
In this article, Rosaria Silipo, Ph.D., Principal Data Scientist at KNIME, explains the difference between automated Machine Learning and low code tools for data science. Rosaria is the author of 50+ technical publications, including her recent book “Practicing Data Science: A Collection of Case Studies.” She holds a doctorate degree in bioengineering and has spent more than 25 years working on data science projects for companies in a broad range of fields, including IoT, customer intelligence, the financial industry, and cybersecurity.
Low Code Tools
I have been running a number of interviews recently. When I explain to the candidates, at least to those candidates who do not know KNIME yet, that KNIME Analytics Platform is a low code tool for data science and that it uses visual programming to build a pipeline of actions to take your data from A (usually the data sources) to B (usually a trained model or a deployment application), I often get the comment “Ah! It is like a tool for automated machine learning.” No, it is not. It is a low code tool for data science.
Low code tools are becoming more and more popular. They allow us to perform certain tasks without the need to code. They are based on visual programming, that is on a drag & drop interface to build a pipeline of blocks, each block implementing a dedicated task.
There are many low code, or even no code, tools: for finance, accounting, reporting, project management, design, and so on. KNIME Analytics Platform is a low code tool for data science. Blocks are called nodes. Each node implements an operation on data – reading, accessing, aggregating, joining, normalizing, … – or on models – building, training, applying, optimizing, or scoring. Each node has a GUI dialog that exposes the operation parameters to set.
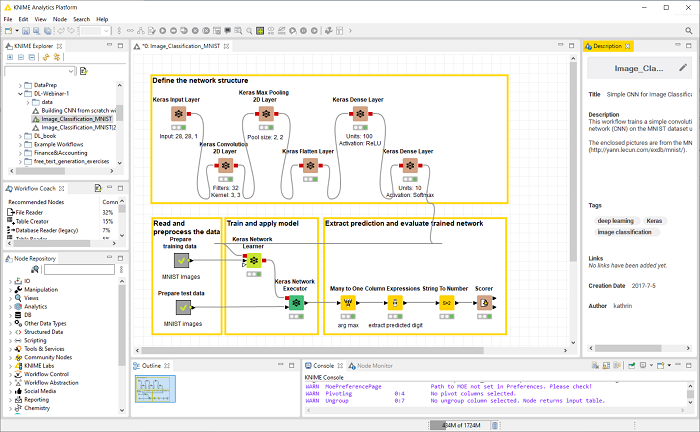
Specifically, nodes that train machine learning models expose the model’s hyper-parameters, to allow the data scientist to tweak and tune the model. In this sense, while KNIME Analytics Platform is a low code solution, it is not an automated Machine Learning tool.
Automated Machine Learning
Automated Machine Learning describes that set of applications that feed on data and automatically provide a machine learning model. They offer no, or very few, interaction options. The data scientist can only work on the input data and after feeding it into the machine has very little chance of influencing the final model.
What Is The Difference?
Automated Machine Learning is an entirely different business from low code tools for data science. Automated Machine Learning applications are confined to training machine learning models, in a fully automated way. Low code tools for data science, on the opposite, cover a plethora of different data science operations, from data transformations to machine learning algorithms, exposing many of the hyper-parameters involved in the definition of the model or of the transformation.
When using an automated Machine Learning application, you need to trust that the default settings that have been used fit your business case and data. Default settings are probably sufficient for simple well-conditioned problems. Default settings might run short when your business case requires a slightly different approach or when your data set does not cover all possible situations in a clean way.
When using a low code tool to train a machine learning model, you will have more flexibility. You can choose the architecture, try a number of different values for the hyper-parameters, optimize one or more of them, and in general run a few experiments on the data, the architecture, and the hyper-parameters before delivering the model to the deployment application. Low code tools remove the barrier of coding, but keep the freedom of experimenting.
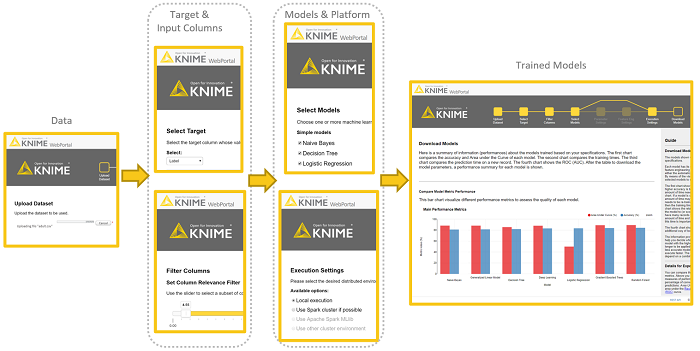
Automated machine learning and low code tools are also not mutually exclusive. You can build an automated machine learning solution using a low code tool. For example, my colleagues Paolo and Simon built one, using KNIME Analytics Platform, and named it Guided Automation. It consists of four main steps:
- Upload the data set
- Set the target and set the tolerance to less informative input features
- Select the machine learning models to train and the execution platform
- Inspect the performances of the trained models
You can find it on the KNIME Hub, download it, feed it with your data, run it, and see if the model it produces solves your problem well enough.
In summary, you can use a low code tool to develop an automated machine learning web application, but you cannot do the opposite.
As first published in InsideBigData.