
A short description of data analytics project formalization through some of the white papers developed over time here at KNIME AG
It is not hard nowadays to find talks from conferences and blog posts on the web claiming that data analytics, or data science as it is now called, can do wonders for your company. Sure! However, identification of the relevant problems and their formalization into available data vs. the desired output remain the biggest obstacles to a realistic implementation of any data-driven project.
Indeed, the most important part of a data analytics project is always at the beginning, when the problem to be solved is selected and formally defined. Problems usually are many. How do we select the most remunerative and the least work intensive?
I encounter this blockage often when I’m out giving presentations and discussing data analytics strategies. So, I thought, it might be useful to describe the path followed in some past projects. Of course, the ones presented here are actually just a subset of the many solutions built and refined with KNIME Analytics Platform.
You can find them
- on the KNIME Hub in the 50_Applications folder,
- or in the web page dedicated to whitepapers
1. Classic CRM Analytics: Churn Prediction and Customer Segmentation
Let’s start from the easiest, traditional, data analytics problem: predictions based on CRM data.
For long time now, CRM data have been the basis for a number of data analysis and prediction applications, which are now handbook use cases in the field of data analytics for marketing and sales.
Churn Prediction
A very classic use case based on CRM data is churn prediction. The task: to calculate the likelihood of new customers churning – based on an existing data set of past customers, where some customers have renewed the contract (no churn) and some have not (churn). Implications are clear. When a customer calls the call center, maybe to complain about something, the call center operator retrieves the customer’s data and can see his/her likelihood to churn. Depending on that value, the call and any subsequent action can take very different paths.
Given the existence of a dataset with past examples (the CRM), this problem is easy to solve using any classification technique, from a basic one like a decision tree to more sophisticated techniques such as ensemble methods, from a simple model to an optimized model. In our project first we built a very simple model, using a decision tree (captured in this YouTube video), and later we switched to better performing models, such as a random forest, and optimized the model parameters.
Notice that all problems with a set of existing examples and requiring the prediction of one of the variables, like a credit score, a product propensity, or the probability for an upsell, can be solved in the same way.
The description of the solution workflow for churn prediction can be found on the on the webpage, Churn Prediction use case (not the Churn Analysis use case).
Customer Segmentation
Another classic use case based on CRM data is customer segmentation. Here the goal is to separate the different customers in groups, based on one of the three following strategies:
- a rule system directly generated from the business knowledge,
- a binning system along one or more variables, such as demographics, revenues, or behavioral measures,
- a clustering technique, if we do not want to or cannot use any pre-existing knowledge.
In customer segmentation there is no prediction or likelihood, just a grouping of data on the basis of different criteria.
To translate pre-existing knowledge into a rule system, a Rule Engine node might suffice. For binning, many binner nodes, with more or less automatic procedures, are available in KNIME Analytics Platform. Finally, for clustering we can use one of the many clustering techniques in KNIME Analytics Platform, such as k-Means.
The analytics part of this project is relatively easy. We can then devote our work to foster better collaboration between data analysts and their counterpart, the business analysts. In modern data analytics projects, cooperation between who knows the algorithms and who knows the data has become vital.
Thus, we transferred the customer segmentation workflow to KNIME WebPortal. Quickform and Javascript nodes encapsulated in wrapped nodes create a web-based GUI on the WebPortal to expose only a subset of the workflow parameters and to allow the business analyst to interactively investigate the customer segments conveniently from a familiar web browser.
The whole approach is described in the whitepaper “Customer Segmentation Comfortably from a Web Browser”. The workflow is available on the KNIME Hub, Customer Segmentation Use Case
Figure 1. Content of wrapped node and corresponding web-based GUI generated on the WebPortal. Notice the Quickform nodes in gray and the Javascript nodes in light blue.
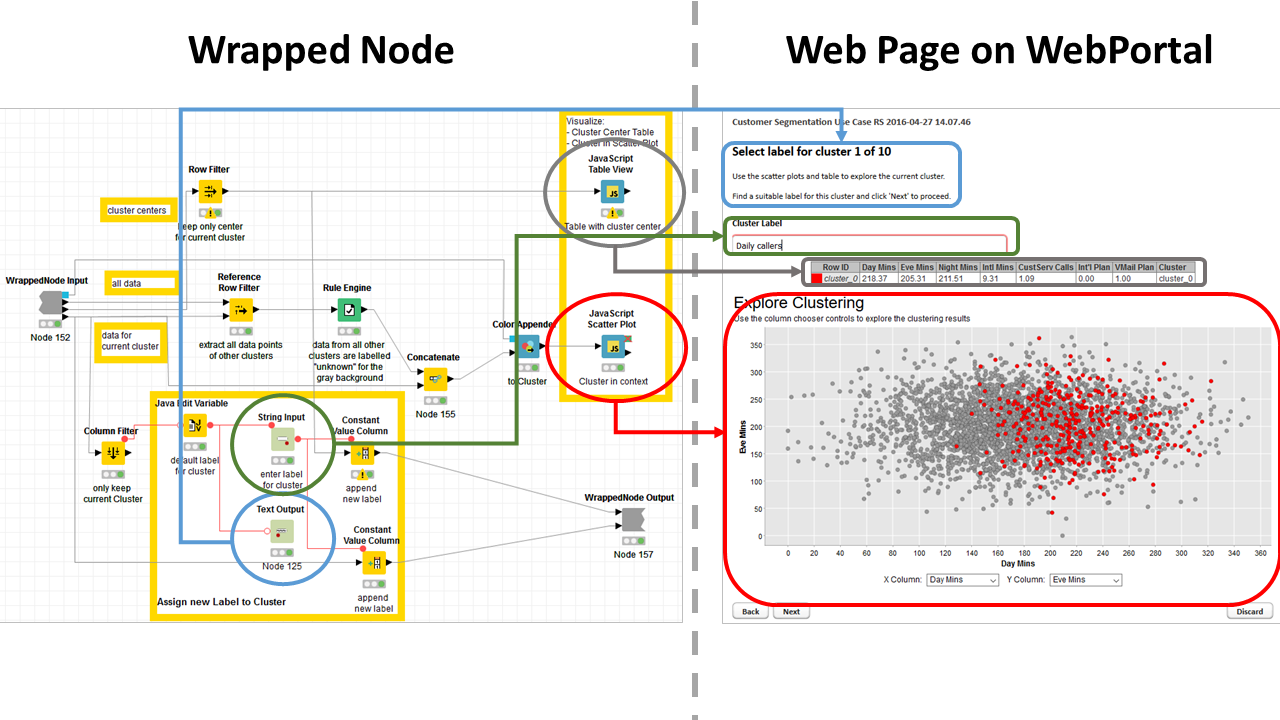
(click on the image to see it in full size)
2. Expand your Data: Customer Intelligence on Social Media
Then came the Internet, with its web pages and the social media and an amount of data out there that made your CRM look like a tiny and rather lonely data set. The evolution of analytics on CRM data involves enrichment with data from social media.
Facebook, LinkedIn, and Twitter are the usual suspects we turn to when we want to expand our customer data. With the exception of Twitter, the other social media platforms need explicit authorization from the customer to access his/her Facebook or LinkedIn data. Now, we do not really want to know all the details of his/her private life; we are more interested in what he/she thinks about the products and the services we are supplying. So, we only access our own Facebook and/or LinkedIn page and import all comments from users and customers. These days many companies also provide a forum where customers can voice their satisfaction or discontent. Users in a custom forum are already known customers and their feedback can be recorded and tracked easily.
New data also mean new data types; new data types require new analytics techniques; new analytics techniques usually bring new wisdom to append to the existing results from the traditional analysis of CRM data.
In case of a forum, we are dealing with posts and comments (text data type) and connections (network data type). The general customer sentiment about a certain product or service can be retrieved from the content of the posts; examining the exchanges with the customer’s connections in the forum (or on any other social platform) his/her leadership can be quantified. Both new features, leadership and sentiment, can be added to the classic attributes used for example in traditional CRM data analytics.
We discussed this same problem in the whitepaper “Usable Customer Intelligence from Social Media Data. Network Analytics meets Text Mining” (White Papers, section “Social Media”). The upper branch of the workflow translates the post and comment exchanges from the forum into a network graph and calculates the centrality index of each forum member. The centrality index is then used to define the degree of leadership for each forum user. The lower branch of the workflow identifies all positive and negative words and based on that calculates the total sentiment (or attitude) for each forum member.
Figure 2. Workflow of Customer Intelligence. Network Analytics meets Text Mining. Upper branch is for network analytics and visualization. Lower branch is dedicated to text mining.
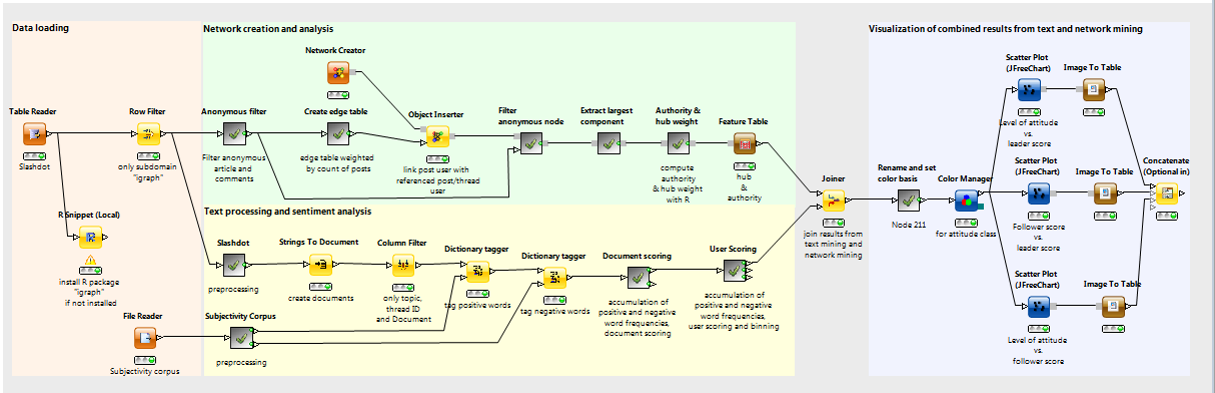
(click on the image to see it in full size)
Forum members are then displayed as points on a scatter plot with coordinates as (follower score, leader score) and color coded by sentiment (green=positive, gray = neutral, red = negative). The idea is that marketers and customer support save time and money by taking care of the most influential complainers, rather than the loudest ones.
Figure 3. Customers as points in the (leadership score, follower score) space and color-coded by sentiment (green = positive, gray= neutral, red = negative)
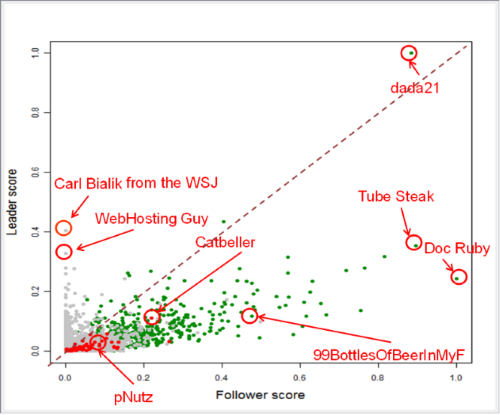
3. Social Media for User Experience: Twitter and Online Dating
Now that we have opened the gate to the flood of social media, we have a plethora of data ready to use. Working on the same data (social media) with the same techniques (text processing and network mining) as in the previous section, suddenly a number of new data analytics investigations becomes possible. For example, by just slightly changing the follow-up actions, we can move from a customer care scenario to a user experience evaluation use case.
In a post on the KNIME blog from Jan-12-2015, named “Using KNIME to find out what your users are thinking”, Cathy Pearl analyzed freely available tweets to evaluate the user experience for online dating platforms. Three online dating platforms had been singled out: Tinder, OKCupid, and eHarmony. Tweets about any of these three platforms were then retrieved weekly.
Word Cloud visualization already showed the different demographics segments served by each platform. A more colloquial slang-like internationalized English was to be found on Tinder, indicating a younger more international user base; by comparison, OkCupid and eHarmony users were more likely to tweet about children and marriage indicating a more age-wise mature segment of society.
Topic detection on all weekly tweets across many weeks led to topic trend across time, uncovering localized incidents about stolen phones, fake appointments, or less than politically correct comments.
Figure 4. River Theme Plot of topics detected over time on tweets about online dating.
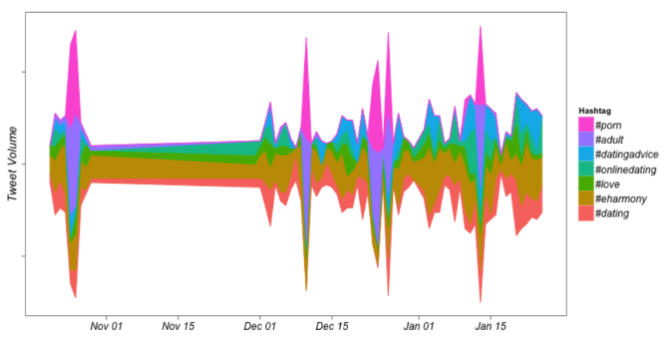
4. From Tweets to Bike Numbers Restocking Strategies
Enough with people! Let’s talk about goods. A classic problem in supply chains and rental businesses is to have sufficient quantities of goods, but not too much.
In this project we worked on data from a rental bike business in Washington DC. The problem of the rental bike business, like any other rental business, is to have enough bikes available at the rental stations to satisfy the demand and, at the same time, to have enough free parking spots available to efficiently deal with returns. This is not only a customer satisfaction problem. As a transportation business, a monetary fee is due if bikes or free spots are not available at a station for longer than a pre-defined time.
The challenge here was to devise a warning system to predict the need for bike restocking at a station at least one hour in advance. The data provided to us included tracking of the bikes as well as monitoring of free and occupied spots at the rental stations on an hourly basis.
In the spirit of the times, where more is better, we assumed that the available data was too meagre to make a reliable prediction and we decided to blend it with a larger amount of related data collected from the web. Thus, the data describing the bike flow was integrated with station elevation, calendar information (business day vs. weekend), weather information, traffic information, and past ratio between the number of free spots and the number of occupied spots at the station during the past 12 hours, for a total of circa 30 input attributes. All external information was retrieved from the web, mainly from the wide number of Google API REST services. The last column in the data set contained the flag Y/N indicating whether a bike restocking took place during that hour.
A classical prediction algorithm, a decision tree, was trained to predict the need for restocking each station at each hour using all the input attributes. With just this decision tree we reached ~75% accuracy on the test set in comparison with the human decision for bike reshuffling. We used a decision tree, but we could have used a random forest, for example, for better accuracy. However, the issue here was not only a high accuracy, but also the evaluation of our effort in data blending.
While data blending is very easy inside KNIME Analytics platform, too much irrelevant data can worsen the algorithm performance and still slow down the model response. With this goal in mind, a backward feature elimination procedure was executed to find the optimal model performance with the smallest number of input features. It turned out that the best accuracy (81%) was gathered with only 4 input features: hour of the day, calendar information, station ID, and spot-to-bike ratio in the last hour. Weather, traffic, and more remote past information had no influence on the model performance or made it even worse.
Lesson learned: blend your data as much as you want but keep an eye on performance. More is not always better!
Figure 5. Summary screen of the Backward Feature Elimination procedure. The lowest error rate on the test set (0.18) is found when using only 4 of the input feature set: hour, workingDay, Terminal ID, and current bike ratio to predict the need for restocking in the next hour at that station.
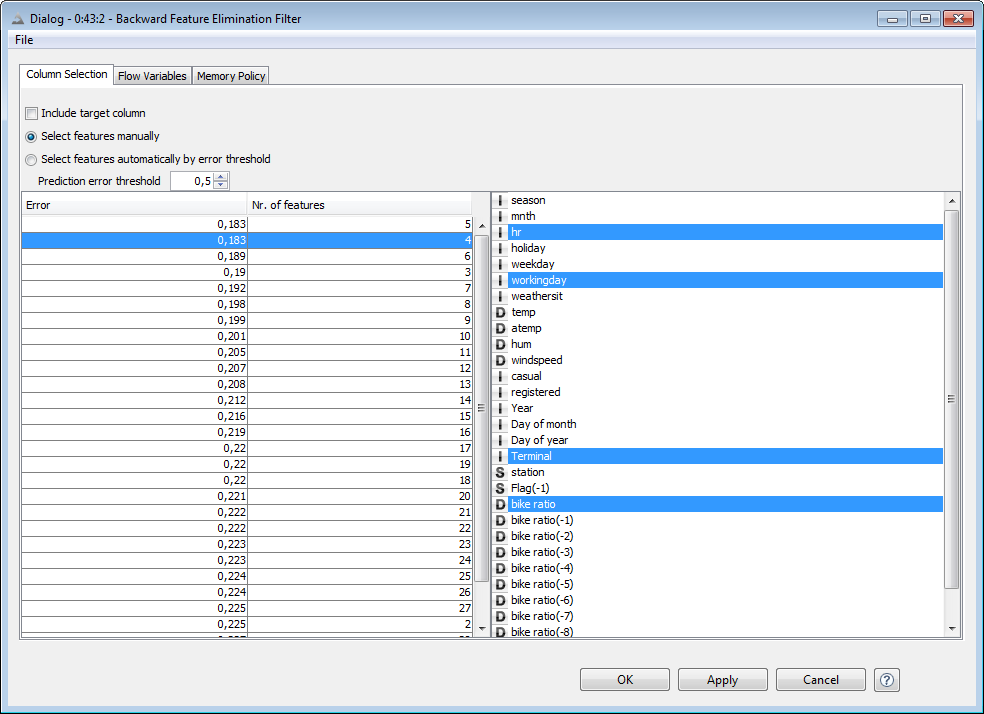
(click on the image to see it in full size)
Details about the solution of this use case can be found in the whitepaper named “Taming the Internet of Things. Data Enrichment, Visualization, Time Series Analysis, and Optimization” and downloadable from White Papers in section IoT.
5. The Ultimate Challenge: No Examples. Anomaly Detection in Predictive Maintenance
I have reserved the most creative use case for last: anomaly detection in predictive maintenance. Anomaly detection is a general problem with many different nuances in the maintenance of mechanical pieces. We refer here to the case where a dataset with only data related to the normal functioning of a mechanical piece is available. The problem then was the following: we had data describing the system in normal functioning conditions, but we wanted to predict the next failure.
Traditional prediction techniques, as we have discussed for restocking or churn prediction, could not work here, since an anomaly class/flag was not available. We needed a shift in the analytics perspective to get any kind of results.
The solution implemented a predictor for the normal functioning data using a linear regression on a number of past values to predict the current signal value. This was possible, as the data for normal functioning were available in abundance. Beware though that any model thus trained can only predict normal functioning values.
The second step consisted in calculating the difference between the signal values measured by sensors on the mechanical piece and the signal values predicted by the model. If the part was working normally, such differences would have been negligible. However, if something in the underlying system had changed, the difference would have been noticeable. In addition, if such a difference persisted over time, the system behavior could be interpreted as even more suspicious. In this last case an alarm would be triggered informing who is responsible for the correct functioning of the machine about some possible anomaly. That did not necessarily mean that the anomaly was malignant, it was just a warning. It is always better to be safe than sorry!
The alarm trigger function could be tolerant and only trigger the alarm for very high errors in non-critical business or be very restrictive and fire the alarm even for very small deviations for more critical business, like medical equipment, for example.
The figure below plots against time the cumulative alarm signal calculated across a number of sensors monitoring different parts of the mechanical piece. In this dataset the part breakdown happened on July 21, 2008. Early signs of failure (anomalies) could be seen as early as March 22, if we are strict, or as early as May 6, if we are more relaxed.
The details of this project are described in the whitepaper named “Anomaly Detection in Predictive Maintenance Anomaly Detection with Time Series Analysis” and downloadable from the whitepaper page in section IoT. The corresponding workflow is available on the KNIME Hub under Anomaly Detection, Time Series Analysis
Figure 6. Plot against time of an alarm signal for anomaly detection calculated across an array of sensor signals. Breakdown was to happen on July 2t. Signs of anomalies are clearly visible as early as May 6.
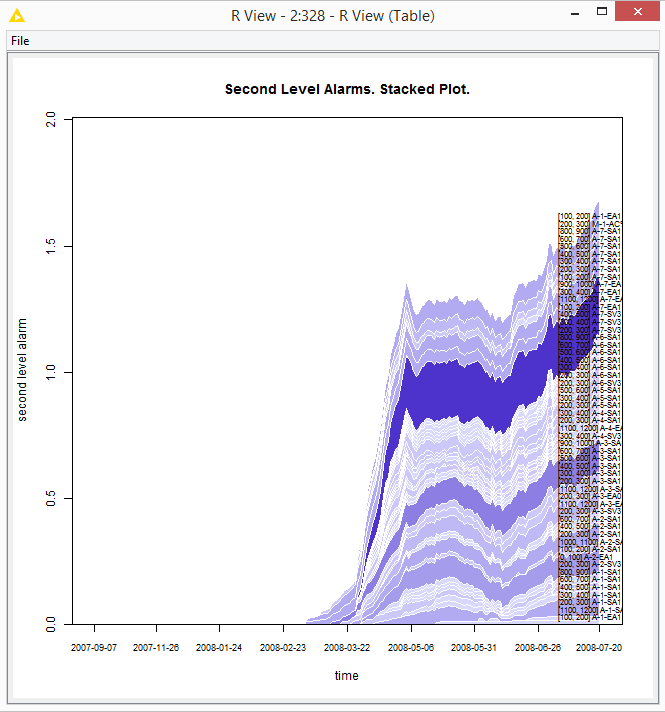
(click on the image to see it in full size)
6. Conclusions
In this short review of some of the use cases developed here at KNIME, I wanted to show how starting from the solution of very traditional and consolidated use cases, like churn prediction on CRM data, and only slightly changing the goal, the perspective, or the analytical frame, we were able to solve a number of other very different problems.
While the analytics techniques are relatively well defined, the definition of the business problem in terms of goals and data is often the fuzziest part of the project, because it requires both business knowledge and experience in the data acquisition process.
Following our experience, we often advise taking the time at the beginning of each project to clearly define the project goals, constraints, parameters, and, most important of all, the milestones. A clear design of the project allows also for a realistic interpretation of the results, besides a realistic estimate of the required implementation times.
Sometimes, you just need to add a bit of imagination to what you already know.