
Many Life Sciences Discovery Informatics applications have to deal with some unpleasant combination of high data volume, high data velocity, and high data variety - the classic "3Vs of Big Data". While applications that combine high values for all three Vs are rare in the Life Sciences - High-Content Screening (HCS) and Next-Generation Sequencing (NGS) come to mind - you can always rely on your input data to be variable, either in terms of the input formatting, or in terms of of the input data structures, or both. Moreover, in the vast majority of cases the data volume is too large to be handled properly with a collection Excel files, so a robust IT infrastructure for storing and validating the incoming data is required. In short, the average Life Sciences Discovery Informatics application needs to be very nimble and very robust at the same time.
In this post, I want to outline an application architecture that fits this bill exceptionally well - namely, the combination of KNIME with a RESTful server.
KNIME and REST
KNIME is a powerful and extensible platform for data analytics based on the concept of data analysis workflows where data flows (mostly) in tables from one data processing node to the next. With a vibrant and rapidly growing community built around its Open Source development model, the KNIME platform now offers more than 1000 different processing nodes from a wide variety of data analytics disciplines such as text processing, network analysis, and cheminformatics.
The typical KNIME workflow follows an "Extract, Transform, and View" approach, i.e., data is extracted from various sources, processed through some fancy analysis algorithm, and then visualized, often in an interactive and iterative fashion. Less common, but equally easy to do with KNIME, are workflows that follow the widely known "Extract, Transform, and Load" (ETL) approach where the result data from the analysis are pushed back into storage for subsequent reporting, possibly in an entirely automated cycle.
With a classical relational database backend, the "Load" part of the ETL cycle in KNIME is typically implemented using the builtin database connection nodes to perform appropriate database inserts. However, accessing the database layer directly is notoriously brittle (think schema changes) and is also not looked kindly upon in corporate environments (think end users editing INSERT statements). A more elegant, robust and safe approach is to wrap the load operation in a web service and submit the data from KNIME through a web service call - and this is where REST enters the picture.
In recent years, REST has become ubiquitous as the architecture of choice for web applications. Key to this phenomenal success are the concept of URL-addressable resources, the statelessness and uniform interface of all client-server interactions, and hypermedia. Portal sites like Mashape and companies like Apigee are among the most visible examples for this new paradigm of web application development.
Example application
I would like to illustrate what the KNIME & REST dream team can do with a simple application that allows KNIME users to execute arbitrary command line tools remotely in a convenient and secure fashion. This is only meant to show the basics of what a KNIME and REST based application architecture can do and it deliberately skips many of the implementation and installation details; please refer to the links in the footnotes for further information.
The REST service for the remote command execution application is called "telex" (short for "tele-execution" [2]). It exposes only two top-level resources, a ShellCommandDefinition resource and a ShellCommand resource. A new shell command definition is created with a POST request to the ShellCommandDefinition resource. If the telex server runs at http://telex in your local network, the POST request would go to http://telex/shell-command-definitions with the following JSON request body [3]:
The server responds with a HTTP 201 Created message and sends a representation of the newly created command in the body of the response.
The echo command takes a single parameter, the text to be echoed. To create a parameter definition for this parameter, we next perform a POST request to the nested ParameterDefinition resource at http://telex/shell-command-definitions/echo/parameter-definitions with this JSON request body:
Again, the server acknowledges the creation of the parameter definition resource with a HTTP 201 Created response.
With the echo command now operational, to run it we perform one more POST, this time to the Commands resource at http://telex/shell-commands with this JSON request body:
Once the command finished, the server returns the new ShellCommand resource containing the exit code of the program in the exit_code attribute, the output captured from stdout in the output_string attribute and the output captured from stderr in the error_string attribute [4]. Note that the ShellCommand resource gives you a complete record of who issued which command at what time, including parameters and output, which can come in very handy the next time you are trying to run the same command (and can be queried any time with a simple GET request).
To perform these REST operations in KNIME, we use the KREST extension from the trusted KNIME community site [5]. A simple workflow for the interactions with the telex server described above could look like this:
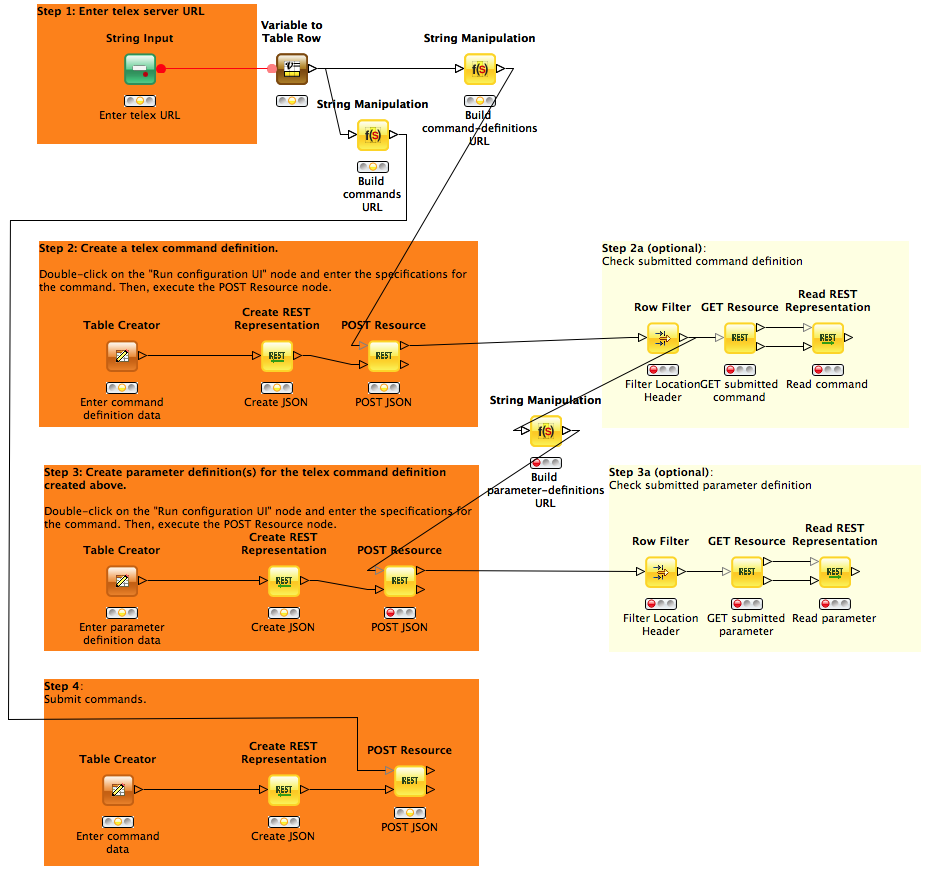
The user specifies the base URL of the telex service with the String Input node at the top and then composes the tables needed to generate the JSON representations for the desired command and parameter definitions using Table Creator nodes.
Manually entering data using the Table Creator node is not very user friendly, as the column names in the table must exactly match the attribute names in the resulting JSON representation [6]. To simplify this task, I wrote the Assisted Table Creator (ATC) node [7], which uses a RGG template to assist the user with a dialog for entering the parameter data. An RGG template is a simple text file; for example, the template for submitting an echo command as shown above looks like this:
During node configuration, this template is then translated to the following - very simple - data entry dialog:
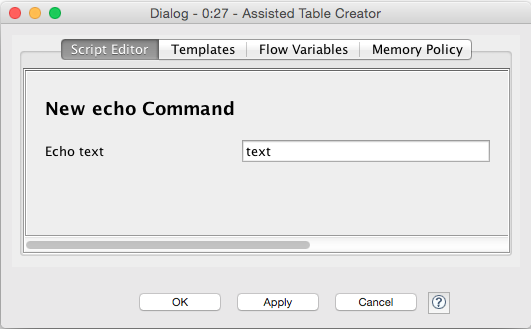
Once the dialog is closed, the output table is generated which in turn can be converted to JSON and submitted to the telex server as in the example above.
But wait, there is more: With the RGG plugin for the telex server, you don't even have to write these templates - they will be generated automatically for all telex commands. Technically, the RGG plugin just adds a new renderer which knows how to convert ShellCommandDefinition member resources into RGG templates. Once the plugin is installed, all it takes to make the telex commands available as auto-generated RGG templates in KNIME is to add the URL http://telex/shell-command-definitions/@@rgg in the preferences dialog of the Assisted Table Creator node [8].
The shell command execution API that the telex server provides is a very simple example demonstrating the power and versatility of combining a REST API with KNIME. Of course, the concept of passing parameters collected with an RGG template in KNIME as JSON payload can easily be transferred to calls into your own application server's REST API. For the adventurous, the telex server also provides RestCommandDefinition and RestCommand resources that allow you to define and execute such REST calls just like calls to shell commands. In such a setup, the telex server can act as a portal to well defined REST services for your KNIME users, all conveniently configurable through auto-generated RGG templates.
I better stop now to keep this short; hopefully, this overview has sparked your interest in teaming up KNIME and REST to solve complex discovery informatics problems!
Article Author: F. Oliver Gathmann
As a freshwater ecologist turned software engineer and data scientist, Oliver's intellectual curiosity has always been driven by a fascination with detecting structure in - and imposing structure on - data. Given this background as a scientist, Oliver has always focused on the data rather than the tools used to process them and his choices of programming languages, development frameworks and the like are pragmatic, if not always orthodox. The recent focus of Oliver's work has been on developing a RESTful data access and publication framework in Python and integrating that with the popular KNIME data workflow analysis platform.
References
This article was originally published on the Bits and Bases blog.
The service was implemented as an everest application and is available here.
The __jsonclass__ attribute is used internally by the telex server to infer the class of the POSTed object ("class hinting").
In the interest of brevity, I will skip discussing issues of error handling and timeouts with non-terminating commands here. The KREST nodes were developed at Cenix BioScience during a research project funded by the EU and the German Federal Ministry of Education and Research (BMBF). This includes a number of columns for internal use by the telex server such as the __jsonclass__ fields and dotted column names for nested attributes.
This node is based on the excellent MPI scripting nodes and is available from this Eclipse update site.
Provided you have the telex server including the RGG plugin and the ATC node set up, you can play with the workflow shown above after downloading it here.