

AI - or Data Science if you prefer – has become mainstream. It is not a research niche anymore. Random Forests and Deep Learning networks are now available in libraries and tools, waiting to be applied to business problems and real-world data. This is so true that the focus of AI has now shifted from proposing new paradigms and new algorithms to engineering existing solutions via a standardized sequence of MLOps. When something moves away from research and becomes mainstream, other segments of the data analytics society claim access to it.
Can people who haven't learned how to code, like marketing analysts, physicians, nurses, CFOs, accountants, mechanical engineers, auditing professionals, and many other professional figures, successfully implement AI solutions?
Marketing Analysts and Sentiment Analysis
A friend of mine just started out as a marketing analyst. She has a statistics background, and no coding experience. Her first task was to implement a solution for sentiment analysis. As we all know, many options are possible here. You can go for an external service, you can implement a dictionary-based grammar-inclusive solution, or you can train a machine learning / deep learning model to distinguish positive from negative sentences.
External services are efficient and most of them are ready to go, but they have a price tag that does not really become cheaper with extensive usage. A dictionary-based solution seems easy at first, but it is actually quite complex to implement, because of the many grammar rules required to reach adequate performances. Eventually, she leaned towards the machine learning approach.
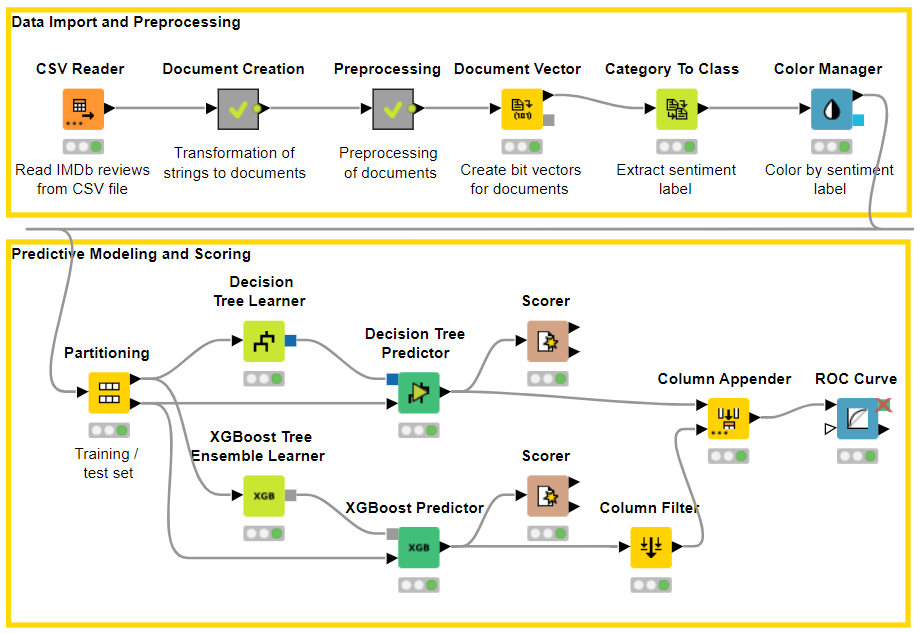
She quickly learned how to assemble data operations within KNIME Analytics Platform, which is open source and free. Then, she located two useful no-code workflows on the KNIME Hub: one using a decision tree (workflow: Sentiment Analysis using a Decision Tree) and one using a deep learning neural architecture (workflow: Sentiment Analysis using Deep Learning). Being somewhat more familiar with the decision tree algorithm, she downloaded that workflow, imported it into her KNIME Analytics Platform installation, and customized it to fit her own data.
The whole implementation took a few days: a worthy investment for a successful solution.
Auditors and Fraud Detection
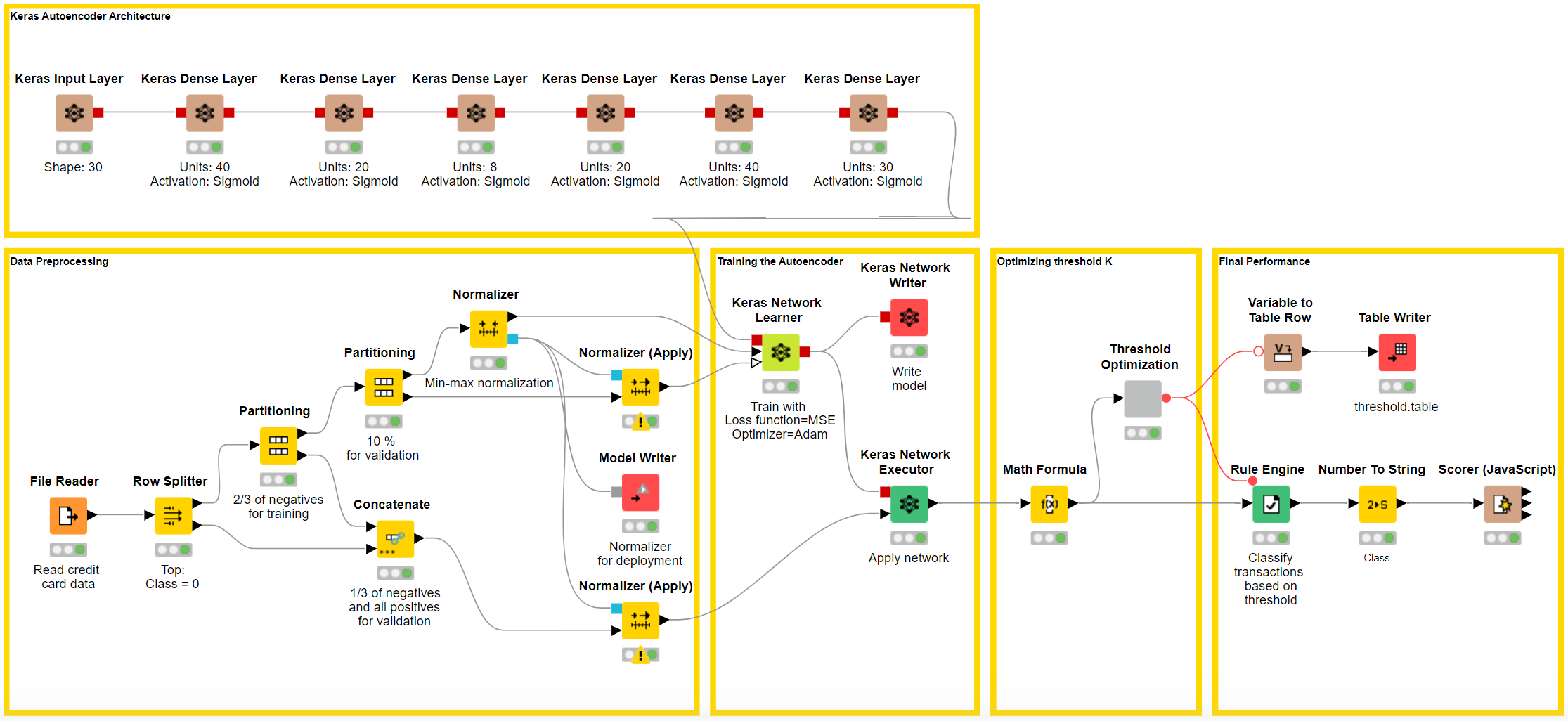
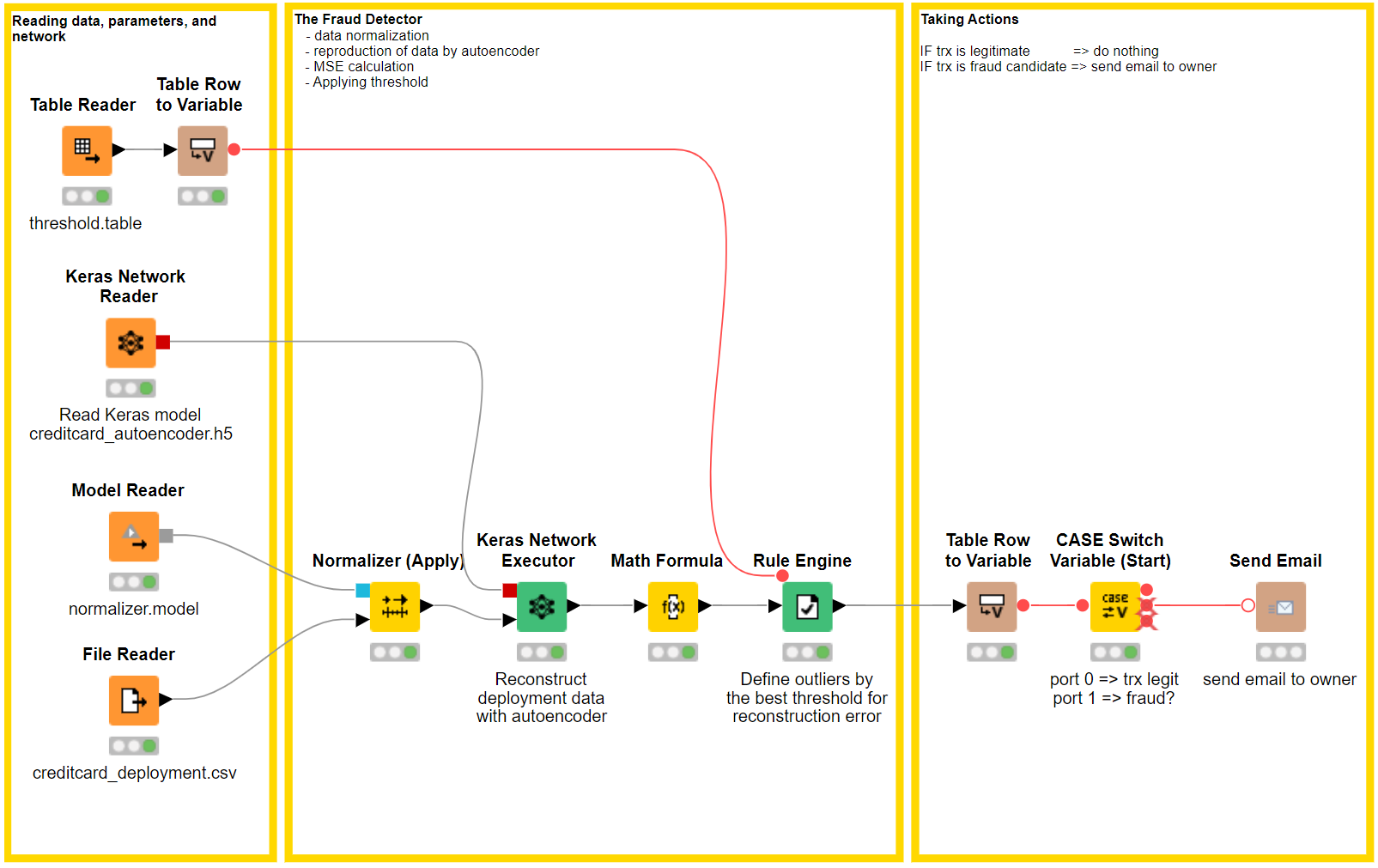
The second story is from an employee working in the anti-fraud department at a large bank. He knows about the potential of AI into fraud prevention, he has read tons about it. A promising approach, in case of missing fraud data, is offered by the neural autoencoder.
He has some coding skills, learned in college and in his first jobs. He can assemble a few lines of Python code, if needed, but cannot – and does not have the time to - really code a fully working reliable and robust data science application. All coders were absorbed by other, as usual more important, projects. So, he revolved to a low code approach.
This solution was less straightforward than the previous solution for sentiment analysis because it deviates from the classic machine learning schema of “data input – data preparation – train model – test model”. Once the overall concept was clear, the implementation of the prototype (workflows: Fraud Detection Model Training and Fraud Detection Model Deployment) was quite easy.
Notice that a variation of this approach can also be used for anomaly detection in IoT systems.
Operation Managers and Demand Prediction on a Spark Platform
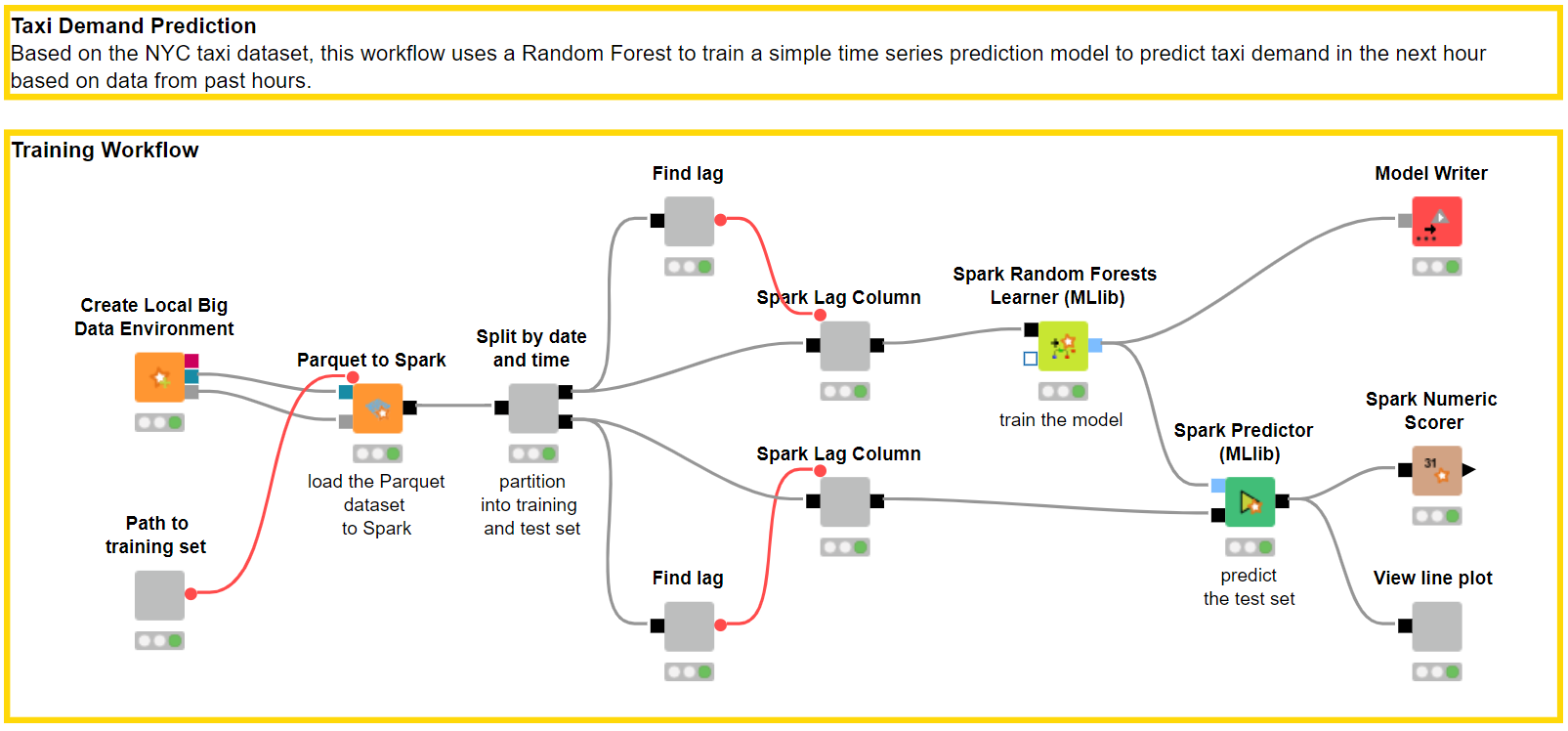
Another example is an operation manager of an electric distribution system. Here the imperative problem is to reliably predict the demand in energy. A common solution for demand prediction relies on time series analysis, using a number n of past values to predict the next value in the time series.
The operation manager employee has a background in Python coding and could assemble the solution herself. However, given the large amount of data, she needed to program the solution to run on Spark on a big data platform. This was a somewhat a new and specific way of coding that she needed yet to learn.
KNIME Analytics Platform makes access to external platforms particularly easy. All you need are the right credentials and everything else is handled by dedicated nodes. In this case, a full set of nodes dedicated to Spark operations turned out to be very useful.
Again, starting from a similar ready solution available on the KNIME Hub, designed for taxi demand prediction and running on a Spark platform (training workflow and deployment workflow), and taking advantage of the ease of use of visual programming, the operation manager could quickly produce the workflow to fit her own data and problem.
The Future of AI is Visual Programming
We have seen a marketing analyst implementing an NLP solution for sentiment analysis; an auditor developing a complex neural auto-encoder based strategy to trigger fraud alarms; and an operation manager building a demand prediction system for the Spark platform; all using a low code approach.
These people are all different professionals with different backgrounds and different degrees of knowledge in coding and AI algorithms. What they have in common is their need of quickly developing a data solution within an unfamiliar scope – coding, big data, or AI. Visual programming helped them to quickly achieve the right degree of expertise and to quickly adapt an existing solution to the data science problem.
Because of the current level of development of many machine learning algorithms, and because of the ease of use of visual programming-based tools, even non-coders, occasional-coders, or expert-coders in unfamiliar territory, can implement sophisticated AI solutions.
A word of caution. Codeless does not mean math-less. Some background knowledge of the mathematics behind the data transformation procedures and the machine learning and deep learning algorithms is needed for the correct implementation /adaptation of the desired solution.