
In a world in which technology is constantly evolving, state-of-the-art large language models (LLMs) for human-like text generation look to be game-changers in analytics. In late 2022, one such model, ChatGPT, took the data community by storm, becoming the go-to solution for people seeking answers to all sorts of questions, from homework assignments, to code snippets, or just to satisfy curiosity.
ChatGPT and similar LLMs can provide fairly accurate, comprehensive and well-argumented answers in a matter of seconds. With their ability to understand and respond to natural languages, how can we use these models to our advantage and find answers to popular questions on the internet? Can they provide better answers than humans?
Who is Better at Answering – Human or Machine?
To find out whether humans or machines are better at answering, we will use KNIME Analytics Platform to build a workflow that uses GPT-3 — more specifically, its “text-davinci-003” model — to answer the ten most frequently asked questions on StackOverflow, a question-and-answer forum monitored by humans.
GPT-3 stands for “Generative Pre-trained Transformer version 3.” It is a large autoregressive language model (175 billion parameters) with a decoder-only transformer network. Released in 2020 by OpenAI, it uses deep learning to understand and generate human-like responses in natural language. GPT-3 was trained on an extremely vast text dataset from multiple sources, including Wikipedia and books. Given a text input, it can produce text which continues the prompt on a wide range of topics, making it a versatile tool for many industries.
StackOverflow is a question-and-answer forum focused on programming and software development. Users can ask and answer questions, use tags, and express appreciation by upvoting entries. By means of vote counts (both for questions and answers), users determine the popularity and relevance of each post. Usually, the most-upvoted answer is considered the most useful one. Users whose answers are often upvoted receive status badges, and can build good reputations in the community.
Both these sources can be accessed and interacted with from their respective REST APIs, using mostly GET or POST methods. To connect to REST-ful web services using KNIME Analytics Platform, we download and install the KNIME REST Client Extension from the KNIME Community Hub.
Topic. Getting and Posting API requests to exchange information with REST-ful web services
Challenge. Compare how humans answer questions vs. a state-of-the-art LLM
Access Mode. KNIME REST Client Extension, KNIME JSON-Processing
1. Blend GPT-3 & StackOverflow
The first API we call is the StackOverflow API, powered by StackExchange. It allows one to retrieve questions, which are sorted in descending order by the number of votes and from a user-defined date of posting. We can use this API to get a wealth of information about popular questions and answers on StackOverflow, including title, body, tags, score, and more. The second API is the OpenAI API. It allows access to GPT-3’s “text-davinci-003” model for text completion and generation. “Text-davinci-003” is the most powerful version currently available (as of Feb 2023), and it includes training data up until June 2021.
2. Retrieve Top 10 Questions from StackOverflow
In the lower branch of our KNIME workflow, we start off by retrieving the top 10 questions by total number of votes from StackOverflow.
3. Issue GET Request to StackOverflow API
We issue an HTTP GET request to the API using the GET Request node. Conveniently, the StackOverflow API does not require any API keys to retrieve questions or answers from the database. In order to send a GET Request, you need a valid URL with specifications and the KNIME REST Client Extension. The URL specification may vary according to what we are interested in. For our experiment, we use the following URL:
Let’s dive into each part of the URL:
-
2.3 denotes that we use version 2.3, the most recent iteration of the API
-
oder=desc denotes that questions will be sorted in descending order
-
min=1000 denotes that only questions with at least 1,000 votes will be included
-
sort=votes denotes that questions will be sorted by the number of votes
-
fromdate=946684800 denotes the Unix timestamp for January 1, 2000 at 12 am, so we represent this specific point in time as a single number and start our query from this point onward
-
site=stackoverflow denotes that questions will come from StackOverflow, and not another StackExchange website
If the GET request is issued successfully and without errors (code status: 200), the API returns a response in JSON format.
4. Parse JSON Response
Responses in JSON format have a well-defined structure, which makes it easy to interpret and parse useful pieces of information. We can preview and extract relevant values from the JSON response using the JSON Path node. These values are added as collection queries, converting the results into lists of different values. The lists are then disaggregated into several rows using the Ungroup node. Finally, we use the Table Manipulator node to retain columns containing the user name, avatar image, and profile URL of the person who asked the question, the question text and URL, the number of votes, and the ID of the most upvoted answer for further processing.
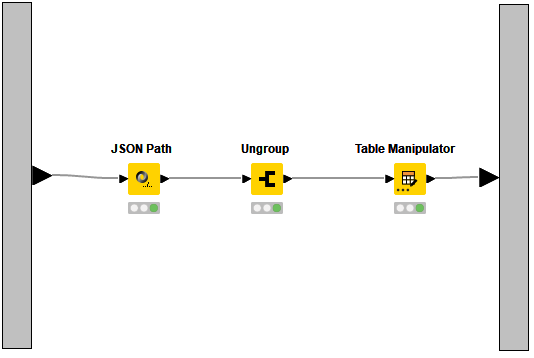
Note. We use this combination of JSON Path, Ungroup, and Table Manipulator nodes several times in our workflow to process the JSON response of the APIs from different requests.
5. Process Texts for GPT-3 and Keep Top 10 Questions
Before we can feed questions to GPT-3, we need to perform some text processing. Questions on StackOverflow often include special characters that are not straightforwardly recognised and converted in the JSON response. As a result, the retrieved question text may contain HTML entity numbers instead of the actual characters. To convert HTML entity numbers into their equivalent characters, we use a line of Java code in the Java Snippet node.
Next, the Column Expressions node converts some string values into integers and embeds links for specific columns. Finally, the Top k Selector node is used to filter the top 10 questions sorted in descending order by the number of votes.
6. Get the Answers from StackOverflow
To be able to compare human vs. machine answers, we also need to get answers from StackOverflow. To do that, we build a URL that contains the answer ID (we obtained it when we retrieved questions) and issue a new GET request to the StackOverflow API. In this case, we are not interested in the actual answer text, as this can be very verbose. Rather, we want to get the direct link to the most upvoted human answer for each retrieved question. We parse the JSON response in the same way we did above, and also extract the username, avatar image, and profile URL of the person who provided the answer, along with the number of votes the answer received.
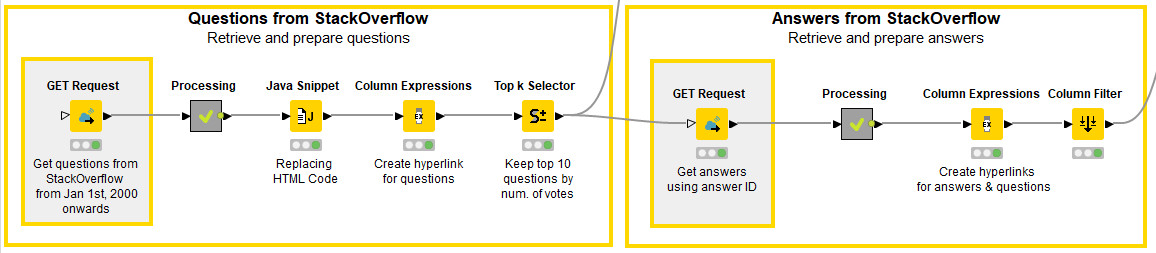
7. Get the Answers from GPT-3
Now that we have the top 10 questions from StackOverflow, we can use the OpenAI API to feed them to GPT-3 and let “text-davinci-003” generate answers for us.
Authenticate with OpenAI and Select Model
To authenticate with the OpenAI API, API keys are utilized. An account at https://openai.com/api/ is required to get access to API keys. When you are logged into your account, visit the “API keys” page. Once you get your key(s) from there, you can simply enter it in the “Provide API key” component and select “Close & Apply.”

The OpenAI API offers the possibility to choose among different models, each with different capabilities, accuracy, professing speed, and pricing. We choose the most powerful model that is currently available: “text-davinci-003”.
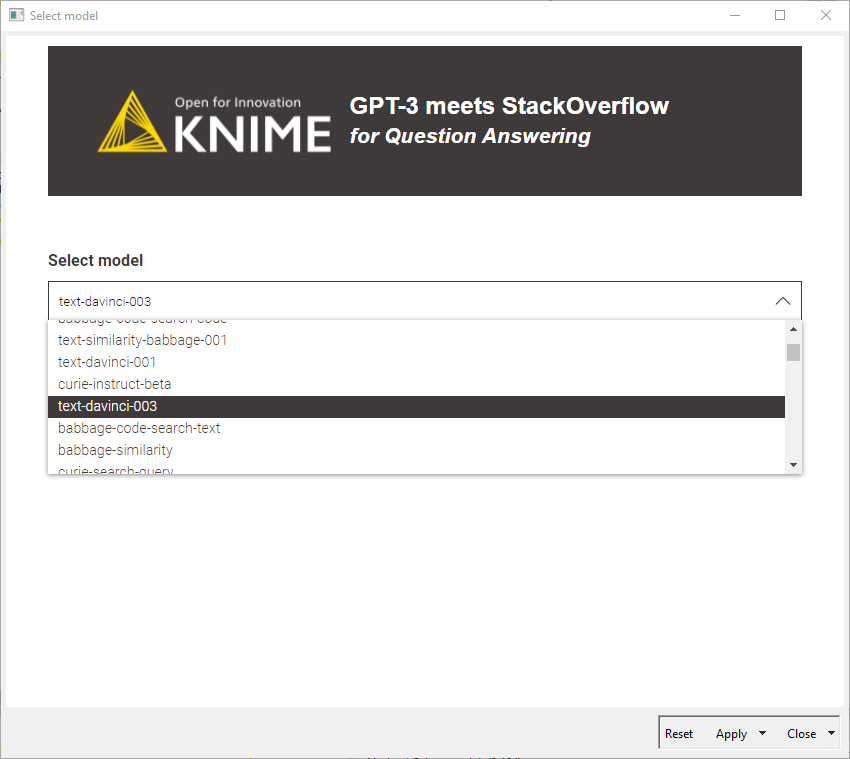
8. Issue POST Request to Interact with text-davinci-003
To interact with “text-davinci-003” and let it generate answers starting from a prompt, we need to issue a HTTP POST request to the API using the POST Request node. To do that, we need:
-
A valid URL with specifications
-
The KNIME REST Client Extension
-
Authentication with an API key
-
A request body in JSON format
The POST Request node requires a constant URL that we use to access the API. Since we want the model to generate text whenever a prompt is provided, this is the URL we use:
Next we need to make sure our API key is fed into the POST Request node to enable access to the web service. To do that, we pass the API key as a flow variable in the “Request Headers” tab.
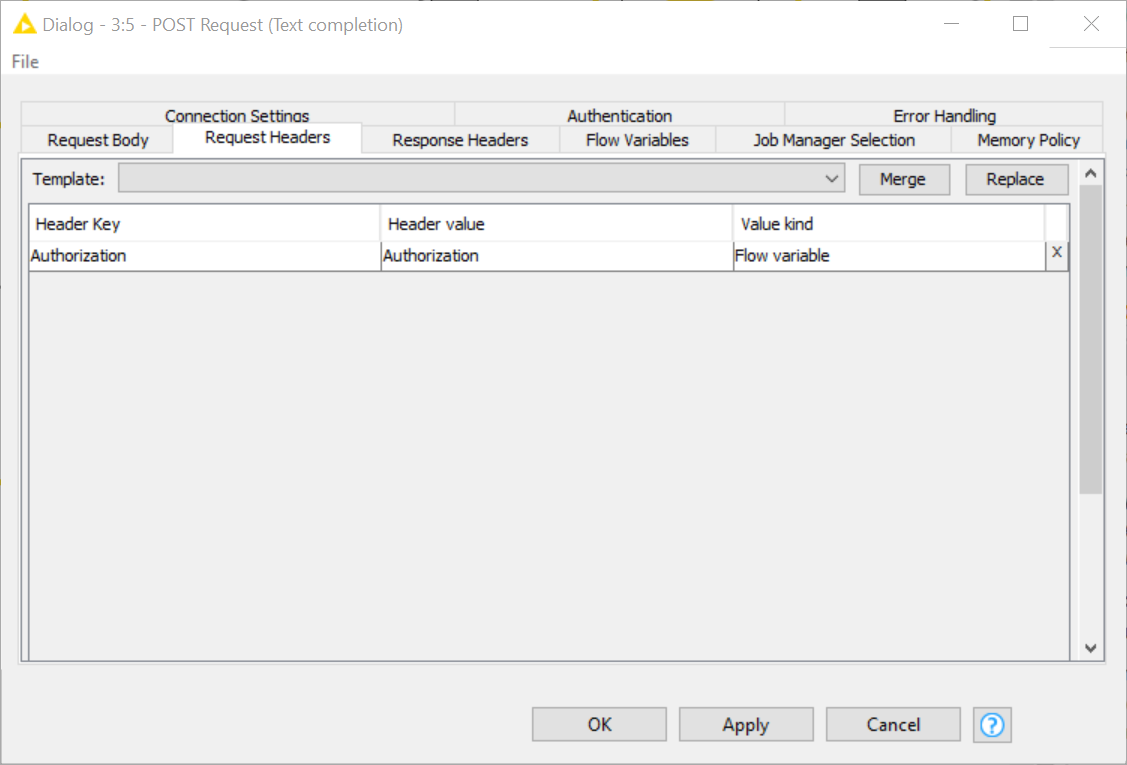
Finally, we need to specify a request body in JSON format in the “Request Body” tab. Because the model selection and prompt value change according to the user preference and question, respectively, we can’t use a static body. Rather, we pass a table column that contains a custom request body for each question prompt. To do this, we use the Container Input (JSON) node to create the initial structure of the JSON body. There we add two placeholders, one for the questions and the other for the model, then set the max amount of tokens the answer can have to 100, and specify temperature = 0 to ensure the outputs are mostly deterministic.
In the “Question to JSON” metanode, we merge the Container Input (JSON) node with the output from the Top k Selector node by appending their columns. Missing values are handled by copying the initial JSON request body with the Missing Value node. The String Manipulation node is then used to replace the placeholders with the actual question and model selection in a new column. Finally, the String to JSON node converts this new column into the JSON format that will be used by the POST request. The body of our POST Request is ready and can be prompted to “text-davinci-003.”
From the general JSON request body (left) to the custom JSON request body that will be prompted to “text-davinci-003” (right).
As with prior API requests, the responses are received in JSON format and processed using the “Processing” metanode. The final step is to merge the table of answers (and questions) from StackOverflow and “text-davinci-003.” This combined table is then used as input to initiate an interactive Data App.
Now Explore the Results in a Data App
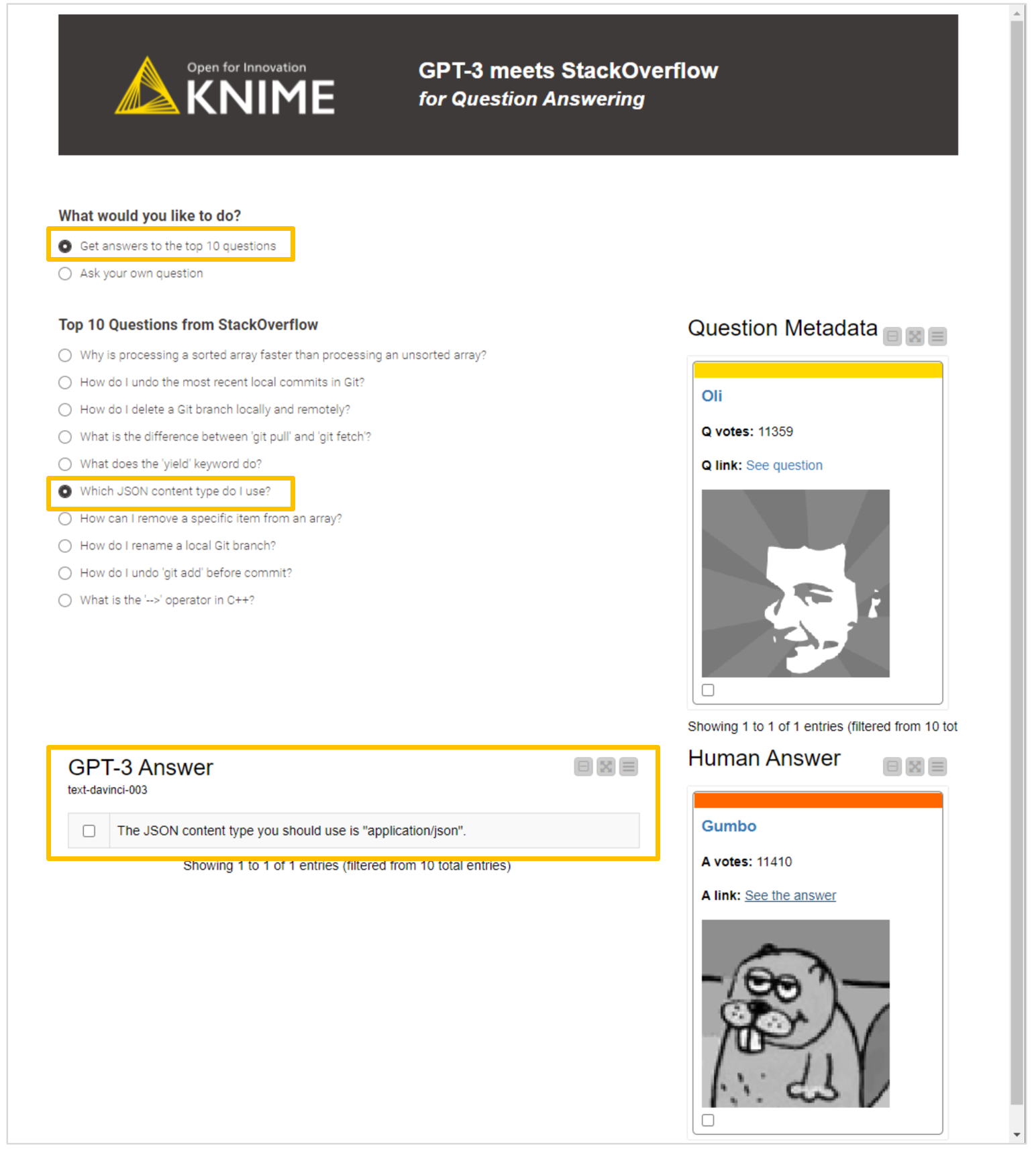
You can interact with our data app and explore the top 10 questions from StackOverflow. You can see meta-information about who asked the question, the number of votes received, and the question's full content. You can also access the answer provided by the machine – by “text-davinci-003,” and get the link to the best human answer, the number of upvotes, and the answerer’s profile.
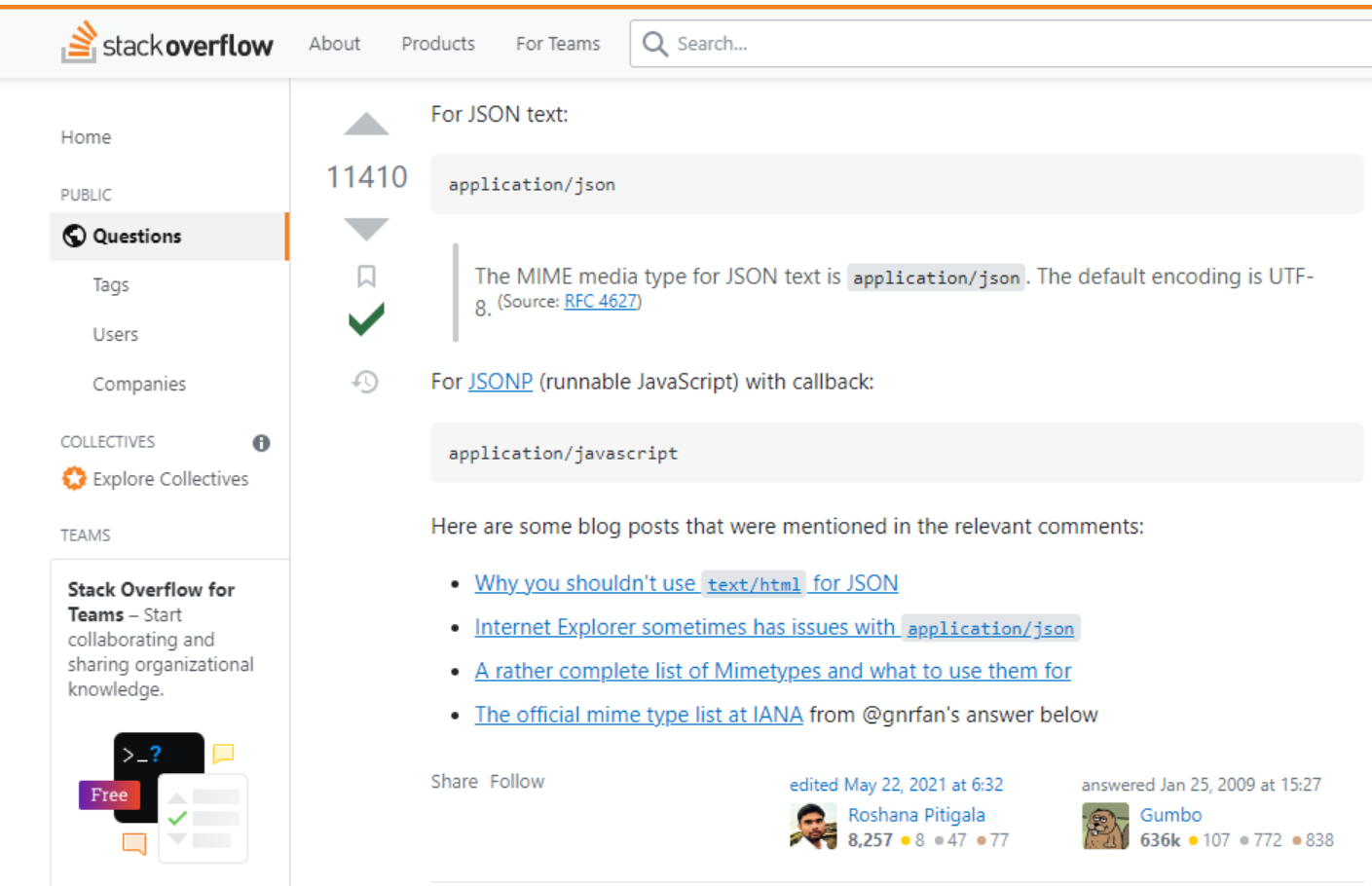
Let’s have a look at an example for the question: “Which JSON content type do I use?”, GPT-3 provides the correct answer in a concise and handy way, avoiding the verbosity of human answers. It is also worth considering that GPT-3 was fed solely with the question title.
The human answer is more in-depth, and provides additional resources or explanations. According to the user’s needs and through tweaking GPT-3’s max token parameter or prompt, comparable results might be achieved.
Ask GPT-3 Your Own Questions in the Data App
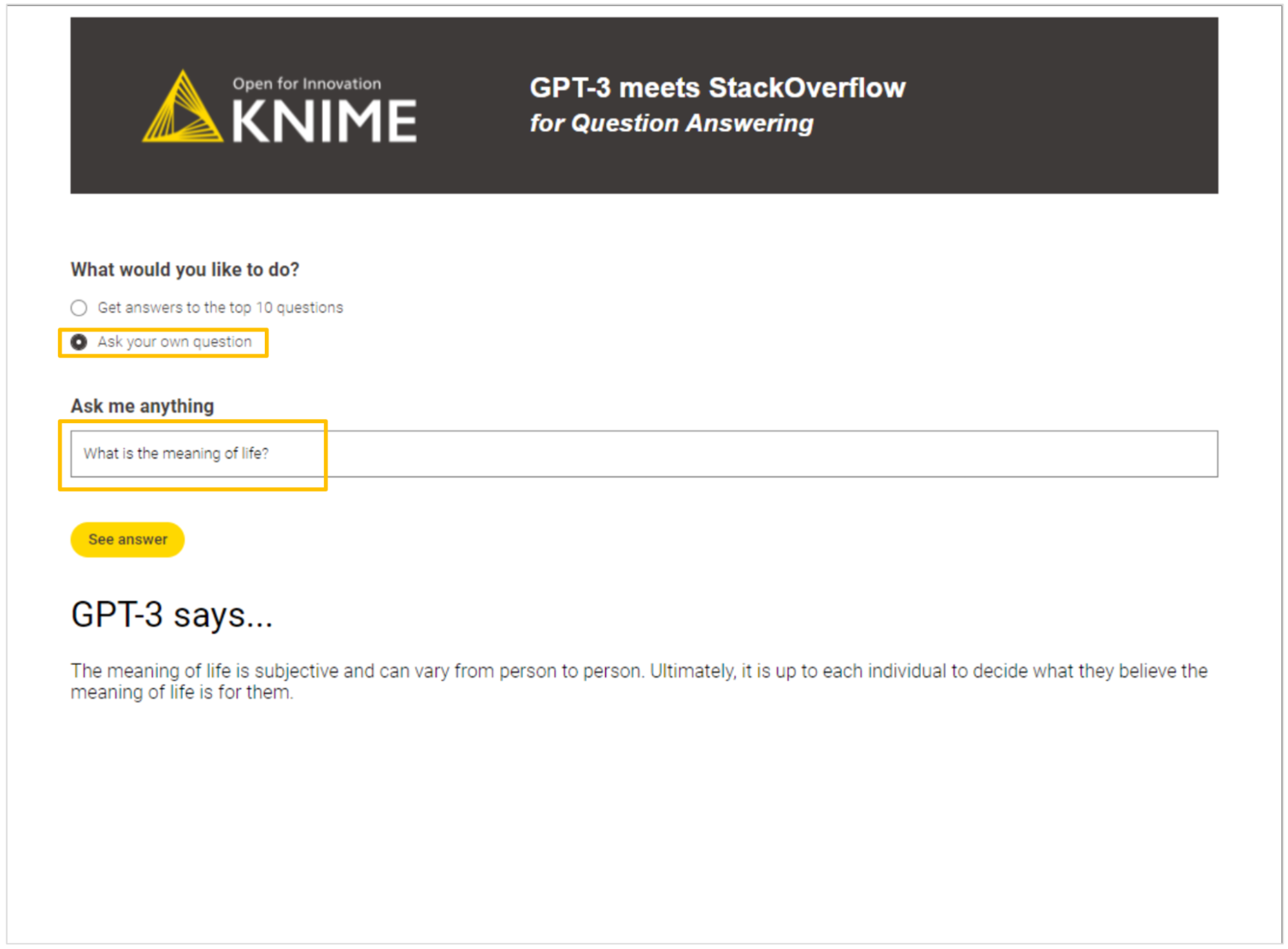
The second option enables users to pose their own questions, with the ability to request answers from the model by clicking the “See answer” button. For example, we asked GPT-3 about the meaning of life. While the answer does not contain any mind-blowing truth, it is definitely fair, and comparable to what an average human would probably answer.
Low-Code Makes Sophisticated Techniques Accessible to All
We’ve seen how to access, retrieve, and blend data and technologies from two APIs via the GET and POST Request nodes, all within KNIME’s intuitive low-code environment. Not only is the data flow easy to understand and communicate to stakeholders, but model selection, display or results and queries are easily customized to specific needs.
With the creation of the browser-based data app, you can put sophisticated analytics into the hands of an end user. The data app conceals the underlying complexity of how the questions and answers are sent and fetched from the APIs and allows the end user to easily interact and explore the human vs machine-generated answers.
Now gather your most pressing questions and pick GPT-3’s artificial mind about them. Download the example workflow, GPT-3 meets StackOverflow, adjust it to include your own credentials, and try it out.