
Today, ask the majority of data scientists how many models they’ve productionized, and the answer is still, too often, not that many. The reality is that most organizations have no standard process for moving models into production – and data teams still face significant technical and bureaucratic hurdles to scale their insights. The majority of teams spend a month on productionization, with 30% reporting it taking over 3 months, according to a recent VentureBeat article.
However, peek behind the curtain at some of the most successful organizations in their field and you see a completely different picture. They’ve built out processes to efficiently create models, as well as automatically validate, test, and deploy them. With deployment taking minutes, not months, they are able to continuously improve a fully developed data strategy and thought-out data prep processes. They’re upskilling entire business units to self-sufficiently make sense of the data prepared for them. They’re regularly finding new, innovative ways to make use of cutting edge techniques – bringing prediction into both top-line impact in terms of revenue gains and risk reduction, and bottom-line impact in terms of efficiency and time savings.
So what’s the difference between most data teams, and the most prolific data teams? It’s the difference between forcing data scientists to serve as jack-of-all-trades, rather than building a cross-functional team and system for large scale production of insights.
The skills gap behind the status quo
The software industry has already developed a system for quickly and safely bringing applications into production. This discipline, known as DevOps, has been common practice for over a decade – so why can’t the data science groups use that? The answer has to do with a technical skills gap between IT professionals and data experts.
While data analysts and data scientists may have some coding expertise, they’re not experts in software infrastructure. On the other hand, while IT professionals understand the basics of data warehousing and accessing data, they’re not experts in building or maintaining analytical models. This gap is what results in what many call “throwing models over the fence.”
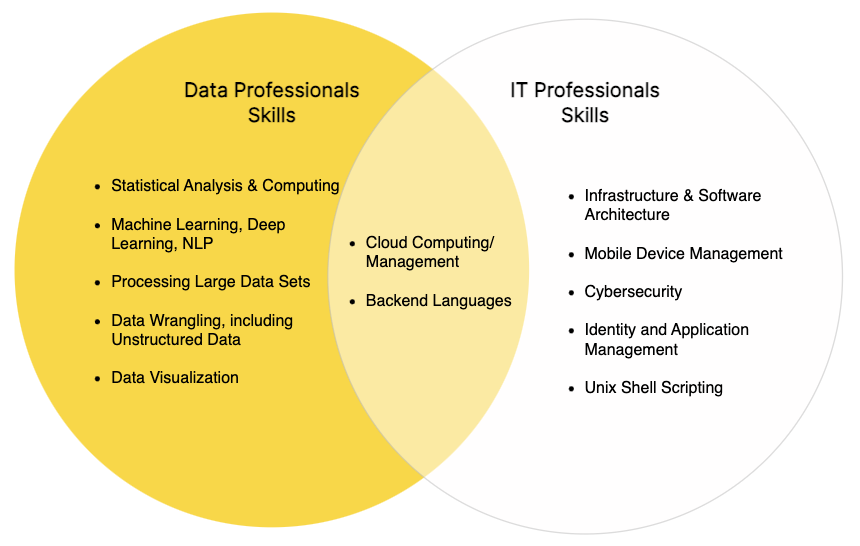
IT professionals are experienced in moving software applications into production – so they’re very familiar with testing, deploying, and monitoring. Whether they choose to use an end-to-end platform or piecemeal their tech stack, there are only small tradeoffs in complexity. However, when dealing with the distinct requirements of deploying data science applications, a brittle process or piecemealed tech stack has even more severe consequences – at best, delaying productionization, and at worst, compromising the integrity and value of the model itself. In the long term, it also adds significant complexity to model maintenance over time with several solutions being handled with different tools and approaches.
The result is that productionization is manual, time consuming and executed on a case-by-case basis.
Setting an end-to-end productionization process
Leading organizations and researchers have adapted DevOps practices to the world of data science and machine learning – a set of processes and tools known as ModelOps. Similar to DevOps, the process defines an end-to-end development process to design, build, test, validate monitor and manage updateable analytical models. (Note there are many variations of the term “ModelOps,” some being more specific, like “MLOps,” and others attempting to encompass software development of all levels of complexity with a term like “XOps, ” and more like “DevSecOps,” “AIOps.” Without writing a thesaurus, we picked one that was both recognizable and decently captures the idea.)
Defining your ModelOps process is the first step to moving away from ad-hoc solution building and accelerating time to value.
You can roughly define the phases, as follows:
-
Creating analytical models: A data team tests out various approaches to solve a problem with data, including applying different ML algorithms and advanced techniques. A portion of this work is, by nature, exploratory. Once they uncover the best approach, they test and validate their model on a historical data set, and then prepare to apply it to new, live data.
-
Integration: The data team (ideally) builds and tests the package that includes data prep steps as well as the steps of the process that apply the model to data. Testing involves not simply testing the software, as in a traditional application development process, but also again validating the model and making sure it’s producing the anticipated results.
-
Delivery: With help from IT, the data experts deploy their model to the target environment, and run either on a schedule or based on a trigger.
-
Monitoring: Data experts regularly ensure that their model is still achieving predictive accuracy. They monitor statistics on the accuracy of this model and make sure it meets a quality standard. Unlike in software engineering, where monitoring just ensures uptime, with analytical models, continuous monitoring is critical to ensure efficacy of the model.
-
Deprecating or re-training a model: Once a model starts decaying, you might choose to retrain and adjust the model or deprecate it entirely. Alternatively, models might be automatically retrained regularly.
In this process, it’s important that IT defines and implements the process, while the data team helps to ensure proper handover of both, the model (along with any data prep steps) and the monitoring and retraining mechanism. Here, you’ll need to define where the work of data scientists ends and IT begins. This way, the data team has just the right level of visibility and control over what happens in production.
An end-to-end data science platform, like KNIME, that addresses the needs of both data scientists and IT professionals, can significantly increase the speed of building and productionizing models. While IT can implement a process, data scientists can access, prep, build, test train and optionally deploy and monitor models, all in one platform. And with the entire process from data prep to model creation to deployment to monitoring to training/retraining happening in a single place, data and IT teams can manage multiple ongoing projects, easily work in-step and minimize the rework necessary to productionize a solution.
Automation equals maturity
Once you set and start using your standard deployment process – you’ll eventually be able to start automating it. According to Google, the more you automate your process, the more mature your ModelOps practice is. Here is where you’re able to scale the impact of data science. Many data experts are able to actually put their models into production without ever overwhelming IT. You significantly accelerate the time-to-value of any given model. And irrespective of your team size, you’ll gain the ability to oversee the deployment and monitoring of dozens or hundreds of models in production.
The recently launched Continuous Deployment of Data Science (CDDS) extension for KNIME Business Hub, empowers IT and data teams to define and automate all the critical steps of deployment. The extension enables teams to first automate integration–automatically creating a software package of the data pre-processing steps together with the model that’s ready for deployment. Then, the model can be automatically moved between environments, say from “dev” to “validation.” From there, teams can set up automatic testing and validation before automatically moving the model and all required pre-processing steps to production. Once the model is running, the team can further set up automatic re-training or deprecation, should the model discontinue to meet quality requirements. See an example of a process below.
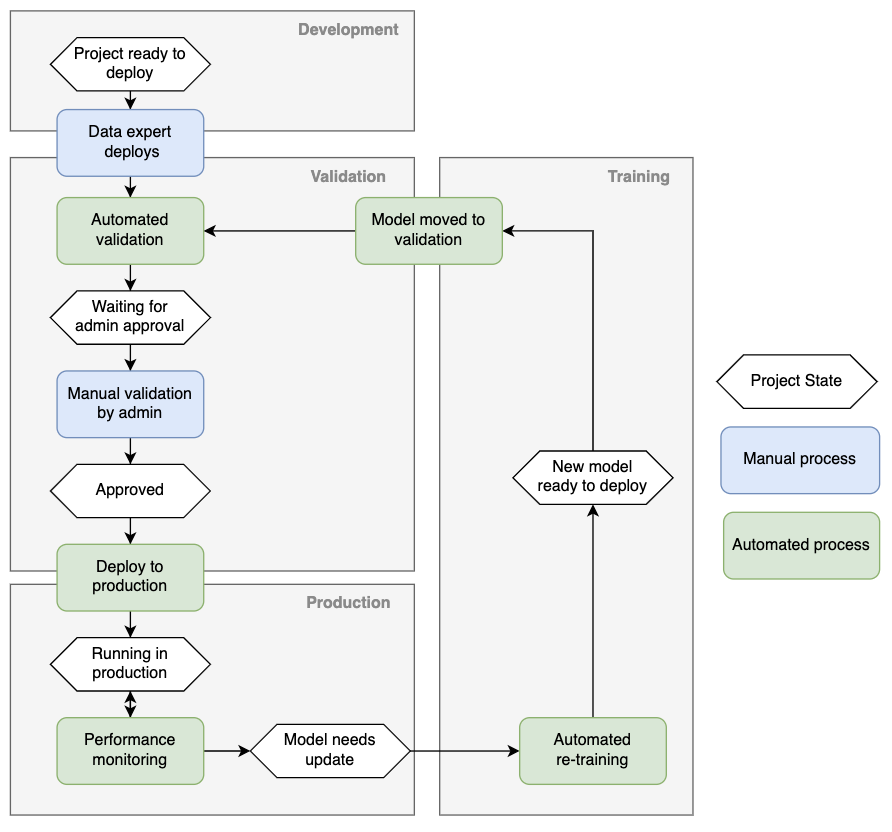
With KNIME’s CDDS extension, you can achieve the Continuous Integration, Continuous Delivery, and Continuous Training of any models. The extension is fully flexible: Define your own testing and validation steps as needed, set any number of testing stages, and automate as much or as little as you need. Execute locally, in the cloud or in a hybrid environment and choose to archive solutions in a database, Git, or anywhere else. Leveraging KNIME’s open platform, CDDS is extremely extensible, allowing you to hook into any existing tools or infrastructure, or re-design the process as you see fit.
Choosing a highly flexible, end-to-end data science platform
KNIME has always empowered users across skill sets and expertise to collaborate on creating and deploying data science solutions. On the creation side, KNIME facilitates collaboration between business and data experts; between data engineers and machine learning experts; between spreadsheet automators and database administrators.
Now, on the productionization side, KNIME empowers collaboration between IT and data professionals to truly scale the impact of their data science by defining and automating deployment. So deployment takes minutes, rather than weeks or months.