiest formulation, is calculated as the squared difference between the expected values and the observed values:
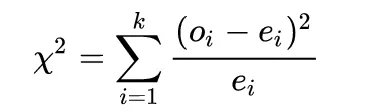
Based on this principles, the authors derived a measure that represents how well the topic model represents the corpus of documents:
The “Optop” statistic measures the goodness of fit of a topic model.
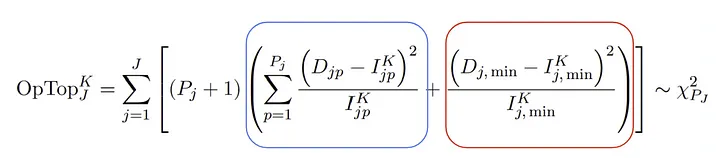
At first glance, this formula may appear daunting, but its purpose is straightforward: it computes a Chi-Square distance between the estimated word vectors and the observed relative word frequencies. Once we have computed the estimated word vectors from the LDA (the most challenging part), and the relative word frequencies (much simpler), we have all the elements needed to apply the formula to our dataset. Now, let’s delve into the equation.
The formula consists of three terms, which are computed at document level and summed up at the end at the corpus level:
- The Important Words Component (Blue Frame): This term represents the Chi-Squared difference between the most relevant estimated word vector and the observed word vector for document ⱼ.
- The Unimportant Word Component (Red Frame): Here, the Chi-Square distance is calculated for all aggregate words that are not particularly relevant in document ⱼ.
- The term “Pⱼ + 1” signifies the degrees of freedom, where “Pⱼ” represents the count of relatively important words in document ⱼ.
As you may guess, to reduce the noise, less significant words are grouped into a single bin, referred to as the “uninformative component.” This component is populated when the cumulative probability distribution of the words in document ⱼ surpasses 0.8.
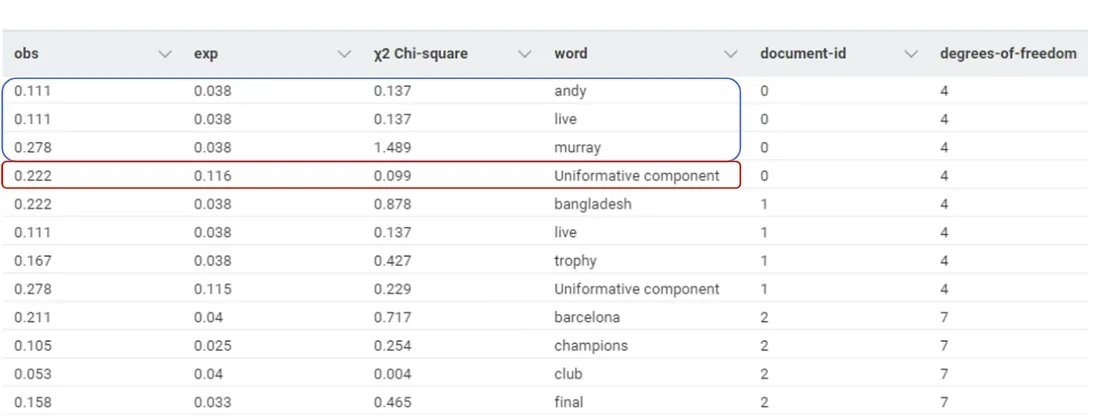
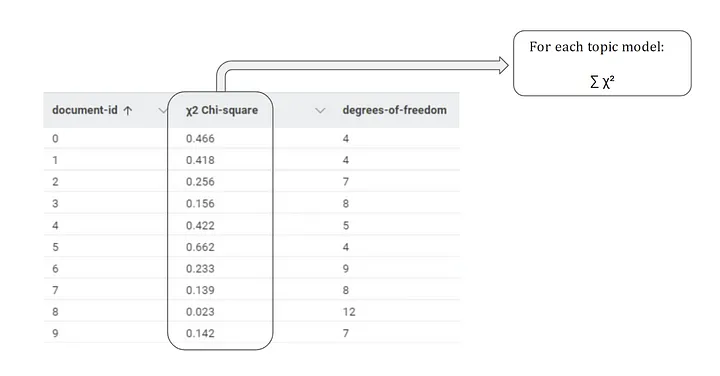
Summing up the χ² values by document, we obtain a measure of goodness of fit for each documentⱼ.
Furthermore, if we sum all the χ² at a corpus level, we get a unique and comprehensive measure on how well the corpus is represented by that topic model.
A lower Chi-Square value indicates a better fit, as it signifies a smaller distance between the observed and estimated word vectors, indicating that the LDA accurately represents the documents (χ² is lower-bounded to 0). However, to determine the ideal number of topics, a hypothesis test would be a more effective strategy, which we will discuss in the section below.
Testing Chi-square (χ²) on real data
To test the goodness of Chi-square statistics, we need to think of the process as a typical hyperparameter optimization in machine learning.
This means that we will loop over the number of topics we wish to extract to test which number of topics provides the best fit for our corpus. We are going to test the χ² on real data.
The first corpus comprises around 190 diverse news articles scraped from the web, while the second consists of 500 texts focused on political topics. It’s important to note that LDA is effective when dealing with documents of sufficient length. This technique may yield inconsistent results if the text lacks adequate length.
The Topic Model Goodness of Fit (χ²) component in KNIME
To run the test, we will rely on a fully no-code approach thanks to the Topic Model Goodness of Fit (χ²) component available for free on the KNIME Community Hub. Additionally, in the project folder on the KNIME Hub, you will find the example workflow that is used in this test.
This component operates on the output of the LDA topic model or any other similar model that outputs the TWW and DTW matrices. It has been tested on two different corpora and the results are presented below.
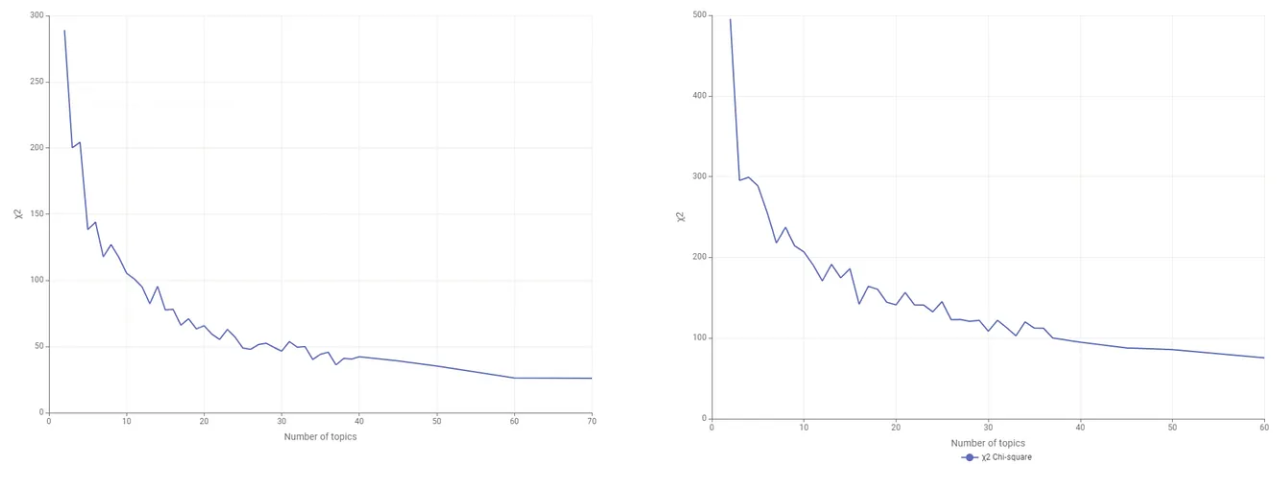
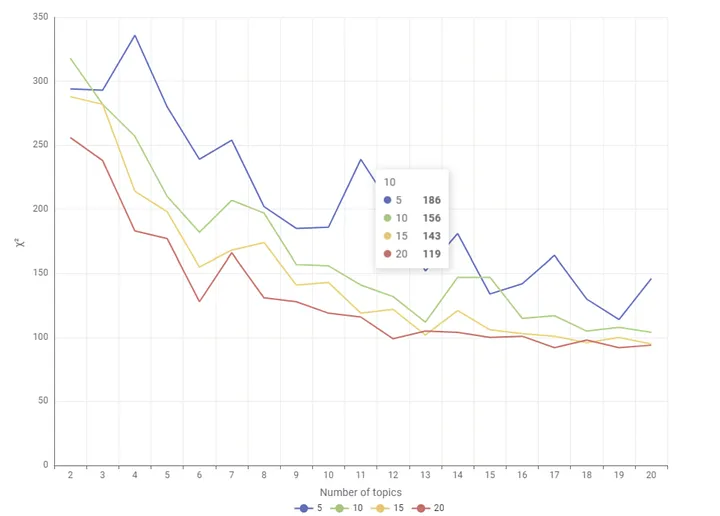
The plots below show the behavior of the χ² as the number of topics extracted increases. The steepness of the curve indicates that increasing the number of topics extracted enhances the goodness of fit of the topic model.
The optimal number of topics is found at a point where the curve starts to flatten out, indicating a diminishing return in model performance improvement. The authors suggest that the precise number of topics is where we reject the hypothesis that the observed and estimated word distributions for document Dj are statistically indistinguishable. However, the statistical significance of the Chi-Square test is not yet incorporated into this component.
The cool thing about this Chi-square is that we can also use it to optimize the other parameters like alpha (α) and beta(β).
Alpha (α): It controls the sparsity of document-topic distributions. A higher alpha will result in documents being represented by a mixture of more topics, making the distribution more uniform. This parameter directly affects the DTW.
Beta (β): It controls the sparsity of topic-word distributions. A higher beta will result in topics containing a mixture of more words, making the distribution more uniform. This parameter directly affects the TTW.
Alpha and Beta directly impact the generated word vectors, and their interaction and impact can be visualized in a surface plot.
In the first surface plot, we observe a minimum point at the intersection of a beta value of 0.15 and an alpha value of 0.275.
On the other hand, in the second surface plot, we find a minimum at a beta value of 0.15 and an alpha value of 0.075.
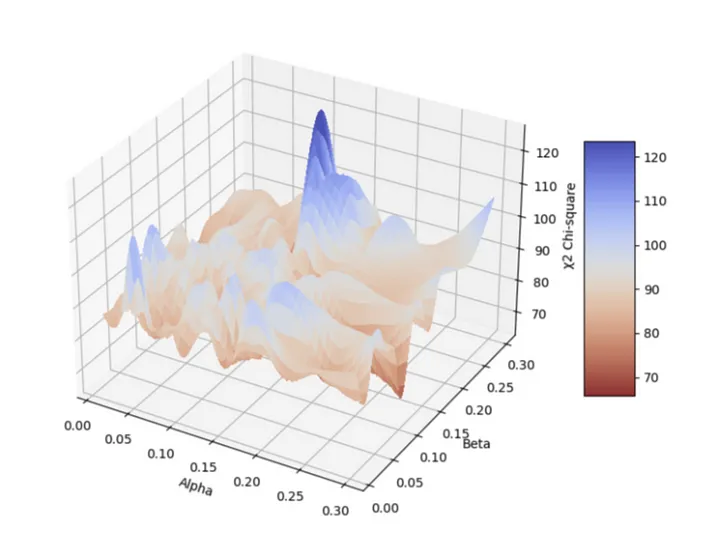
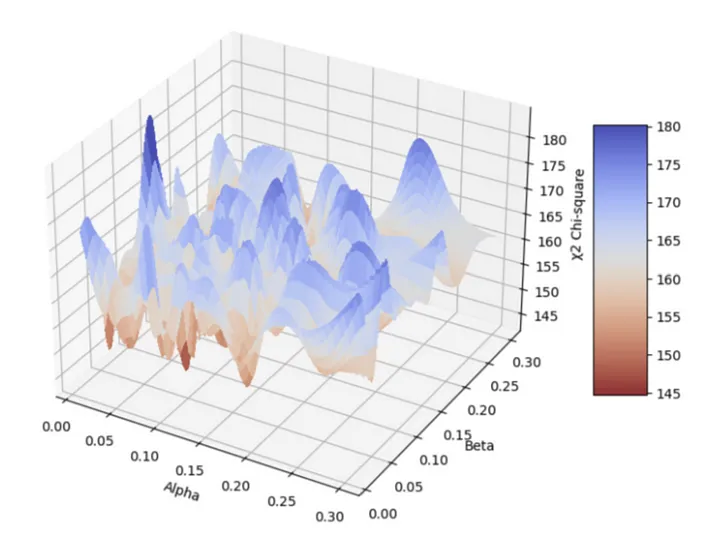
It’s important to select the Alpha and Beta parameters meticulously to ensure that the distribution of words, both real and estimated, closely align.
Limitations
The computation of Chi-square statistics stands as a useful method. However, its application to a vast datasets, consisting of thousands of lengthy documents, presents a significant computational challenge. To navigate this hurdle effectively, it’s important to use a strategic approach.
Optimize Workflow Location
Given the computational cost of Chi-square computation, it’s advisable to execute the process on a server or utilize platforms like KNIME Business Hub.
Alternatively, for expedited results, consider sampling the documents.
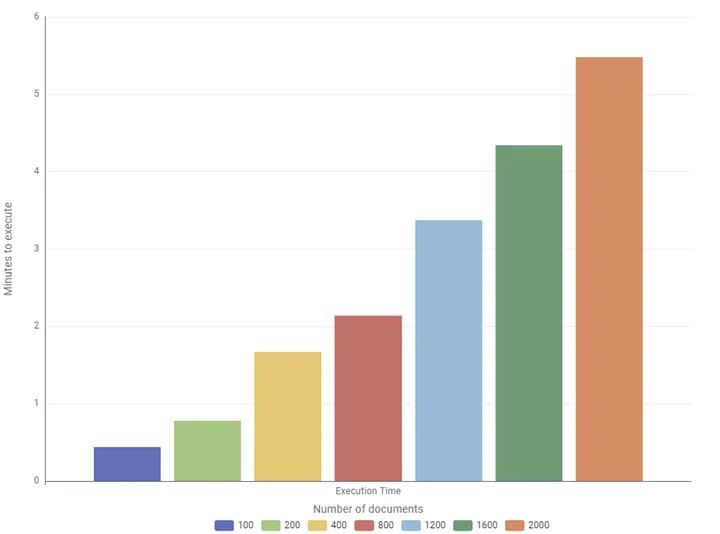
The following graph represents the computational time of the component to execute on an increasing number of lengthy documents, as you can observe, the computational time of a single Chi-square increases more than proportionally.
Currently, the component is in the experimental stage, but improving computational speed is a priority on my list of enhancements.
Tailoring Term Representation
A relevant aspect to consider is the number of terms displayed in the TWW matrix. This parameter is configurable within the LDA node.
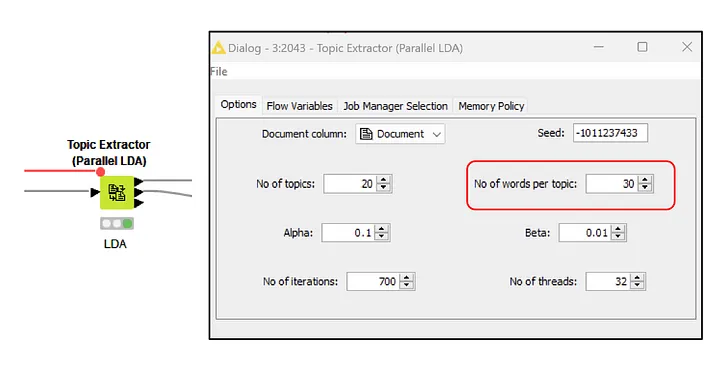
Although it doesn’t influence model estimation, it directly affects the number of terms available in the TWW matrix. For Chi-square computation, ideally, access to the full vocabulary is preferred. However, to maintain efficiency without compromising accuracy, setting the number of words to be >=15 ensures statistical scalability. Indeed, the Chi-square looks more stable as the number of words involved increases.
Conclusions and Benefits of Using Optop to Evaluate Your Topic Model
In summary, incorporating Chi-square statistics offers a statistically rigorous method for assessing the effectiveness of topic models like Latent Dirichlet Allocation (LDA).
This approach not only addresses the challenge of determining the optimal number of topics but also provides insights into model fit. The latter is a particularly difficult aspect to assess, especially within unsupervised algorithms like topic modeling.
Moreover, this metric offers the additional advantages of optimizing Alpha and Beta parameters, comparing models trained on different datasets, and evaluating the goodness of fit not only at the corpus level but also at the document level.
While Chi-square statistics provide a robust statistical framework for assessing topic model performance, they primarily focus on quantitative aspects, potentially overlooking the interpretability of topics.
To maximize the utility of this metric, it’s advisable to complement its insights with those obtained from other indicators, such as Semantic Coherence, which correlates well with human judgment of topic quality. This combination allows for a more balanced evaluation, incorporating both statistical rigor and qualitative interpretability. You can compute the Semantic Coherence by making use of the Topic Scorer KNIME Verified Component.